1、编写jmeter脚本的方式
1) badboy 录制
2)jmeter 自带的录制控制器
3) 手写脚本
2、手动编写jmeter 性能测试脚本
性能测试三要素:接口测试、真实场景、多线程
2.1 使用jmeter 完成接口测试
接口测试的工具:postman、fiddler、python+requests、jmeter
断言:
响应断言:相等断言、包含断言、子字符串、匹配断言(正则表达式断言)
JSON 断言:返回值是json格式,其中相等断言和正则匹配断言 -----$.[0].unitprice
大小断言:用于验证是否有返回值,或者用于文件、图片大小验证
断言持续时间:用于验证响应返回的时间是否在一定的范围内,单位ms
BeanShell 断言:自定义断言,当现有的断言方式都不能满足要求,使用java 自己编写
HTTP Cookie 管理器—保持登录
1)动态保持—必须添加登录请求并且登录成功
2)静态保持–从浏览器或者接口获取静态cookie信息
使用Jmeter 做接口测试需要用到的元器件有哪些?
取样器(采样器)
断言
查看结果树
HTTP Cookie管理器—静态、动态
作业:使用jmeter 完成agileone 系统 公告新增接口的测试,测试用例5条
2.2 使用jmeter 模拟用户真实场景
数据真实
性能测试中实现参数离散化(接口测试称为ddt)的三种方式
1)用户参数–前置处理器
只能给某一个请求添加,作用范围-局部范围,能够添加有限数量的数据组,适用于数据量比较少
2)用户定义的变量–配置元件
全局作用,每一只能添加一组数据,适合做配置
3)CSV 文件配置—配置元件,支持.txt 和.csv(excel另存为)
全局作用,可以批量导入数据,数据从数据库导出、爬虫爬取
问题:三种参数化方式,优先级别如何?
用户参数>CSV 数据文件配置>用户定义的变量
练习:蜗牛进销存v1.3 条件查询接口
操作逻辑真实-用户的操作顺序、操作链路
场景一:用户去登录蜗牛进销存,首先进入首页–》输用户名密码,点击登录–》进入主页,站在用户的角度,这三个操作是一个整体,三个都成功则用户认为登录成功,否则就是登录失败
解决方案:事务控制器
事务的概念:性能测试工程师站在用户的角度来定义的
场景二:某些场景,比如蜗牛进销存的会员新增接口只有在用户登录成功的基础上才能操作,登录失败操作不了
step1 : login_res = 登录接口响应正文—login-pass -------提取登录的响应正文,保存到jmeter 变量池----正则表达式提取器
step2: if login_res == login-pass: -------判断是否等于login-pass----IF 控制器
do 新增
解决方案:IF 控制器
正则表达式提取器使用:
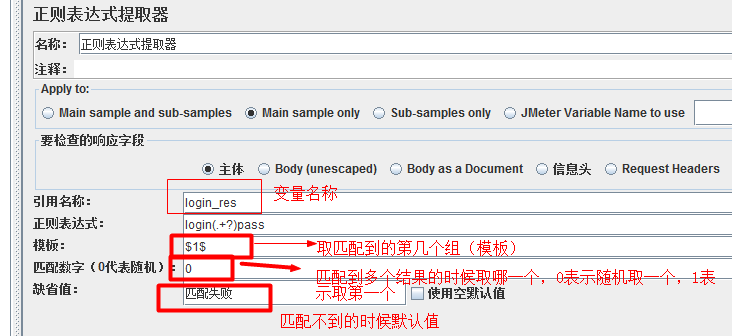
子表达式的使用:根据字符串左右的字符串来匹配,返回匹配到的值
例子:匹配login-pass中的-----login(.+?)pass
场景三:用户进入某个系统,只需要登录一次,但是却多次其他操作,比如登入淘宝搜索商品
解决方案:仅一次控制器
场景四:用户进入某个系统以后,可能会进行多次不同的操作
