百度半天,找到了两种方式
添加VM选项
首先命令行输入chcp查看系统默认编码格式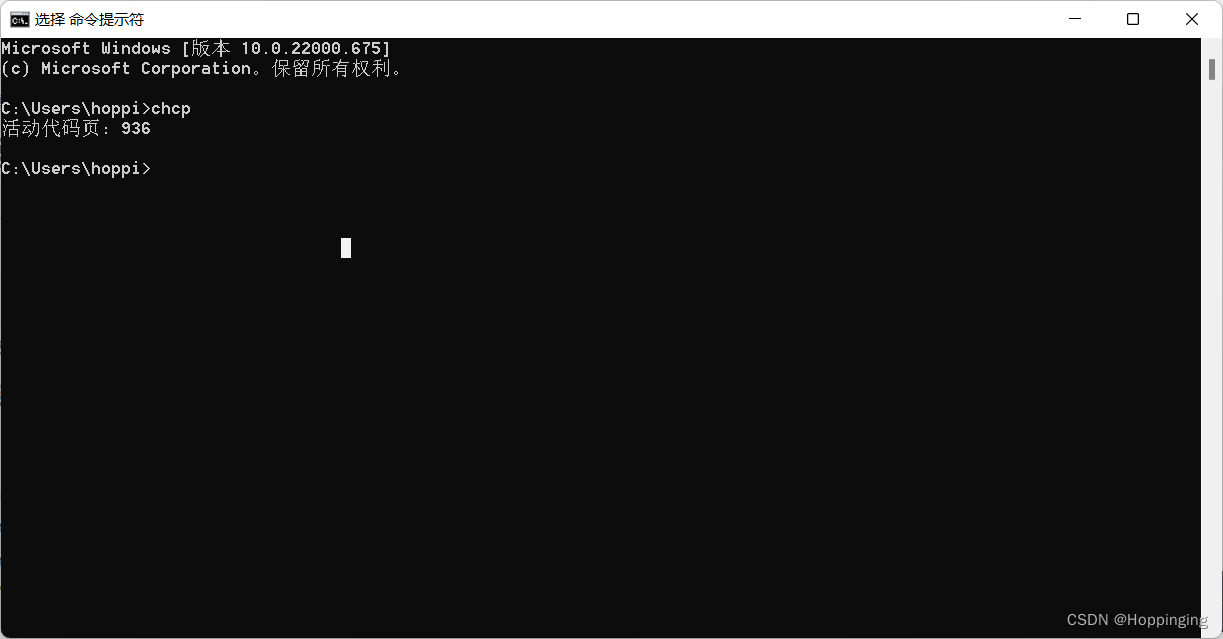
那么我电脑的默认编码格式就是cp936
运行配置中加上VM选项-Dfile.encoding="cp936"
就可以解决问题
cp936也可以换成GBK(cp936其实就是GBK)
转码
查看系统默认编码格式和上面一样
接下来把抓到的数据编码格式转换成cp936
String html = new String(driver.getPageSource().getBytes(StandardCharsets.UTF_8), "cp936");
但这种方法有时会出问题,比如
这里的请输入ID�?就非常神秘,明明下面的冒号是可以被解析的
太怪了 建议用添加VM选项的方法
版权声明:本文为Hoppinging原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。