NoSQL概述
发展历程
1、单机MySQL的年代
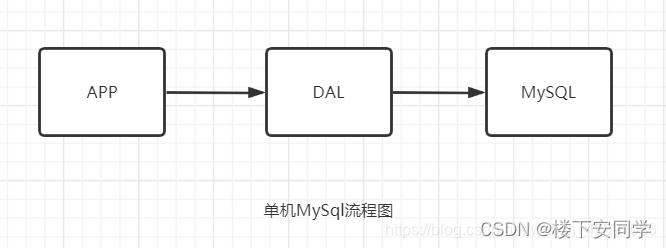
网站发展之初,网站的访问量基本不会太大,单个数据库完全足够,那个时候基本都是静态网页HTML服务器没有压力。
数据量如果太大,一个机器放不下了,B+Tree(索引也放不下了),访问量太大,一个服务器承受不了,只要出现以上三种情况,必须要晋级。
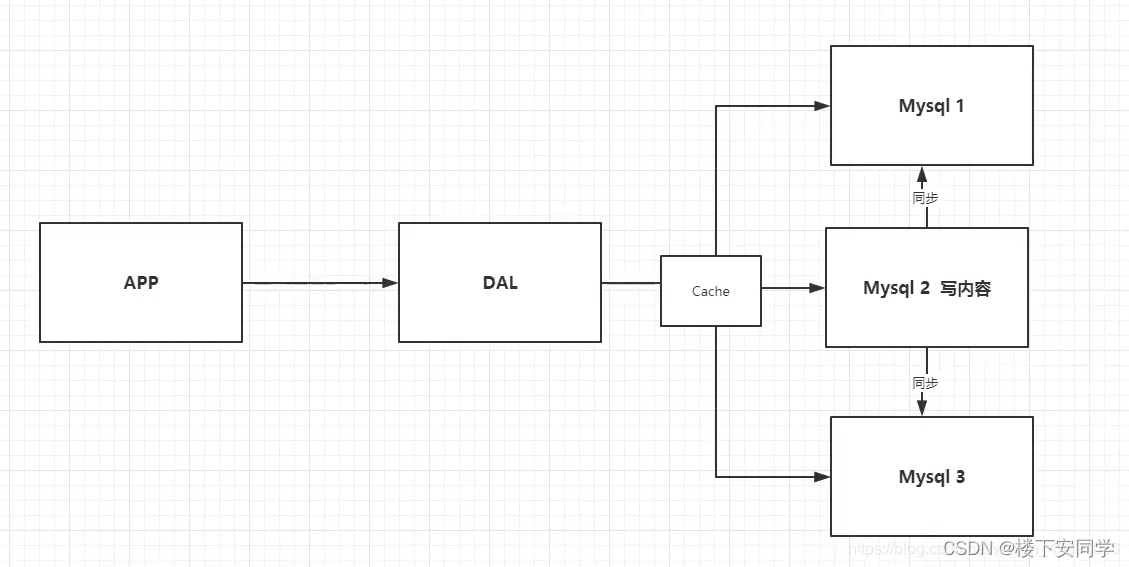
2、Memcached(缓存)+ MySQl+垂直拆分(读写分离)
网站80%的情况都在读,每次查询的时候特别麻烦,所以使用缓存来保证
效率!
发展过程: 优化数据结构和索引 -->问件索引(IO) --> Memcached
3、分库分表 + 水平拆分 + MySQl集群
技术发展的过程中,对人的要求提高了,以前的mysql被替换成了
MySQL集群。
本质:数据库(读写)
MyISAM -->表锁
Innodb -->行锁
现在:分库分表解决写的压力
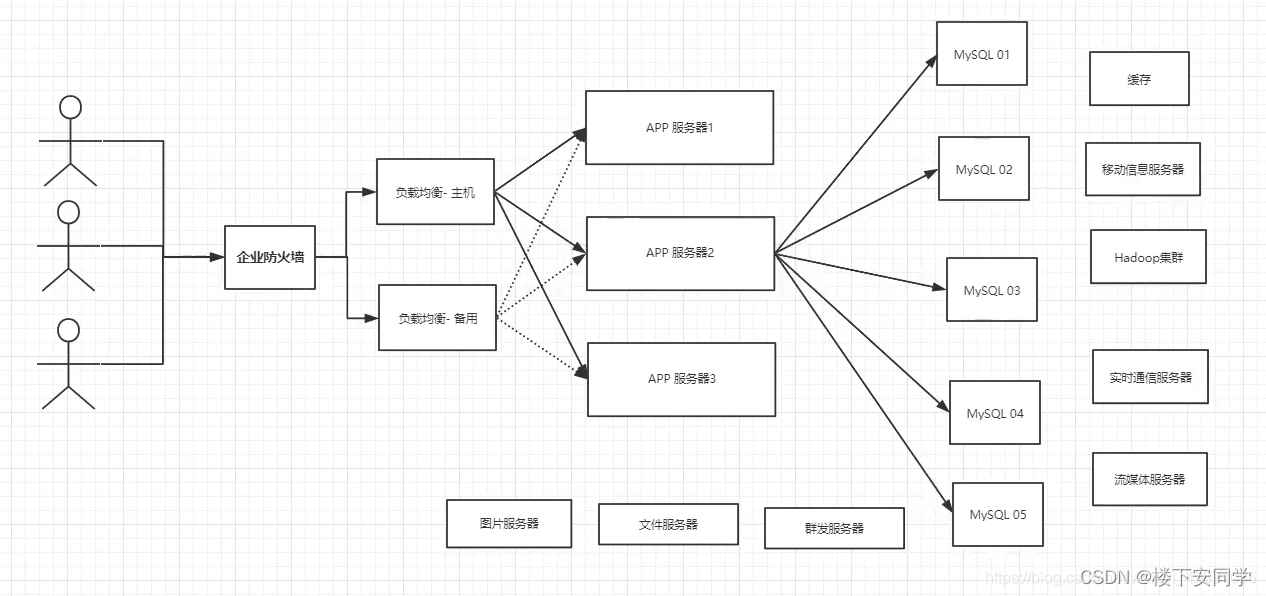
4、当今的年代
2010 ---- 2020,技术爆炸,mysql等关系型数据库就不够用了,数据量大,变化快!
使用专门的数据库来处理文件,图片,博客,等较大的文件,减小MySQL的压力。
5、目前基本的网站模型
为什么要用NoSQL
用户的个人信息,社交网络,地理位置等,数据爆发增长。
这个时候我们就要使用NoSQL数据库的,NoSQL可以很好地处理以上情况!
什么是NoSQL
NoSQL = Not Only SQL (不仅仅是SQL) 泛指非关系型数据库
关系型数据库:表格,行,列
NoSQl在当今大数据环境下发展的十分迅速,Redis是发展最快的,我们必须掌握!
很多的数据类型用户的个人信息,社交网络,地理位置,这些数据类型的长处不需要一个固定的格式,不需要多余的操作就可以横行扩展的!
1、NoSQl特点
解耦!!!
方便扩展(数据之间没有关系,很好扩展)
大数据量,高性能(Redis一秒写8W次,读取11万)
数据类型是多样的!(不需要事先设计数据库!随取随用)
传统的RDBMS(结构化组织、SQL、数据和关系都单独存在单独的表、一致性、基础的事务) 和 NoSQL(没有固定的查询语言、不仅仅是数据、键值对、最终一致性、CAP定理和BASE、三高)