例子:用户进入蜗牛进销存,进行5次查询,3次扫码,1次新增;
用户的访问量 为 查询:扫码:新增 =5:3:2
解决方案:吞吐量控制器
其他:随机控制器:用户多选一,每次选一个操作,例子:用户注册选择身份,要么选择称为卖家、要么选择成为买家
随机顺序控制器:控制顺序
思考时间真实
固定定时器:固定延时,比如获取验证码
高斯随机定时器:产生时间范围是固定延时±偏移
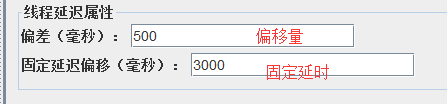
统一随机定时器:产生的范围是随机值+偏移

同步定时器:集合点-----用来模拟秒杀
模拟并发–狭义的并发
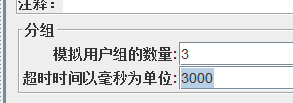
模拟的用户组:模拟多少个用户一起向服务器发出请求
超时时间:0表示死等,一直等,3000表示等3秒,如果3秒内都凑不足3个线程,那3秒后就直接发出请求
并发概念:
狭义的并发:在某一个时刻同时向系统的某一个接口发起访问
广义的并发:在一个时间段内向某个系统的某些接口发起访问
性能测试中的并发是指广义的并发
2.3 多线程–并发数设置
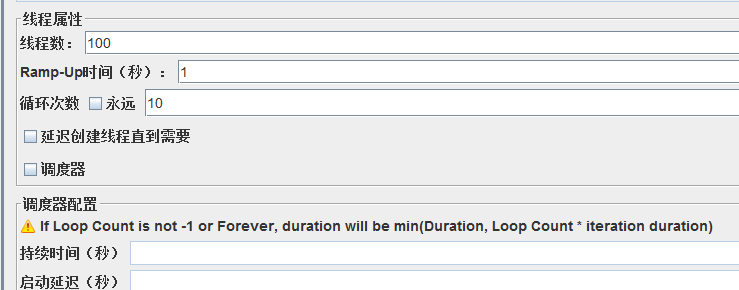
线程数:虚拟用户数(VU)—模拟的并发用户数
Ramp-up:上升时间,用1s的时间去加载100个线程
循环次数:10就是循环10次,永远就是死循环(-1)
调度器:必须和死循环配合使用
持续时间:让jmeter 保持当前设置的压力,持续向服务器发出请求的时间-------压测时间
一般设置为5min(300s),10min(600s),30min
启动延迟:延迟多少时间开始产生压力
3.性能测试指标
资源利用率
CPU:
CPU 跑满:安全临界值 70%-80%
CPU 真的满了:100%或者接近100%
内存:
剩余内存:>5%
使用内存:<95%
磁盘:
已使用磁盘:<95%
剩余磁盘:
网络(带宽):
100M 宽带
100 M bit/s /8 = 12.5 M Byte/s
8bit = 1byte(字节)
上行:上传
下行:下载 10M ,实际可能只有4-5M
响应时间
RT = T1+…+T7
业界指标:2/5/8 s 1/3/5s
业务指标: 阿里: 单接口200ms 页面:1s ZBJ:单接口500ms 页面:5s
通常指的是平均响应时间,也可能是90%百分数响应时间
吞吐率—衡量服务器的处理能力
服务器单位时间内处理的事务数–TPS(每秒处理的事务数)
一个事务里面有几个请求?----->=1个
一个事务里面只有一个请求 TPS = QPS(每秒处理的查询数、每秒处理的请求数)
标准:越多越好,不能是个位数,同时应该满足一定的规律(TPS负载曲线)
业务吞吐率:登录事务数/s 、处理订单数/min、处理的交易数/s
网络吞吐率: 上传字节数/s(上行速率)、下载字节数/s(下行速率)
事务通过率
单位时间内通过的请求数/总的请求数
业界标准:一般业务 >95% ,核心业务、金融相关>98%
业务标准:一般业务> 98% ,核心业务、金融相关的>99.9%
用户最关心:事务通过率>RT
开发团队关心:资源利用率、吞吐率
4.性能测试指标监控
RT监控

90% 百分位:
90%用户的响应时间是14ms ----------- ×
90%用户的响应时间在14ms 以内------×
90% 的请求数的响应时间在14ms 以内-----√
吞吐率:
聚合报告–吞吐量
事务通过率:
聚合报告
事务通过率=1-异常率
资源利用率:
CPU\内存----服务器的资源使用情况
ServerAgent -----安装在服务器上,负责服务器资源数据的采集和回传
PMC------安装在Jmeter 上面
PMC-jmeter 插件
jmeter 插件安装:
step 1:去网站下载对应的插件安装包—百度搜索,栗子:插件管理器-jmeter-plugins-manager-1.3.jar
step 2 :把安装包放到 apache-jmeter-5.1\lib\ext 目录下
step 3: 重启jmeter
step 4:打开jmete人,选项–》Plugins Managers
ServerAgent 监控器的使用:
1)在服务器上打开serverAgent 里面的StartAgent.bat(windows)
- 在jmeter 里面添加PMC 插件
作业:蜗牛进销存条件查询接口 100个线程压测10分钟,记录指标4个指标数据,截图保存结果,报错截图保存
5.TPS 负载曲线
资源负载曲线
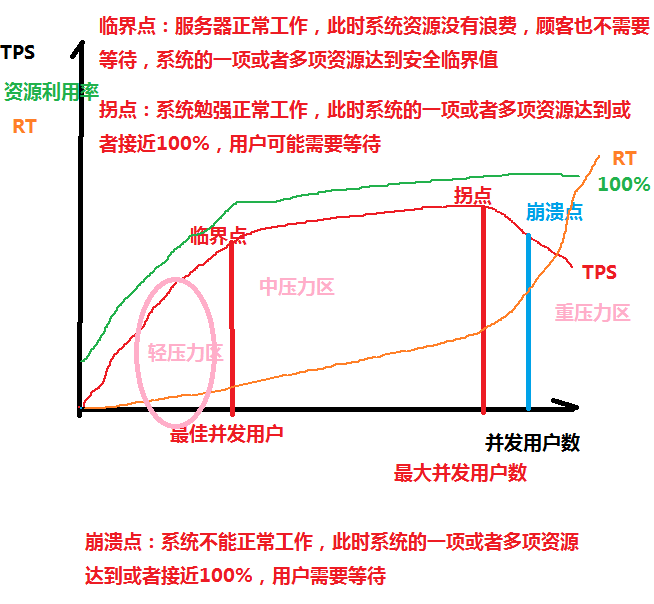
报错解决:
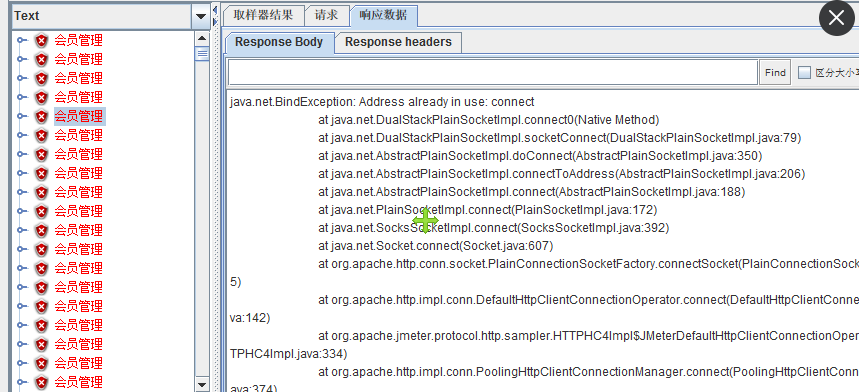
本地端口数默认是16384个
16384-2000左右(80、8080、443)约=16000
开始报错的时候,使用命令 >netstat -ano | find “TIME_WAIT” /c 去查询当时处于回收状态的端口数数量,如果这个数量接近16000,那就是本地端口耗尽,意味着负载机不能发出更多的请求了
解决方案:
1、jmeter 里面使用短连接—去掉keep alive 的勾勾
2、增加本地端口数
a、查询本地开启端口数量:netsh int ipv4 show dynamicportrange tcp
本地总的可用端口数是65536个,默认情况只开出了16384个
b、设置本地端口数,起始端口为2000,总共设置63000个:
netsh int ipv4 set dynamicport tcp start=2000 num=63000
c、regedit打开注册表,修改端口回收的时间
- HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters
- “MaxUserPort”=dword:0000fffe
- “TcpTimeWaitDelay”=dword:0000005 (缩短为5秒)
单机负载受限:
1)能够启动的线程数有限
假如负载机1000个线程,服务器最优在10000左右
2)jmeter 卡死–重启jmeter,修改配置后重启
修改了堆内存以后仍然出现这种情况
6 性能测试的策略(性能测试的分类)
负载测试
概念:在一定的软件、硬件及网络环境下,产生不同的负载数向发起请求,观察服务器的各项指标能否达标,同时找出服务器能够承受的最优和最大负载数
