卫星图像识别tf.data、卷积综合实例
[5.1]–卫星图像识别卷积综合实例:图片数据读取
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import pathlib #面向对象的路径管理工具
data_dir = 'C:/Users/dingy\Desktop/JLU/2数据相关学习/日月光华深度学习/日月光华-tensorflow资料1/数据集/卫星图像识别数据/2_class'#数据目录
data_root = pathlib.Path(data_dir)
for item in data_root.iterdir():#对目录进行迭代,可以取出所有路径。
print(item)
all_image_paths = list(data_root.glob('*/*'))#用glob获取所有路径。(’*/*‘)提取所有目录的所有文件。
image_count = len(all_image_paths)
all_image_paths[:3]
all_image_paths[-3:]
得到
[WindowsPath('C:/Users/dingy/Desktop/JLU/2数据相关学习/日月光华深度学习/日月光华-tensorflow资料1/数据集/卫星图像识别数据/2_class/lake/lake_698.jpg'),
WindowsPath('C:/Users/dingy/Desktop/JLU/2数据相关学习/日月光华深度学习/日月光华-tensorflow资料1/数据集/卫星图像识别数据/2_class/lake/lake_699.jpg'),
WindowsPath('C:/Users/dingy/Desktop/JLU/2数据相关学习/日月光华深度学习/日月光华-tensorflow资料1/数据集/卫星图像识别数据/2_class/lake/lake_700.jpg')]
目前的路径是 WindowsPath对象,需要变成实际的路径。得到了全部图片的路径,然后进行乱序。
import random
all_image_paths = [str(path) for path in all_image_paths]#列表推导式,变成真正的路径。
random.shuffle(all_image_paths)#对全部图像路径进行乱序。
image_count = len(all_image_paths)
image_count
label_names = sorted(item.name for item in data_root.glob('*/') if item.is_dir())#提取目录名称并根据首字母进行排序。
label_names
label_to_index = dict((name, index) for index,name in enumerate(label_names))#进行enumerate编码,方便扩展到多个分类。
label_to_index
得到
{'airplane': 0, 'lake': 1}
以上进行了数据预处理。虽然对于二分类问题这种做法有些复杂,但是一旦有多个分类(如成百上千类)则可以直接套用上面的方法。
[5.2]–卫星图像识别卷积综合实例:读取和解码图片
为了获取全部图片的label,先构造pathlib对象。从所有的path里面取出所有图片上一级的文件夹名称(.parent.name),然后用label_to_index转化成图片对应的index。
all_image_labels = [label_to_index[pathlib.Path(path).parent.name] for path in all_image_paths]
import IPython.display as display#显示图像,直接显示在notebook里面。
for n in range(3):
image_index = random.choice(range(len(all_image_paths)))#随机取出三张图片的index。
display.display(display.Image(all_image_paths[image_index]))
print(caption_image(all_image_labels[image_index]))
print()
#显示出一张图片
#显示该图片的label
#显示空格
#重复三次
下一步进行图片的处理。
img_path = all_image_paths[0]
img_raw = tf.io.read_file(img_path)#读取图片产生一个二进制数据。
print(repr(img_raw)[:100]+"...")
img_tensor = tf.image.decode_image(img_raw)#tf.image.decode_image解码图片。
print(img_tensor.shape)
print(img_tensor.dtype)
得到
(256, 256, 3)#变成这种数据形状。
<dtype: 'uint8'>#变成这种数据类型。
这一部分演示了如何读取并解码图片。
[5.3]–卫星图像识别卷积综合实例:tf.data构造输入
img_tensor = tf.cast(img_tensor, tf.float32)#tf.cast改变数据类型,tf的数据类型可以参照np的数据类型。
img_final = img_tensor/255.0#标准化,img_tensor的取值范围是0-255.