2、了解:3V + 3高(大数据)
大数据时代的3V:海量(Volume)、多样(Variety)、实时(Velocity)
大数据时代的3V:高并发、高可用、高可扩
NoSQl四大分类
- k-v键值对(
Redis、Oracle BDB)
sina:Redis
美团:Redis + Tair
阿里、du:Redis + memecache
- 文档型数据库(
MongoDB、ConthDB) - 列存储数据库(
HBase、分布式文件系统) - 图关系数据库(Neo4J、InfoGrid
存的是关系)
Redis是什么?
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSIC语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API,免费、开源。
Redis能干什么?
1、基于内存,可以做持久化
2、用来做缓存 (网站的首页信息)
3、做消息队列
4、做计数器(点赞、评论、收藏)
5、其它
Redis安装
windows
1.下载
github地址: https://github.com/tporadowski/redis/releases
- 下载完成解压到环境目录即可
- 开启Redis,双击运行服务(
redis-server.exe)默认端口为:6379 - 使用客户端连接服务(
redis-cli.exe)输入ping出现PONG即为连接成功!
Linux
- 下载linux安装包
redis-5.0.8.tar.gz - 解压Redis的安装包,程序/opt
- 进入解压后的文件,可以看见redis的配置文件
- 基本的环境安装
yum install gcc-c++
make
make install
- redis默认安装路径
user/local/bin/
6.将redis配置文件,复制到当前目录下
7.启动redis服务(运行redis-server ……)测试连接 redis -cli -p 6379 -->ping -->PONG
测试性能
- 在安装的Redis目录下打开
redis-benchmark.exe文件,自动完成测试 - 测试结果
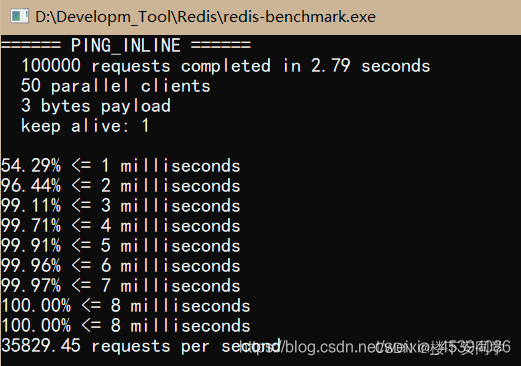
请求10万条数据用了2.79s,50个客户端请求,3个字节的有效载荷,一个会话维持!
