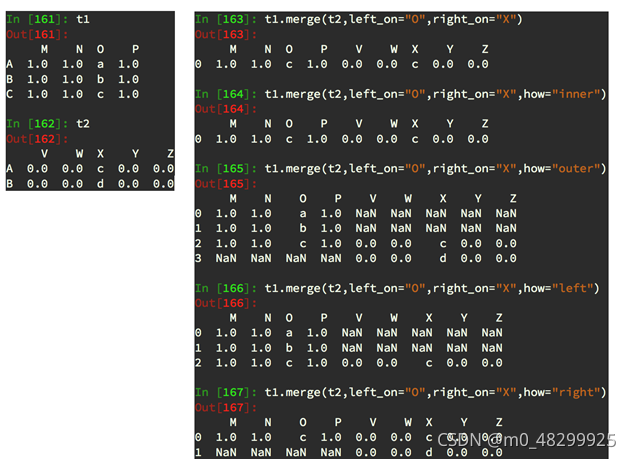
join
merge
练习
题目:统计电影分类(genre)的情况 P125
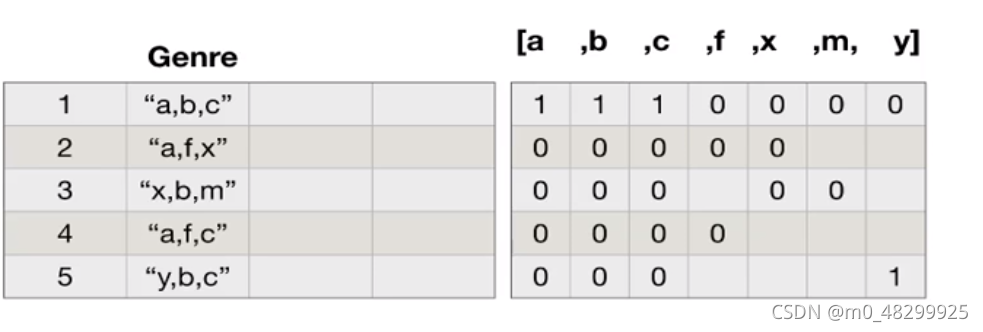
获取最初数据->tolist->将数据平铺 !!!两个循环->set去重且list->构造一个全0数组(行和列的取值!!)-->对号入座,找到位置,替换成1,进行列求和
#统计分类的列表
datalist2=df["Genre"].str.split(", ").tolist()
print(datalist2)
# 将数据平铺
datalist=[j for i in datalist2 for j in i]
print(datalist)
# set 转化成列表
data_list=list(set(datalist))
print(data_list)数据样式

#替换,出现电影名字的位置替换成1
for i in range(df.shape[0]):
# 利用【[[],[],[]] 字符串loc
datezeros.loc[i,datalist2[i]]=1
print(datezeros.head(3))进行列求和,得到的数据,就是分类去重后电影的数量
#算出每一列的和 axis=0 得到的数量就是有多少部电影
data0=datezeros.sum(axis=0)
print(data0)_x = data0.index
_y = data0.values
#画图
plt.figure(figsize=(20,8),dpi=80)
plt.bar(range(len(_x)),_y,width=0.4,color="orange")
plt.xticks(range(len(_x)),_x)
plt.show()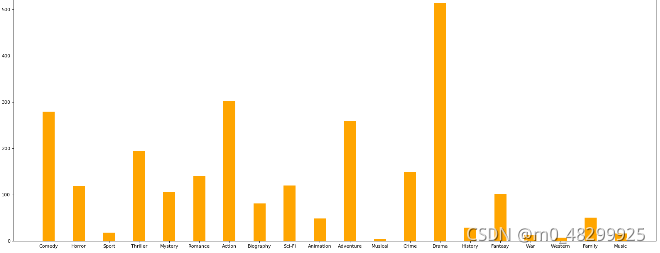
groupby:
grouped = df.groupby(by="columns_name")
统计美国和中国星巴克的数量
grouped=df.groupby(by="Country")
country_count=grouped["Brand].count()
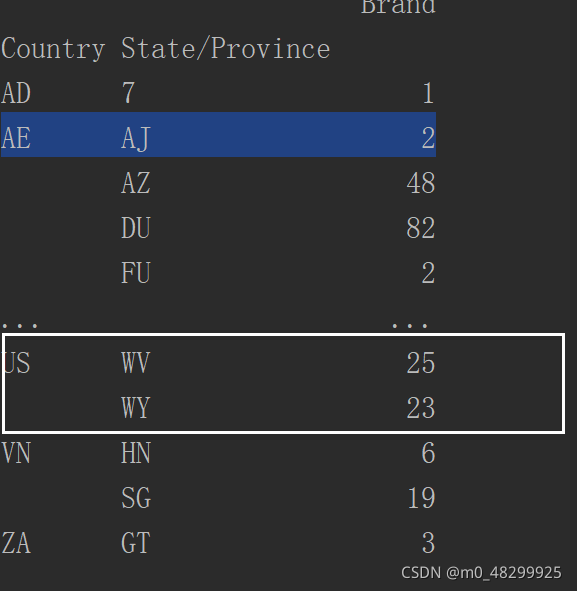
print(country_count["US"]) 获取美国的数据
易错点
df["Country"]=="CN" 会返回true或者false(找的是country这一列为CN)
df[df["Country"]=="CN" ] 会将true的数据返回
#统计中国每个省店铺的数量
china_data = df[df["Country"] =="CN"]
print("china_data",china_data)
数据按照多个条件进行分组
df["Brand"].groupby(by=[df["Country],df[""State/Province""]])
df["Brand"].groupby(by="Country","State/Province"]) 错误
取到的Brand那一列,类型是Series,那一列中没有Country,State/Province。
语法糖 Series-->DataFrame
Series-->DataFrame
grouped=df["Brand"].groupby(by=[df["Country],df[""State/Province""]])
print(type(grouped))
grouped1=df[df["Brand"]].groupby(by=[df["Country],df[""State/Province""]])
print(type(grouped1))转载 :pandas聚合和分组运算——GroupBy技术(1) - 数据之风 - 博客园(写的浅显易懂)
版权声明:本文为m0_48299925原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。