前一段时间在廖雪峰老师的博客上跟着学了一遍python3,决定试着写一个简单的爬虫程序。工作中有同事问我喜马拉雅上的音频怎么下载,我都是让他们去到浏览区缓存文件夹里去找,改下后缀为mp3就可以播放了,这次写这个爬虫程序其实是为了解决上面的问题,给一个喜马拉雅上的专辑链接,可以把专辑里的音频全部下载到本地。
以前做过音箱的嵌入式网络开发,当时用的豆瓣电台,直接请求某个歌曲,返回的html页面中直接有音频源的地址,再去下载就ok了,但是喜马拉雅的专辑页面的html中除了歌曲id,看不到下载链接,为了找下载链接花了些功夫,下面讲下如何搞到下载链接。
例如我们要下载薛之谦的一个专辑:http://www.ximalaya.com/15794559/album/289316
在浏览器中查看该页面源码,并没有歌曲的下载链接,只有专辑中歌曲的sound id:
<li sound_id="25890774" class="">
<div class="miniPlayer3">
<a class="playBtn"></a>
<a class="title" href="/15794559/sound/25890774" hashlink title="黄色枫叶">
黄色枫叶
</a>在专辑页面打开浏览器的开发者模式,点击除了第一首之外的另一首歌,再点击播放按钮,发现有个json访问: 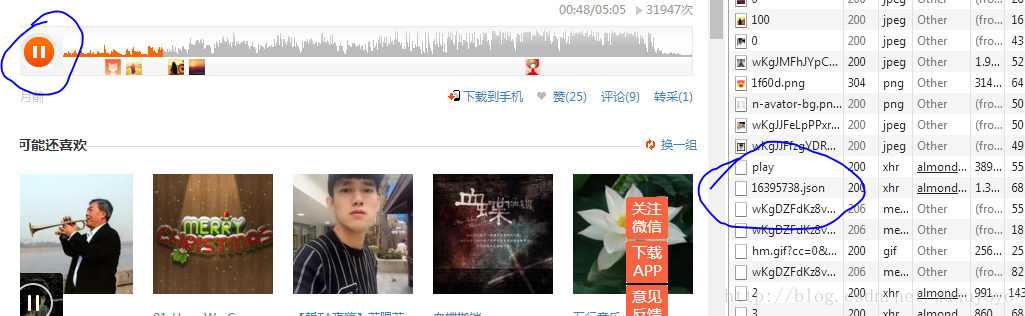
我们手动打开这个json访问地址,bingo,找到下载地址了!
大家可以试试:
http://www.ximalaya.com/tracks/25890774.json
"id":25890774,"play_path_64":"http://audio.xmcdn.com/group21/M03/6D/D0/wKgJLVg6oPuweFTLAB9ztmnU5ro958.m4a","play_path_32":"http://audio.xmcdn.com/group21/M03/6D/AC/wKgJKFg6oPeS2COzAAwI3QOZNsY252.m4a","play_path":"http://audio.xmcdn.com/group21/M03/6D/D0/wKgJLVg6oPuweFTLAB9ztmnU5ro958.m4a",概括下上面的过程:
1. 获得专辑的html页面,从页面中提取每个歌曲的sound id
2. 分别取出sound id,拼接处json访问的地址,访问json链接
3. 从返回的json字符串中获取音频地址,下载到本地
直接上代码:
from html.parser import HTMLParser
from urllib import request
import json
import os
import sys
import re
#提取sound id,提取专辑名称用于创建该专辑文件夹
class AlbumEventHtmlParser(HTMLParser):
sound_ids = []
album_title = "";
title_flag = False
def __init__(self):
HTMLParser.__init__(self)
self.sound_ids = []
self.album_title = ""
def handle_starttag(self, tag, attrs):
if tag == 'li':
for name, value in attrs:
if name == 'sound_id':
self.sound_ids.append(value)
if tag == 'title':
self.title_flag = True
def handle_data(self, data):
if self.title_flag:
rstr_list = re.findall(r"【(.*)】", data)
self.album_title = rstr_list[0]
print(self.album_title)
self.title_flag = False
def parse_python_events():
album_addrs = []
album_folder = ""
#本地文件存储专辑链接地址,可以一次下载多个专辑
with open('albumaddr.txt','r') as addr_file:
album_addrs = addr_file.readlines()
for addr in album_addrs:
sound_ids = []
parser = AlbumEventHtmlParser()
with request.urlopen(addr) as album_file:
html = album_file.read().decode('utf-8')
parser.feed(html)
sound_ids = parser.sound_ids;
if len(sound_ids)>0:
album_folder = parser.album_title;
if not os.path.exists(os.curdir + '/' + album_folder):
os.mkdir(os.curdir + '/' + album_folder)
else:
print("You have already downloaded the album: %s" % album_folder)
continue
else:
print("There is no sound: %s" % addr)
continue
for sound_id in sound_ids:
with request.urlopen(('http://www.ximalaya.com/tracks/' + sound_id + '.json')) as music_f:
music_json = json.loads(music_f.read().decode('utf-8'))
print(music_json['title']+'downloding...')
request.urlretrieve(music_json['play_path'], './' + album_folder + '/' + music_json['title'] + '.mp3')
print(music_json['title']+'downloaded')
parse_python_events()版权声明:本文为xuxuyoyo原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。