可见Redis的速度是非常非常快的!
基础知识
Redis默认有16个数据库,默认使用第0个数据库
- 切换数据库 –
select 1进入第一个数据库– - 查看数据库所有的key:
key * - 清空当前数据库:
flushdb - 清空所有数据库:
FLUSHALL
思考:为什么redis使用6379作为端口?
– 一个女明星的名字 九宫格
5.Redis是单线程的!
Redis是基于内存操作,CPU不是Redis性能瓶颈,Redis的瓶颈是根据机器的内存和网络带宽,既然使用单线程来使用,就使用单线程,所以就使用单线程了!
Redis是C语言写的,官方提供的数据为100000 + 的QPS,不比使用kv的Memecache差!
6、redis为什么单线程还这么快?
1、误区一:高性能的服务器一定是多线程的
2、误区二:多线程一定比多线程效率高
核心:Redis是将所有的数据全部放在内存当中,所以说使用单线程去操作效率就是最高的,多线程(CPU上下文切换:耗时),对于内存系统来说,如果没有上下文切换效率是最高的!多次读写都是在同一个CPU上的,在内存情况下,这个就是最佳的方案!
Redis五大数据类型
官方文档:http://www.redis.cn/commands.html
Redis-Key
FlUSHDB # 清除当前数据库
FLUSHALL # 清除所有数据库数据
keys * # 查看所有的key值
set name mhan # 设置键(name)的值为(mhan)
EXISTS name # 查看键 name 是否存在
move name 1 # 移除键 1为当前数据库
get name # 获取name的值
EXPIRE name 10 # 设置name 的过期时间,单位是秒 (单点登录)
ttl name # 查看key(name)还有多长时间过期
type name # 查看key的一个类型
1、String(字符串)
-------------------------------------------------------------------------------
127.0.0.1:6379> set key1 hello, # 设置key 值为hello
OK
127.0.0.1:6379> APPEND key1 world! # 追加字符串 如果key不存在,则新建key
(integer) 12
127.0.0.1:6379> STRLEN key1 # 获取字符串的长度
(integer) 12
127.0.0.1:6379> get key1 # 获取key
"hello,world!"
127.0.0.1:6379> EXISTS key1 # 查看key是否存在
(integer) 1
-------------------------------------------------------------------------------
127.0.0.1:6379> set views 0 # 设置views(浏览量,为零)
OK
127.0.0.1:6379> incr views # 设置views自增1
(integer) 1
127.0.0.1:6379> incr views
(integer) 2
127.0.0.1:6379> decr views # 设置views自减1
(integer) 1
127.0.0.1:6379> INCRBY views 10 # 设置views自增 步长为10
(integer) 11
127.0.0.1:6379> DECRBY views 10 # 设置views自减 步长为10
(integer) 1
-------------------------------------------------------------------------------
# 截取字符串范围
127.0.0.1:6379> set key1 archpan
OK
127.0.0.1:6379> GETRANGE key1 0 3 # 字符串截取 [0,3]
"arch"
127.0.0.1:6379> GETRANGE key1 0 -1 # 取全部字符串 [0,-1]
"archpan"
-------------------------------------------------------------------------------
# 替换
127.0.0.1:6379> set key2 abcdefg
OK
127.0.0.1:6379> SETRANGE key2 1 xx # 替换指定位置开始的字符串
(integer) 7
127.0.0.1:6379> get key2
"axxdefg"
-------------------------------------------------------------------------------
# setex (set with expire) # 设置过期时间
# setnx (set if not exist) # 不存在再设置(常用于分布式锁)
127.0.0.1:6379> setex key3 30 "hello" # 设置 key3 过期时间为30秒
OK
127.0.0.1:6379> ttl key3 # 查看剩余有效时间
(integer) 22
127.0.0.1:6379> setnx mykey "mongoDB" # 如果mykey不存在时设置
(integer) 1
127.0.0.1:6379> get mykey
"mongoDB"
127.0.0.1:6379> setnx mykey "mongoDB1" # 如果mykey存在时,创建失败
(integer) 0
127.0.0.1:6379> get mykey
"mongoDB"
-------------------------------------------------------------------------------
# mset 同时设置多个值
# mget 同时获取多个值
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3 # 设置k1,k2,k3
OK
127.0.0.1:6379> mget k1 k2 k3 # 获取k1,k2,k3
1) "v1"
2) "v2"
3) "v3"
127.0.0.1:6379> msetnx k1 v1 k4 v4 # 如果不存在的时候设置
(integer) 0
127.0.0.1:6379> keys * # 上一步设置失败,因为redis是原子性的(要么全部成功--)
1) "k3"
2) "k2"
3) "k1"