产生不同的负载数:产生不同的并发数,一般来说是3组不同的并发数,在最优附近找三组、在实际负载数附近找三组
例子:假如最优是1500,三组可以定为1300,1500,1700
7 5,7,9
能否达标:能否满足需求方的要求
找最优最大:梯度加压器
步骤:
1、找最优最大 —使用梯度加压器—注意需要截图保存
最优538
2、使用普通线程组
在最优附近找3组: 500,538,570
压力测试:
概念:在一定的软件、硬件及网络环境下,模拟一定的负载数使服务器(系统)长时间工作在极限情况下,观察系统能否正常工作,以及不能正常工作时的表现
一定的负载数:负载数固定在某一个值,一般固定在系统的最优并发、最大并发或者实际并发附近
最优并发、实际并发:稳定性压力测试
最大并发:破坏性压力测试、崩溃性压力测试
长时间:12h*n,一般是2天,7天,15天
极限情况:系统的最优、最大 ,或者是系统的实际最大并发
目的:找出系统的瓶颈(系统可能出现的问题),突破和预防
容量测试—关注的是数据量
概念:在一定的软件、硬件及网络环境下,模拟一定的负载数对服务器发起不同级别的数据量请求,观察系统的各项指标能否达标
不同级别:不同的数据量级别,向服务器请求的数据条数级别,例子:100个虚拟用户,每次请求100条,每次请求1000条,10000条,10w,100w
基准测试
概念:在一定的软件、硬件及网络环境下,模拟一定的用户数向服务器发起请求,并且与已有的基准版本比较,观察系统的各项指标能否达标
例子:蜗牛进销存v1.3—扫码接口,测试标准RT --2s
蜗牛进销存v1.4—优化扫码接口,测试标准要求比v1.3 RT 提高50%----1s
配置测试
概念:在不同的软件、硬件及网络环境下,修改不同的配置,观察服务器的各项指标是否达标,并且从中找出最优配置
例子:tomcat8,tomcat9
补充:
JSON 提取器,
格式:$.[下标].键名
总结:
问:jmeter 中遇到有关联的接口怎么处理?
答:使用正则表达式或者JSON 提取器去提取上一个接口(被依赖接口)的输出 供当前接口的输入用
例子:支付接口 依赖 下单接口
BeanShell 控制器
KaTeX parse error: Expected group after '_' at position 2: {_̲_BeanShell({uprice} * KaTeX parse error: Expected 'EOF', got '}' at position 18: …iscount} /100,)}̲-------------{uprice} * ${discount} /100
KaTeX parse error: Expected group after '_' at position 2: {_̲_BeanShell((int…{uprice} * KaTeX parse error: Expected 'EOF', got '}' at position 18: …iscount} /100,)}̲----取整------(in…{uprice} * ${discount} /100
7 线程数设置
问题:你们平时都是怎么做性能测试的呢?–流程
你们线程数怎么设置呢?
你们并发数怎么设置呢?
你们怎么做负载测试呢?
