循环神经网络文本分类
原理讲解
TextRNN相关论文:Recurrent Neural Network for Text Classification with Multi-Task Learning
本文实现
TextRNN 的网络结构: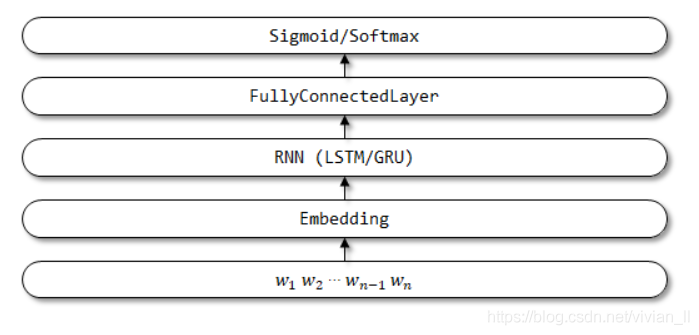
基于keras,在代码上的实现和textCNN类似。
定义textRNN网络结构
和textCNN唯一的区别在于get_model函数。
from tensorflow.keras import Input, Model
from tensorflow.keras.layers import Embedding, Dense, Dropout, LSTM
class TextRNN(object):
def __init__(self, maxlen, max_features, embedding_dims,
class_num=5,
last_activation='softmax'):
self.maxlen = maxlen
self.max_features = max_features
self.embedding_dims = embedding_dims
self.class_num = class_num
self.last_activation = last_activation
def get_model(self):
input = Input((self.maxlen,))
embedding = Embedding(self.max_features, self.embedding_dims, input_length=self.maxlen)(input)
x = LSTM(128)(embedding)
output = Dense(self.class_num, activation=self.last_activation)(x)
model = Model(inputs=input, outputs=output)
return model
定义textBiRNN网络结构
唯一的区别在于LSTM层变为双向。
from tensorflow.keras import Input, Model
from tensorflow.keras.layers import Embedding, Dense, Dropout, Bidirectional, LSTM
class TextBiRNN(object):
def __init__(self, maxlen, max_features, embedding_dims,
class_num=5,
last_activation='softmax'):
self.maxlen = maxlen
self.max_features = max_features
self.embedding_dims = embedding_dims
self.class_num = class_num
self.last_activation = last_activation
def get_model(self):
input = Input((self.maxlen,))
embedding = Embedding(self.max_features, self.embedding_dims, input_length=self.maxlen)(input)
#x = Bidirectional(CuDNNLSTM(128))(embedding)
x = Bidirectional(LSTM(128))(embedding)
output = Dense(self.class_num, activation=self.last_activation)(x)
model = Model(inputs=input, outputs=output)
return model
预处理和训练
后面的部分和textCNN基本相同。
from tensorflow.keras.preprocessing import sequence
import random
from sklearn.model_selection import train_test_split
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.utils import to_categorical
from utils import *
# 路径等配置
data_dir = "./processed_data"
vocab_file = "./vocab/vocab.txt"
vocab_size = 40000
# 神经网络配置
max_features = 40001
maxlen = 400
batch_size = 64
embedding_dims = 50
epochs = 10
print('数据预处理与加载数据...')
# 如果不存在词汇表,重建
if not os.path.exists(vocab_file):
build_vocab(data_dir, vocab_file, vocab_size)
# 获得 词汇/类别 与id映射字典
categories, cat_to_id = read_category()
words, word_to_id = read_vocab(vocab_file)
# 全部数据
x, y = read_files(data_dir)
data = list(zip(x,y))
del x,y
# 乱序
random.shuffle(data)
# 切分训练集和测试集
train_data, test_data = train_test_split(data)
# 对文本的词id和类别id进行编码
x_train = encode_sentences([content[0] for content in train_data], word_to_id)
y_train = to_categorical(encode_cate([content[1] for content in train_data], cat_to_id)) # keras多分类需要对y用to_categorical做one-hot
x_test = encode_sentences([content[0] for content in test_data], word_to_id)
y_test = to_categorical(encode_cate([content[1] for content in test_data], cat_to_id))
print('对序列做padding,保证是 samples*timestep 的维度')
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
print('构建模型...')
model = TextRNN(maxlen, max_features, embedding_dims).get_model()
model.compile('adam', 'categorical_crossentropy', metrics=['accuracy'])
print('Train...')
early_stopping = EarlyStopping(monitor='val_accuracy', patience=2, mode='max')
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
callbacks=[early_stopping],
validation_data=(x_test, y_test))
print('Test...')
result = model.predict(x_test)
画图
import matplotlib.pyplot as plt
plt.switch_backend('agg')
%matplotlib inline
fig1 = plt.figure()
plt.plot(history.history['loss'],'r',linewidth=3.0)
plt.plot(history.history['val_loss'],'b',linewidth=3.0)
plt.legend(['Training loss', 'Validation Loss'],fontsize=18)
plt.xlabel('Epochs ',fontsize=16)
plt.ylabel('Loss',fontsize=16)
plt.title('Loss Curves :CNN',fontsize=16)
fig1.savefig('loss_cnn.png')
plt.show()
fig2=plt.figure()
plt.plot(history.history['accuracy'],'r',linewidth=3.0)
plt.plot(history.history['val_accuracy'],'b',linewidth=3.0)
plt.legend(['Training Accuracy', 'Validation Accuracy'],fontsize=18)
plt.xlabel('Epochs ',fontsize=16)
plt.ylabel('Accuracy',fontsize=16)
plt.title('Accuracy Curves : CNN',fontsize=16)
fig2.savefig('accuracy_cnn.png')
plt.show()
模型结构
from tensorflow.keras.utils import plot_model
# model.summary()
plot_model(model, show_shapes=True, show_layer_names=True)
注意:Windows平台下和textCNN一样需要注意utils.py的read_single_file函数分隔符问题。因为keras版本不同的修改见上一篇textCNN。
版权声明:本文为vivian_ll原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。