-------------------------------------------------------------------------------
# 对象
set user:{name:zhangsan,age:13} # 设置一个user:1对象 值为json字符来保存
# 这里的key是一个巧妙地设计: user:{id}:{fields} ,在redis中是完全ok的!
127.0.0.1:6379> mset user:1:name zhangsan user:1:age 13
OK
127.0.0.1:6379> mget user:1:name user:1:age
1) "zhangsan"
2) "13"
-------------------------------------------------------------------------------
# getset 先get后set
127.0.0.1:6379> getset db redis # 如果不存在则返回nil
(nil)
127.0.0.1:6379> get db
"redis"
127.0.0.1:6379> getset db mongodb # 如果存在,获取原来的值,并且设置新的值
"redis"
127.0.0.1:6379> get db
"mongodb"
-------------------------------------------------------------------------------
String 类似的使用场景:value除了是字符串还可以是数字!
- 计数器
- 统计多单位的数量
- 粉丝数
- 对象缓存存储!
2、List(列表)
利用列表可以做一些骚操作(队列、栈、阻塞队列)
所有的list命令收拾以L开头的,不区分大小写
-------------------------------------------------------------------------------
127.0.0.1:6379> LPUSH list one # 将一个值或者多个值插入列表头部
(integer) 1
127.0.0.1:6379> LPUSH list two
(integer) 2
127.0.0.1:6379> LPUSH list three
(integer) 3
127.0.0.1:6379> LRANGE list 0 -1 # 获取list中的值(0 - -1为全部)
1) "three"
2) "two"
3) "one"
127.0.0.1:6379> LRANGE list 0 1 # 通过区间获取具体的值
1) "three"
2) "two"
127.0.0.1:6379> RPUSH list mhan # 将一个值或者多个值插入列表尾部
(integer) 4
-------------------------------------------------------------------------------
LPOP # 移除list的第一个元素
RPOP # 移除list的最后一个元素
127.0.0.1:6379> LPOP list # 移除list的第一个元素
"three"
127.0.0.1:6379> RPOP list # 移除list的最后一个元素
"mhan"
127.0.0.1:6379> LRANGE list 0 -1 # 获取list中的所有值
1) "two"
2) "one"
-------------------------------------------------------------------------------
Lindex # 通过下标获取具体的值
127.0.0.1:6379> LRANGE list 0 -1
1) "two"
2) "one"
127.0.0.1:6379> LINDEX list 1 # 通过下标获取具体的值
"one"
-------------------------------------------------------------------------------
Llen # 获取列表的长度
127.0.0.1:6379> LLEN list
(integer) 2
-------------------------------------------------------------------------------
# 移除指定的值 LREM
127.0.0.1:6379> LREM list 1 hello # 移除列表中指定的值,移除一个,精确
(integer) 1
-------------------------------------------------------------------------------
# LTRIM 截取
127.0.0.1:6379> LRANGE list 0 -1
1) "hello"
2) "two"
3) "one"
127.0.0.1:6379> Ltrim list 1 2 # 通过下标截取指定的长度,list被改变。
OK
127.0.0.1:6379> LRANGE list 0 -1
1) "two"
2) "one"
-------------------------------------------------------------------------------
rpoplpush # 移除列表最后一个元素并且加入目标列表
127.0.0.1:6379> rpush mylist "hello"
(integer) 1
127.0.0.1:6379> rpush mylist "hello1"
(integer) 2
127.0.0.1:6379> RPOPLPUSH mylist mylist2 # 移除列表中最后一个元素,加入新列表
"hello1"
127.0.0.1:6379> LRANGE mylist 0 -1 # 查看原列表
1) "hello"
127.0.0.1:6379> LRANGE mylist2 0 -1 # 新列表中确实存在了
1) "hello1"
-------------------------------------------------------------------------------
# lset 将列表中指定下标的值替换为另外一个值,更新操作
127.0.0.1:6379> EXISTS list # 判断列表是否存在
(integer) 0
127.0.0.1:6379> lset list 0 item # 如果不存在列表我们去更新就会报错
(error) ERR no such key
127.0.0.1:6379> lpush list value1
(integer) 1
127.0.0.1:6379> LRANGE list 0 0
1) "value1"
127.0.0.1:6379> lset list 0 item # 如果存在,更新当前下标的值
OK
127.0.0.1:6379> LRANGE list 0 0
1) "item"
127.0.0.1:6379> lset list 1 other # 如果不存在,则会报错!