print(img_final.shape)
print(img_final.numpy().min())
print(img_final.numpy().max())
得到
(256, 256, 3)
0.0
1.0
把读取、解码、改变数据类型及归一化写成一个函数。
def load_and_preprocess_image(path):
image = tf.io.read_file(path)#读取路径。
image = tf.image.decode_jpeg(image, channels=3)#解码图片。jpeg可以resize成需要的大小。
image = tf.image.resize(image, [256, 256])#一种改变图像大小的方法。
image = tf.cast(image, tf.float32)#转化数据类型
image = image/255.0 # normalize to [0,1] range
return image
试试这个函数行不行
import matplotlib.pyplot as plt
image_path = all_image_paths[0]
label = all_image_labels[0]
plt.imshow(load_and_preprocess_image(img_path))#plt.imshow画图
plt.grid(False)
plt.xlabel(caption_image(label))
print()
构造tf.data,用from tensor slice方法。
path_ds = tf.data.Dataset.from_tensor_slices(all_image_paths)#一种加载数据的方法,构造了一个数据集
AUTOTUNE = tf.data.experimental.AUTOTUNE
image_ds = path_ds.map(load_and_preprocess_image, num_parallel_calls=AUTOTUNE)
label_ds = tf.data.Dataset.from_tensor_slices(tf.cast(all_image_labels, tf.int64))
for label in label_ds.take(10):
print(label_names[label.numpy()])
[5.4]–卫星图像识别卷积综合实例tf.data构建图片输入管道
把图片和label合并到一个datasets,起到一一对应的效果。
map() 会根据提供的函数对指定序列做映射。
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
image_label_ds = tf.data.Dataset.zip((image_ds, label_ds))#以元组的形式合成一个数据集
image_label_ds
#<ZipDataset shapes: ((256, 256, 3), ()), types: (tf.float32, tf.int64)>
下一步划分训练集和测试集。
test_count = int(image_count*0.2)
train_count = image_count - test_count
train_data = image_label_ds.skip(test_count)
test_data = image_label_ds.take(test_count)
BATCH_SIZE = 32
train_data = train_data.apply(
tf.data.experimental.shuffle_and_repeat(buffer_size=train_count))
train_data = train_data.batch(BATCH_SIZE)