负载测试流程:
- 找最优最大
2)在最优附近找三组
3)记录数据
项目已上线—现网有运行—有访问量数据
访问量数据:
1) 公司数据部统计–公司数据部
2)产品有埋点数据统计–产品
3)服务器访问日志—access_log—运维(开发)
蜗牛进销存,下单支付接口每日访问量为50w,访问时间段为9:00-18:00
(一)访问量程均匀分布(平稳分布)—均分
1、计算10min 以内的流量
50w /9h /6 = 9259/10min
2、jmeter 里面设置 10线程试跑 10min ,得到被测接口(事务)访问量—5000
3、 等比换算
10min 10 线程 5000访问量
10min ? 9259 访问量
10/? = 5000/9259 —> ?=10 * 9259 / 5000 = 18 线程
4、留有阈度–20%
jmeter 设置线程数 x = 18*20% +18 = 18 * 120% =22 线程
5、最后jmeter 设置22 线程,测试10min,观察聚合报告最终的访问量是否达到目标访问量–9259,如果没有达到,继续加线程,直到达到为止
(二) 访问量分布不均匀,有明显的波峰波谷—二八分
二八分:80% 的流量集中在20% 的访问时间段内
1、计算10min 内的流量
50w----9h----------------50w * 80% / (9h * 20%) /6 = 37000 / 10min
2、jmeter 试跑,10线程跑0min,得到访问量为5000
3、等比换算
10min 10线程 5000访问量
10min ?线程 37000 访问量
?=74
4、留有阈度–0%
74*1.2 = 88 线程
5、jmeter 设置 88线程跑10分钟,观察jmeter 聚合报告里面的访问量是否达到目标访问量-- 37000 ,如果没有达到,继续加线程,直到达到为止
问题:某个系统,一个礼拜内 搜索:支付:个人中心总的访问量为500w,其中 搜索:支付:个人中心 访问量比例为 6:1:3,现在要对搜索进行负载测试
500w/7 ----1天
均分:500w*0.6 /7 /12 h/6
二八分:500w0.6 * 0.8 / (7 12h * 6 * 0.2)
项目未上线(新项目)–没有访问数据
1) 参照同类项目
2)根据产品面向的人群来建立用户行为模型,估算访问高峰
3)需求方产品立项时设定的目标
一般项目在立项的时候会设置一个目标,比如本次项目的注册用户人数达到3000w ,
用户:
- 注册用户
- 在线用户
- 登录用户
- 活跃用户----真正对系统产生压力的用户群体
注册用户 * 5%~8% -------并发用户
4)找最优最大,在最优附近找三组进行负载测试,或者在最优附近进行压力测试
你在没有任何帮助的情况下,怎么做性能测试?
8 linux 系统指标监控
windows 资源利用率监控:
- 任务管理器
- Server Agent + PMC
Linux 资源利用率监控:
- Server Agent + PMC -----需要java 环境,需要yum install unzip -y ,yum install -y lrzsz
- 使用linux 命令来监控
- 使用NMON 工具来监控
使用Linux 命令来监控服务器的CPU 和内存
CPU:
CPU 利用率:统计时间段内使用CPU的时间/统计总时长—70%-80%
CPU 队列长度:当前线程池(进程池)中等待CPU的线程(进程)和正在使用CPU的线程(进程)数—不大于2倍CPU核心数
以上两个指标,如果有一个超标了,我们就认为CPU 可能不够用了

us:用户进程使用CPU的百分比—tomcat-蜗牛进销存 <50%
sy:系统进程使用CPU的百分比—20%-30%
id:空闲进程使用CPU的百分比 —表征CPU是否闲着,越大越闲
wa:需要等待IO的进程使用CPU的百分比—表征的是磁盘IO读写受限