(error) ERR index out of range
-------------------------------------------------------------------------------
# linsert 将某个具体的value插入到列中的某个元素的前面或者后面
127.0.0.1:6379> RPUSH mylist "hello" # 注意这里不是Lpush 而是Rpush 注意顺序哦
(integer) 1
127.0.0.1:6379> RPUSH mylist "world"
(integer) 2
127.0.0.1:6379> LINSERT mylist before "world" "other"
(integer) 3
127.0.0.1:6379> LRANGE mylist 0 -1
1) "hello"
2) "other"
3) "world"
127.0.0.1:6379> LINSERT mylist after "world" new
(integer) 4
127.0.0.1:6379> LRANGE mylist 0 -1
1) "hello"
2) "other"
3) "world"
4) "new"
小结:
1、列表实际上就是一个链表,before Node after,left ,right都可以插入值
2、如果key不存在,创建新的链表
3、如果key存在,新增内容
4、如果移除了所看值,空链表,也代表不存在!
5、在两边插入或者改动值,效率最高!如果链表非常长,中间元素,相对来说效率会低一点
消息排队!消息队列(LPush Rpop)从左边进,右边拿出来 栈(Lpush Lpop)从左边进 左边出
3、集合(Set)
所有的Set都是以S开头的
# Smembers 查看指定set的所有值
# SisMember 判断某一个值是不是在set集合中,类似于Java:contains
127.0.0.1:6379> sadd myset "hello" # set集合中添加元素 注意set中的值不能重复的!
(integer) 1
127.0.0.1:6379> sadd myset ""
(integer) 1
127.0.0.1:6379> sadd myset "ichpan"
(integer) 1
127.0.0.1:6379> SMEMBERS myset # 查看指定set的所有值
1) "ichpan"
2) "hello"
3) ""
127.0.0.1:6379> SISMEMBER myset hello # 判断某一个值是不是在set集合中!
(integer) 1
127.0.0.1:6379> SISMEMBER myset world
(integer) 0
-------------------------------------------------------------------------------
# Scard 获取set集合中的内容元素个数
127.0.0.1:6379> SCARD myset # 获取set集合中的内容元素个数!
(integer) 4
-------------------------------------------------------------------------------
# Srem 移除set集合中的指定元素
127.0.0.1:6379> srem myset hello # 移除set集合中的指定元素
(integer) 1
127.0.0.1:6379> SCARD myset
(integer) 3
127.0.0.1:6379> smembers myset
1) "ichpan"
2) ""
3) "ichpan1"
-------------------------------------------------------------------------------
# SRandMember 随机抽选出指定个数的元素
set是无序不重复集合,可以用来抽随机。
127.0.0.1:6379> SMEMBERS myset
1) "ichpan"
2) ""
3) "ichpan1"
127.0.0.1:6379> SRANDMEMBER myset # 随机抽选出一个元素
""
127.0.0.1:6379> SRANDMEMBER myset
"ichpan"
127.0.0.1:6379> SRANDMEMBER myset 2 # 随机抽选出指定个数的元素
1) "ichpan"
2) "ichpan1"
-------------------------------------------------------------------------------
# Spop 随机删除key
127.0.0.1:6379> SMEMBERS myset
1) "ichpan"
2) ""
3) "ichpan1"
127.0.0.1:6379> spop myset # 随机删除key 附:栈的弹出函数pop()
"ichpan"
127.0.0.1:6379> spop myset
"ichpan1"
127.0.0.1:6379> SMEMBERS myset
1) ""
-------------------------------------------------------------------------------
# SMove 将一个指定的值,移动到另外一个set集合
127.0.0.1:6379> sadd myset "hello"
(integer) 1
127.0.0.1:6379> sadd myset "world"
(integer) 1
127.0.0.1:6379> sadd myset ""
(integer) 1
127.0.0.1:6379> sadd myset2 set2
(integer) 1
127.0.0.1:6379> smove myset myset2 # 将一个指定的值,移动到另外一个set集合!
(integer) 1
127.0.0.1:6379> SMEMBERS myset
1) "hello"
2) "world"
127.0.0.1:6379> SMEMBERS myset2
1) ""
2) "set2"
-------------------------------------------------------------------------------
微博,B站,共同关注!(并集)
这里可以把key1当成up主1,a/b/c是up主1的粉丝
把key2当成up主2,c/d/e是up主2的粉丝
数学集合类:
- 差集
- 交集
- 并集
127.0.0.1:6379> sadd key1 a
(integer) 1
127.0.0.1:6379> sadd key1 b
(integer) 1
127.0.0.1:6379> sadd key1 c
(integer) 1
127.0.0.1:6379> sadd key2 c
(integer) 1
127.0.0.1:6379> sadd key2 d
(integer) 1
127.0.0.1:6379> sadd key2 e
(integer) 1
# sdiff
127.0.0.1:6379> sdiff key1 key2 # 差集 注意是以key1为参照物
1) "b"
2) "a"
# sinter
127.0.0.1:6379> sinter key1 key2 # 交集 共同好友就可以这么实现
1) "c"
# sunion
127.0.0.1:6379> sunion key1 key2 # 并集
1) "b"
2) "c"
3) "e"
4) "a"
5) "d"
微博,A用户将所有关注的人放在一个set集合中!将它的粉丝也放在一个集合中!