train_data = train_data.prefetch(buffer_size=AUTOTUNE)
train_data
test_data = test_data.batch(BATCH_SIZE)#test datasets不需要乱序。
[5.5]–卫星图像识别卷积综合实例分类模型训练
建立模型
model = tf.keras.Sequential() #顺序模型
model.add(tf.keras.layers.Conv2D(64, (3, 3), input_shape=(256, 256, 3), activation='relu'))
model.add(tf.keras.layers.Conv2D(64, (3, 3), activation='relu'))
model.add(tf.keras.layers.MaxPooling2D())
model.add(tf.keras.layers.Conv2D(128, (3, 3), activation='relu'))
model.add(tf.keras.layers.Conv2D(128, (3, 3), activation='relu'))
model.add(tf.keras.layers.MaxPooling2D())
model.add(tf.keras.layers.Conv2D(256, (3, 3), activation='relu'))
model.add(tf.keras.layers.Conv2D(256, (3, 3), activation='relu'))
model.add(tf.keras.layers.MaxPooling2D())
model.add(tf.keras.layers.Conv2D(512, (3, 3), activation='relu'))
model.add(tf.keras.layers.MaxPooling2D())
model.add(tf.keras.layers.Conv2D(512, (3, 3), activation='relu'))
model.add(tf.keras.layers.MaxPooling2D())
model.add(tf.keras.layers.Conv2D(1024, (3, 3), activation='relu'))
model.add(tf.keras.layers.GlobalAveragePooling2D())
model.add(tf.keras.layers.Dense(1024, activation='relu'))
model.add(tf.keras.layers.Dense(256, activation='relu'))
model.add(tf.keras.layers.Dense(1, activation='sigmod'))#二分类,逻辑回归,用sigmod进行激活判断和0.5的关系。
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['acc']
)
steps_per_epoch = train_count//BATCH_SIZE#训练的epoch数量,适当的时间结束训练。
validation_steps = test_count//BATCH_SIZE
history = model.fit(train_data, epochs=30, steps_per_epoch=steps_per_epoch, validation_data=test_data, validation_steps=validation_steps)
history.history.keys()
#dict_keys(['loss', 'acc', 'val_loss', 'val_acc'])
plt.plot(history.epoch, history.history.get('acc'), label='acc')