备注:按1 可以查看各个CPU的执行情况
LINUX 下面CPU、核心数查找
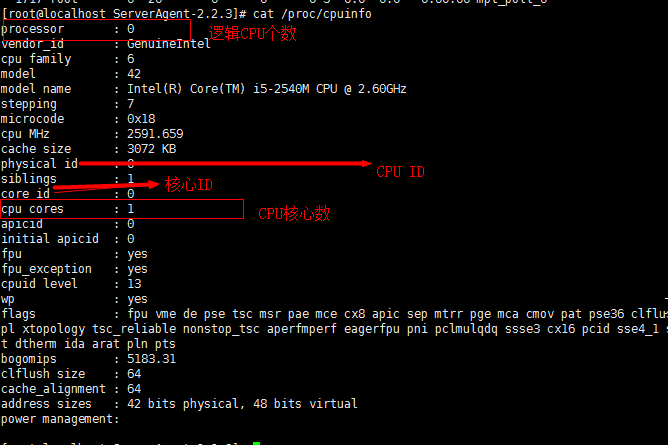
CPU 队列长度:

最近5min,10min,15min CPU的平均负载
例子:当前电脑配置1核,如果CPU 的load average 最近半小时都是2以上,那说明CPU 不够用了
CPU监控命令:top
内存:物理内存+交换分区
剩余内存:

Mem(Memary):物理内存 总的物理内存 剩余的物理内存 已使用的物理内存 用于缓冲缓存的物理内存
Swap:交换分区 总的交换分区 剩余的交换分区 已使用的… 可用的物理内存
物理内存的used:内核分配出去的内存,指应用正在使用的和已经使用过但是当前已经不用的
物理内存free:是指没有分配出去的
判断LINux 内存是否够用:
1)判断已使用的物理内存used 很大,接近用完
2)swap used 很大,接近用完
3)si/so 换入换出速度长期不为0
内存的监控命令:top+vmstat \free -h + vmstat
磁盘:
剩余磁盘:df -h
磁盘队列长度:正在使用磁盘IO和等待使用磁盘IO 的进程数(线程数),个位数就是没问题

监控命令:vmstat 里面的b这一例
NMON监控
分为两部分
1) 监控采集数据部分–tar 包
2)分析部分–提供图表展示
NMON 工具安装:
1) 创建一个目录 mkdir nmon57
2)将nmon tar 包拖进目录里面
3)解压tar 包 tar -zxvf tar包名
4)检查解压文件的权限,是否可执行 chmod -R 777 文件名
5)进入到解压文件夹,启动NMON监控 ./nmon_x86_64_sles11
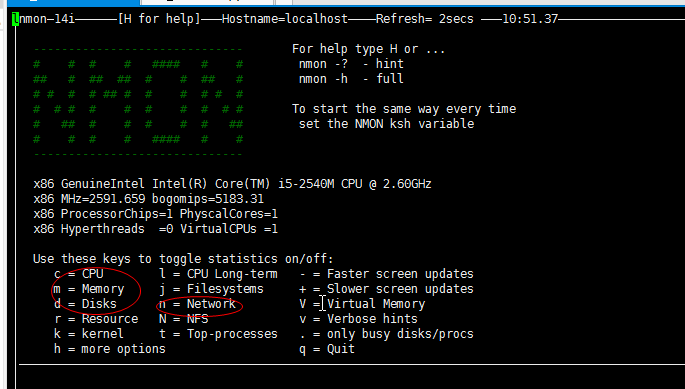
6)数据采集
./nmon_x86_64_sles11 -c30 -s2 -f -m /home/nmon57/
./nmon_x86_64_sles11:启动nmon 监控
-c30:采集30次 -c 30
-s2:每两秒采集一次 -s 2
-f:指定输出的格式为标准格式
-m:指定采集到数据文件保存的位置
7)保存采集到的数据到本地 sz 数据文件名
8)分析,使用分析工具打开分析
注意:1) 需要启用宏
2) 分析报错,windows 右下角修改日期格式,修改完成以后去linux里面重新采集数据导出打开分析
-h
磁盘队列长度:正在使用磁盘IO和等待使用磁盘IO 的进程数(线程数),个位数就是没问题
[外链图片转存中…(img-AzENpJVi-1624335482861)]
监控命令:vmstat 里面的b这一例
NMON监控
分为两部分
1) 监控采集数据部分–tar 包
2)分析部分–提供图表展示
NMON 工具安装:
1) 创建一个目录 mkdir nmon57
2)将nmon tar 包拖进目录里面
3)解压tar 包 tar -zxvf tar包名
4)检查解压文件的权限,是否可执行 chmod -R 777 文件名
5)进入到解压文件夹,启动NMON监控 ./nmon_x86_64_sles11
[外链图片转存中…(img-HeGnSy12-1624335482863)]
6)数据采集
./nmon_x86_64_sles11 -c30 -s2 -f -m /home/nmon57/
./nmon_x86_64_sles11:启动nmon 监控
-c30:采集30次 -c 30
-s2:每两秒采集一次 -s 2
-f:指定输出的格式为标准格式
-m:指定采集到数据文件保存的位置
7)保存采集到的数据到本地 sz 数据文件名
8)分析,使用分析工具打开分析
注意:1) 需要启用宏
2) 分析报错,windows 右下角修改日期格式,修改完成以后去linux里面重新采集数据导出打开分析
[外链图片转存中…(img-pVpGvgf5-1624335482864)]