共同关注,共同爱好,二度好友,推荐好友!(六度分割理论)
4、Hash(哈希)
你可以理解成map集合 key-value形式,只是这个value是一个map集合的形式,本质和String类型没有太大区别,还是一个简单的key-vlaue!
-------------------------------------------------------------------------------
# hset
127.0.0.1:6379> hset myhash field1 # set 一个具体 key-value
(integer) 1
# hget
127.0.0.1:6379> hget myhash field1 # 获取1个字段值
""
# hmset
127.0.0.1:6379> hmset myhash field1 hello field2 world # set 多个具体 key-value 存在则覆盖
OK
# hkeys
127.0.0.1:6379> hkeys myhash # 只获取所有key
1) "field2"
2) "field1"
# hvals
127.0.0.1:6379> hvals myhash # 只获取所有value
1) "world"
2) "hello"
# hmget
127.0.0.1:6379> hmget myhash field1 field2 # 获取多个字段值
1) "hello"
2) "world"
# hgetall
127.0.0.1:6379> hgetall myhash # 获取哈希中全部的数据
1) "field1"
2) "hello"
3) "field2"
4) "world"
# hlen
127.0.0.1:6379> hlen myhash # 获取哈希表字段的数量
(integer) 2
# hdel
127.0.0.1:6379> hdel myhash field1 # 删除hash指定key字段:对应的value值也就消失了
(integer) 1
127.0.0.1:6379> hgetall myhash
1) "field2"
2) "world"
# hexists
127.0.0.1:6379> hexists myhash field2 # 判断hash中指定字段是否存在!
(integer) 1
127.0.0.1:6379> hexists myhash field3
(integer) 0
-------------------------------------------------------------------------------
127.0.0.1:6379> hset myhash field3 5
(integer) 1
# incr
127.0.0.1:6379> hincrby myhash field3 1 # 设置自增1
(integer) 6
# 反向incr = decr
127.0.0.1:6379> hincrby myhash field3 -1 # 设置自减
(integer) 5
# hsetnx
127.0.0.1:6379> hsetnx myhash field4 hello # 如果不存在则可以设置
(integer) 1
127.0.0.1:6379> hsetnx myhash field4 world # 如果存在则不能设置
(integer) 0
-------------------------------------------------------------------------------
# hset
127.0.0.1:6379> hset myhash field1 # set 一个具体 key-value
(integer) 1
# hget
127.0.0.1:6379> hget myhash field1 # 获取1个字段值
""
# hmset
127.0.0.1:6379> hmset myhash field1 hello field2 world # set 多个具体 key-value 存在则覆盖
OK
# hkeys
127.0.0.1:6379> hkeys myhash # 只获取所有key
1) "field2"
2) "field1"
# hvals
127.0.0.1:6379> hvals myhash # 只获取所有value
1) "world"
2) "hello"
# hmget
127.0.0.1:6379> hmget myhash field1 field2 # 获取多个字段值
1) "hello"
2) "world"
# hgetall
127.0.0.1:6379> hgetall myhash # 获取哈希中全部的数据
1) "field1"
2) "hello"
3) "field2"
4) "world"
# hlen
127.0.0.1:6379> hlen myhash # 获取哈希表字段的数量
(integer) 2
# hdel
127.0.0.1:6379> hdel myhash field1 # 删除hash指定key字段:对应的value值也就消失了
(integer) 1
127.0.0.1:6379> hgetall myhash
1) "field2"
2) "world"
# hexists
127.0.0.1:6379> hexists myhash field2 # 判断hash中指定字段是否存在!
(integer) 1
127.0.0.1:6379> hexists myhash field3
(integer) 0
-------------------------------------------------------------------------------
127.0.0.1:6379> hset myhash field3 5
(integer) 1
# incr
127.0.0.1:6379> hincrby myhash field3 1 # 设置自增1
(integer) 6
# 反向incr = decr
127.0.0.1:6379> hincrby myhash field3 -1 # 设置自减
(integer) 5
# hsetnx
127.0.0.1:6379> hsetnx myhash field4 hello # 如果不存在则可以设置
(integer) 1
127.0.0.1:6379> hsetnx myhash field4 world # 如果存在则不能设置
(integer) 0
-------------------------------------------------------------------------------
hash变更数据,user name age ,尤其用于用户信息保存,经常变动的信息!