plt.plot(history.epoch, history.history.get('val_acc'), label='val_acc')
plt.legend()
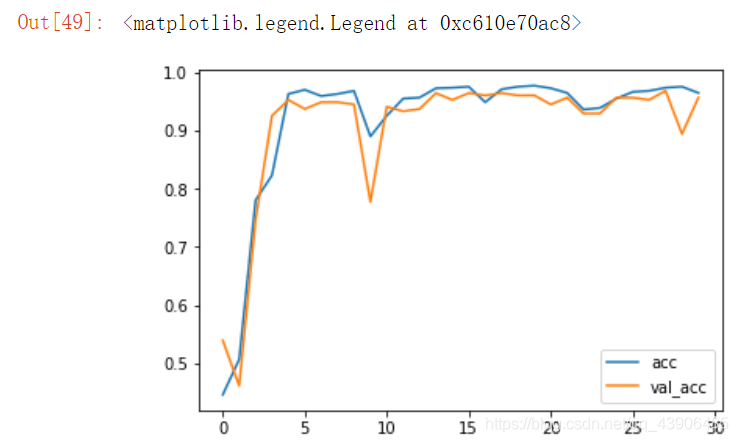
图像没有产生过拟合,但是对train数据没有达到100%。
plt.plot(history.epoch, history.history.get('loss'), label='loss')
plt.plot(history.epoch, history.history.get('val_loss'), label='val_loss')
plt.legend()
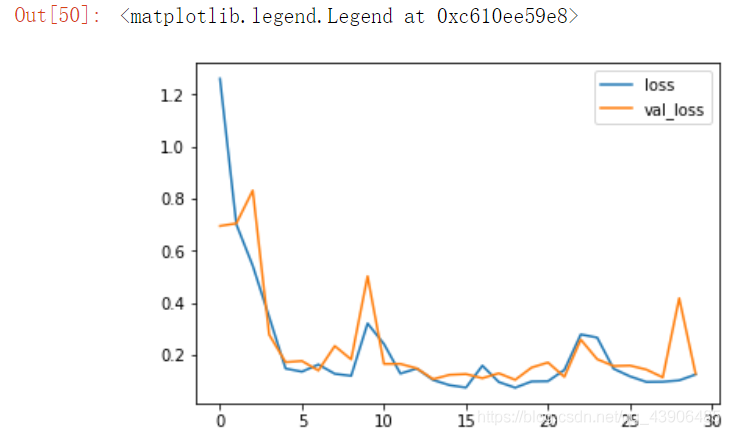
航拍数据的二分类实例。
[5.6]–批标准化



一般数据的归一化可以用(data-min)/(max-min)



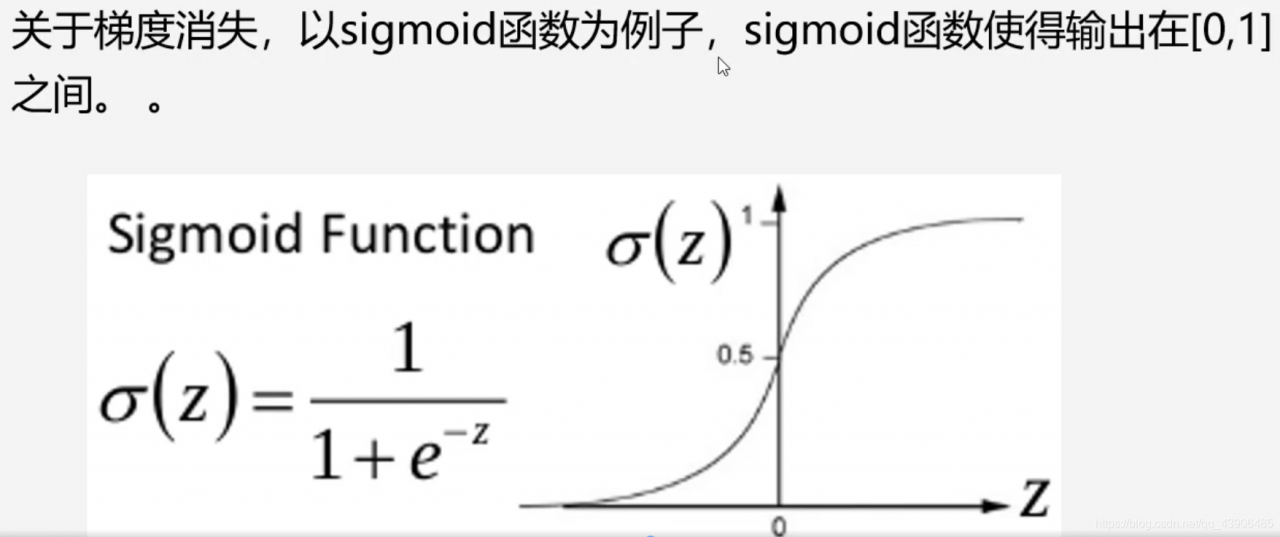
使得数据分布在0周围。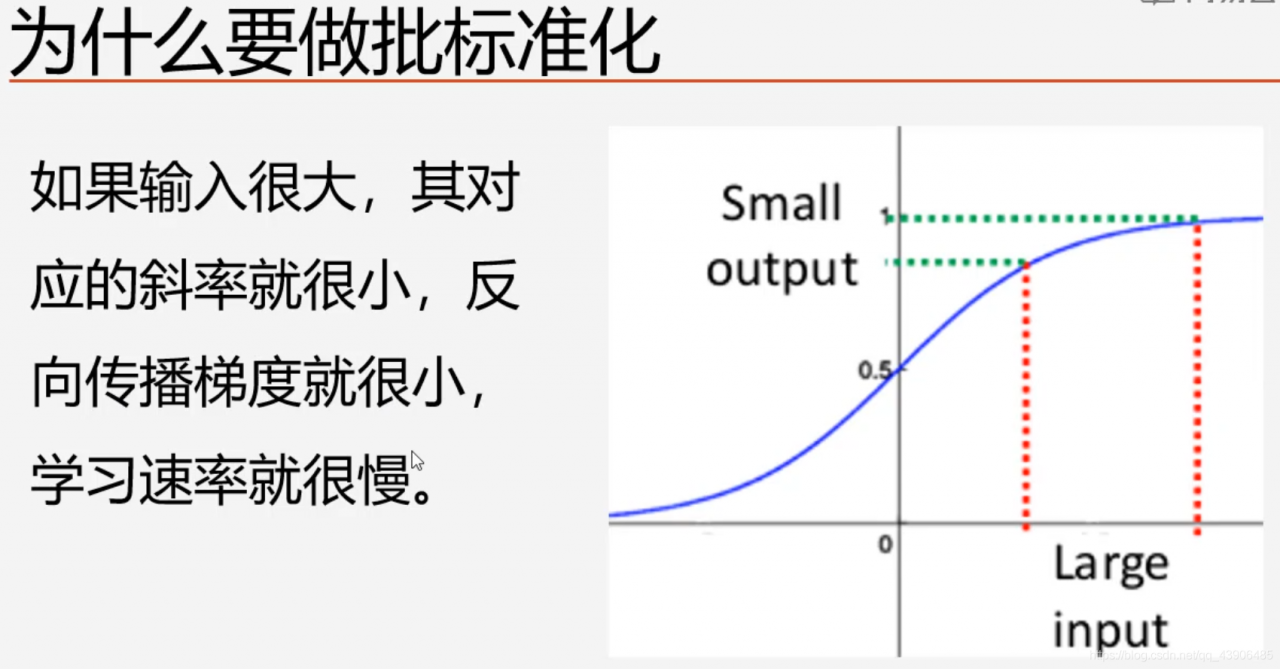









training= false 推理(预测)模式,使用在训练期间学习到的batch的均值和方差的期望值进行标准化。
原始论文先卷积,再batch标准化,再激活。
也可以先卷积,再激活,再batch标准化。
上图是添加批标准化层的方式。
深度学习框架中涉及很多参数,如果一些基本的参数如果不了解,那么你去看任何一个深度学习框架是都会觉得很困难,下面介绍几个新手常问的几个参数。
batch
深度学习的优化算法,说白了就是梯度下降。每次的参数更新有两种方式。
第一种,遍历全部数据集算一次损失函数,然后算函数对各个参数的梯度,更新梯度。这种方法每更新一次参数都要把数据集里的所有样本都看一遍,计算量开销大,计算速度慢,不支持在线学习,这称为Batch gradient descent,批梯度下降。
另一种,每看一个数据就算一下损失函数,然后求梯度更新参数,这个称为随机梯度下降,stochastic gradient descent。这个方法速度比较快,但是收敛性能不太好,可能在最优点附近晃来晃去,hit不到最优点。两次参数的更新也有可能互相抵消掉,造成目标函数震荡的比较剧烈。
为了克服两种方法的缺点,现在一般采用的是一种折中手段,mini-batch gradient decent,小批的梯度下降,这种方法把数据分为若干个批,按批来更新参数,这样,一个批中的一组数据共同决定了本次梯度的方向,下降起来就不容易跑偏,减少了随机性。另一方面因为批的样本数与整个数据集相比小了很多,计算量也不是很大。
基本上现在的梯度下降都是基于mini-batch的,所以深度学习框架的函数中经常会出现batch_size,就是指这个。
关于如何将训练样本转换从batch_size的格式可以参考训练样本的batch_size数据的准备。
iterations
iterations(迭代):每一次迭代都是一次权重更新,每一次权重更新需要batch_size个数据进行Forward运算得到损失函数,再BP算法更新参数。1个iteration等于使用batchsize个样本训练一次。
epochs
epochs被定义为向前和向后传播中所有批次的单次训练迭代。这意味着1个周期是整个输入数据的单次向前和向后传递。简单说,epochs指的就是训练过程中数据将被“轮”多少次,就这样。
举个例子
训练集有1000个样本,batchsize=10,那么:
训练完整个样本集需要:
100次iteration,1次epoch。
具体的计算公式为:
one epoch = numbers of iterations = N = 训练样本的数量/batch_size
注:
在LSTM中我们还会遇到一个seq_length,其实
batch_size = num_steps * seq_length