hash更适合对象的存储,String更加适合字符串存储
5、Zset(有序集合)
Zset和Set多了一个Z,在set的基础上增加了一个值,set k1 v1 ,zset k1 score1 v1
-------------------------------------------------------------------------------
# Zadd
127.0.0.1:6379> zadd myset 1 one # 添加1个值
(integer) 1
127.0.0.1:6379> zadd myset 2 two 3 three # 添加多个值
(integer) 2
# Zrange
127.0.0.1:6379> zrange myset 0 -1 # 遍历打印所有数据
1) "one"
2) "two"
-------------------------------------------------------------------------------
127.0.0.1:6379> zadd salary 2500 zhangsan # 添加3个用户
(integer) 1
127.0.0.1:6379> zadd salary 5000 xiaoming
(integer) 1
127.0.0.1:6379> zadd salary 500
(integer) 1
# ZrangeByScore
127.0.0.1:6379> ZRANGEBYSCORE salary -inf +inf # 显示全部用户[从小到大]
1) ""
2) "zhangsan"
3) "xiaoming"
# ZrevRange
127.0.0.1:6379> ZREVRANGE salary 0 -1 # [从大到小] 进行排序 rev反转的意思
1) "xiaoming"
2) "zhangsan"
3) ""
127.0.0.1:6379> ZRANGEBYSCORE salary -inf 2500 withscores # 显示工资小于2500的升序排列
1) ""
2) "500"
3) "zhangsan"
4) "2500"
# zrem
127.0.0.1:6379> zrem salary xiaoming # 移除有序集合中的元素
(integer) 1
127.0.0.1:6379> zrange salary 0 -1
1) ""
2) "zhangsan"
# zcard
127.0.0.1:6379> zcard salary # 获取有序集合中的个数
(integer) 2
-------------------------------------------------------------------------------
127.0.0.1:6379> zadd myset 1 hello
(integer) 1
127.0.0.1:6379> zadd myset 2 world 3
(integer) 2
# zcount
127.0.0.1:6379> zcount myset 1 3 # 获取指定区间的成员数量
(integer) 3
127.0.0.1:6379> zcount myset 1 2
(integer) 2
-------------------------------------------------------------------------------
案例思路:set 排序存储班级成绩表,工资表排序!
普通消息,1.重要消息 2.带权重进行判断!
bilibili热点排行榜应用实现(set集合排序 按分钟刷新)
三种特殊数据类型
1、geospatial 地理位置空间
朋友的定位,附近的人,打车距离计算?
Redis 的 Geo 在Redis3.2版本就推出了!这个功能可以推算地理位置的信息,两地之间的距离,方圆几里的人!
可以查询一些测试数据:https://jingweidu.51240.com/
只有6个命令
- geoadd(添加地理位置)
# getadd 添加地理位置
# 规则:南北两级无法直接添加,我们一般会下载城市数据,直接通过java程序一次性导入!
# 参数 key 值(纬度、经度、名称)
# 有效的经度从-180度到180度。
# 有效的纬度从-85.05112878度到85.05112878度。
# 当坐标位置超出上述指定范围时,该命令会返回一个错误
# (error) ERR invalid longitude,latitude pair 39.900000,116.400000
127.0.0.1:6379> geoadd china:city 116.40 39.90 beijing
(integer) 1
127.0.0.1:6379> geoadd china:city 121.47 31.23 shanghai 106.50 29.53 chongqing
(integer) 2
127.0.0.1:6379> geoadd china:city 120.16 30.24 hangzhou 108.96 34.26 xian 114.05 22.52 shenzhen
(integer) 3
- geopos(或者当前定位:一定是一个坐标值!)
127.0.0.1:6379> geopos china:city hangzhou beijing # 获取指定的城市的经度和纬度
1) 1) "120.1600000262260437"
2) "30.2400003229490224"
2) 1) "116.39999896287918091"
2) "39.90000009167092543"
- geodist (返回两个给定位置之间的距离)
- m 表示单位为米。
- km 表示单位为千米。
- mi 表示单位为英里。
- ft 表示单位为英尺。
如果用户没有显式地指定单位参数, 那么
GEODIST默认使用米作为单位。
127.0.0.1:6379> geodist china:city hangzhou shanghai # 查看杭州到上海的直线距离 单位:米
"166761.2770"
127.0.0.1:6379> geodist china:city hangzhou beijing km # 查看杭州到北京的直线距离 单位:千米
"1127.3378"
- georadius (以给定的经纬度为中心, 找出某一半径内的元素)
如何实现:我附近的人?(获取所有附近的人的地址,定位!)通过半径来查询!
127.0.0.1:6379> GEORADIUS china:city 110 30 1000 km # 以110,30这个经纬度为中心,寻找方圆1000km内的城市 前提:所有数据应该都录入:china:city,才会让结果更加精确!
1) "chongqing"
2) "xian"
3) "shenzhen"
4) "hangzhou"
127.0.0.1:6379> GEORADIUS china:city 110 30 500 km withdist # 显示到中间位置的直线距离 半径500km
1) 1) "chongqing"
2) "341.9374"
2) 1) "xian"
2) "483.8340"
127.0.0.1:6379> GEORADIUS china:city 110 30 500 km withcoord # 显示到中心距离半径500km的城市 + 经纬度信息
1) 1) "chongqing"
2) 1) "106.49999767541885376"
2) "29.52999957900659211"
2) 1) "xian"
2) 1) "108.96000176668167114"
2) "34.25999964418929977"
127.0.0.1:6379> GEORADIUS china:city 110 30 500 km withcoord withdist count 3 # 筛选出指定结果 只显示2个是因为只有2个
1) 1) "chongqing"
2) "341.9374"
3) 1) "106.49999767541885376"
2) "29.52999957900659211"
2) 1) "xian"
2) "483.8340"
3) 1) "108.96000176668167114"
2) "34.25999964418929977"
- GEORADIUSBYMEMBER
# 找出位于指定范围内的元素,中心点是由给定的位置元素决定
127.0.0.1:6379> GEORADIUSBYMEMBER china:city beijing 1000 km
1) "beijing"
2) "xian"
127.0.0.1:6379> GEORADIUSBYMEMBER china:city shanghai 500 km
1) "hangzhou"
2) "shanghai"
- GEOHASH 命令 (返回一个或多个位置元素的 Geohash 表示)
该命令将返回11个字符的Geohash字符串
# 将二维的经纬度转换为一维的字符串,如果两个字符串越接近,那么则距离越近!
127.0.0.1:6379> GEOHASH china:city beijing chongqing
1) "wx4fbxxfke0"
2) "wm5xzrybty0"
- GEO 底层的实现原理:Zset! 我们可以用Zset命令来操作Geo
127.0.0.1:6379> zrem china:city beijing # 移除指定元素
(integer) 1
127.0.0.1:6379> ZRANGE china:city 0 -1 # 查看地图中全部元素
1) "chongqing"
2) "xian"
3) "shenzhen"
4) "hangzhou"
5) "shanghai"
2、hyperloglog 位图
什么是基数?(一个集合中不重复的元素)
- 简介
Redis 2.8.9版本就更新了Hyperloglog数据结构!
Redis Hyperloglog基数统计的算法!
**优点:**占用的内存是固定的,2^64不同的元素的技术,只需要废12kb内存。如果要从内存角度来比较的话Hyperloglog首选!
网页的UV(一个人访问一个网站多次,但是还是算作一个人!)
传统的方式,set 保存用户的id,然后就可以统计set中的元素数量作为标准判断!
这个方式如果保存大量的用户id,就会比较麻烦!我们的目的是为了计数,而不是保存用户id;
0.81%错误率!统计UV任务,可以忽略不计的!
测试使用
如果允许容错,那么一定可以使用Hyperloglog
如果不允许容错,就使用 set 或 自己的数据类型 即可
node1:6379> pfadd mykey a b c d e f g h i j # 创建第一组元素 mykey
(integer) 1
node1:6379> PFCOUNT mykey # 统计mykey元素的基数数量
(integer) 10
node1:6379> pfadd mykey2 i j z x c v n m # 创建第二组元素mykey2
(integer) 1
node1:6379> PFCOUNT mykey2
(integer) 8
node1:6379> pfcount mykey2 mykey
(integer) 15
node1:6379> PFMERGE mykey3 mykey mykey2 # 合并两组 mykey mykey2=>mykey3并集
OK
node1:6379> PFCOUNT mykey3 # 看并集的数量!
(integer) 15
3、bitmap 位图
- 位存储
面试题:
如何筛选用户是最快的:0-1-0-1是最快的。
统计疫情感染人数:0 0 1 0 0
14亿个中国人,设14亿个0,被感染了设为1.
统计用户信息,活跃、不活跃。登录、未登录。打卡,钉钉打卡打卡!只要2个状态的,都可以用Bitmaps来处理。
userid status day 这样非常麻烦
Bitmaps位图,数据结构!都是操作二进制位来进行记录,就只有0和1两个状态!
365天=365bit 1字节=8bit 46个字节左右!
- 测试
使用bitmap来记录周一到周日的打卡!周一:1 周二:0 周三:0 周四:1……
# getbit
node1:63 79> getbit sign 3 # 查看某一天是否打卡
(integer) 1
node1:6379> getbit sign 6
(integer) 0
# bigcount
node1:6379> bitcount sign # 查看是否全勤 统计操作,统计打卡的天数
(integer) 3
