老师上课时说,我们在学习语言的过程中有遇到不懂的地方可以在知乎、论坛等网站搜索学习,也希望我们把学到的知识笔记分享出去帮助更多的人~于是我就准备在知乎整理一下我最近学习的笔记啦~在方便复习的同时,希望也能帮到在学习R语言过程中遇到困难的你们~
基本数据管理
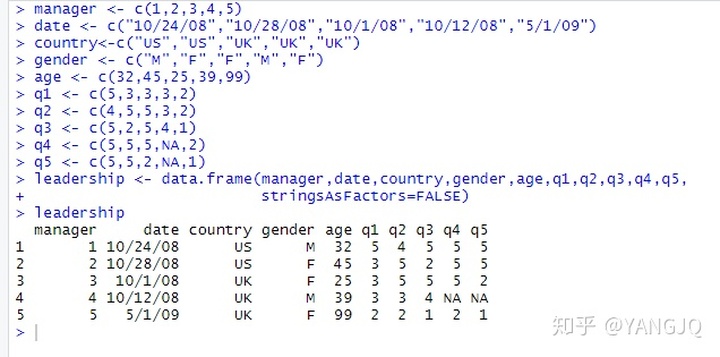
#创建leadership数据框
manager <- c(1,2,3,4,5)
date <- c("10/24/08","10/28/08","10/1/08","10/12/08","5/1/09")
country<-c("US","US","UK","UK","UK")
gender <- c("M","F","F","M","F")
age <- c(32,45,25,39,99)
q1 <- c(5,3,3,3,2)
q2 <- c(4,5,5,3,2)
q3 <- c(5,2,5,4,1)
q4 <- c(5,5,5,NA,2)
q5 <- c(5,5,2,NA,1)
leadership <- data.frame(manager,date,gender,age,q1,q2,q3,q4,q5,
stringsAsFactors=FALSE)
leadership运行结果如下(在代码输入区选中全部代码按ctrl+enter即可运行):
#创建新变量
语句形式:变量名<-表达式
- 例如:假如你有一个数据框,其中变量为x1,x2,那么a<-x1+x2,a就是你创建的新变量,即x1,x2这两个变量的加和。
书本上共介绍了三种方法创建新变量,分别为:
①
mydata<-data.frame(x1=c(2,1,3,5),x2=c(4,4,2,9))
mydata$sumx<-mydata$x1+mydata$x2
mydata$meanx<-(mydata$x1+mydata$x2)/2
mydata运行结果如下:

②
mydata<-data.frame(x1=c(2,1,3,5),x2=c(4,4,2,9))
attach(mydata)
mydata$sumx <- x1 + x2
mydata$meanx <- (x1 + x2)/2
detach(mydata)
mydata- attach()和detach()一般成对出现,用这两个函数是为了免去下面的代码输入的繁杂。
运行结果如下:

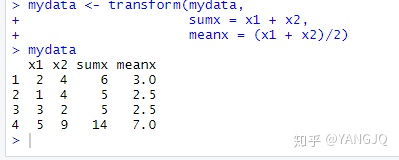
③
mydata<-data.frame(x1=c(2,1,3,5),x2=c(4,4,2,9))
mydata <- transform(mydata,
sumx = x1 + x2,
meanx = (x1 + x2)/2)
mydata- transform()函数简化了按需创建新变量并将其保存到数据框中的过程。
运行结果如下:
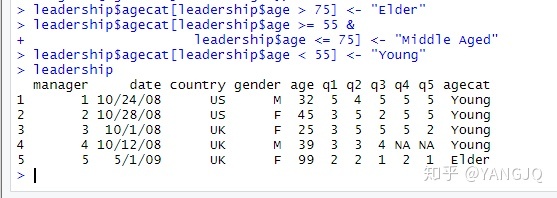
#变量的重编码
leadership$agecat[leadership$age > 75] <- "Elder"
leadership$agecat[leadership$age >= 55 &
leadership$age <= 75] <- "Middle Aged"
leadership$agecat[leadership$age < 55] <- "Young"
leadership运行结果如下:
或
leadership <- within(leadership,{
agecat <- NA
agecat[age > 75] <- "Elder"
agecat[age >= 55 & age <= 75] <- "Middle Aged"
agecat[age < 55] <- "Young" })
leadership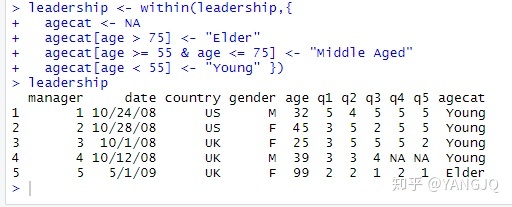
- 课本上说函数within()与函数with()类似,我查了一下函数with()的作用是简化代码,仅供参考。
#变量的重命名
如果对现有的变量名称不满意,你可以交互式地或以编程的方式修改它们。
若以交互式,你可以通过函数fix()来调用一个交互式的编辑器,这里就不举例啦。
若以编程方式,可以通过names()函数来重命名变量。例如:
names(leadership)
names(leadership)[5] <- "AGE"
leadership运行结果如下:

#缺失值
在Rstudio中,缺失值以符号NA(Not Available)表示,而函数is.na()则是用于识别缺失值是否存在。如果某个元素是缺失值,相应的位置将改写为TRUE,不是缺失值的位置则为FALSE。而na.omit()函数可以删除所有含有缺失数据的行。
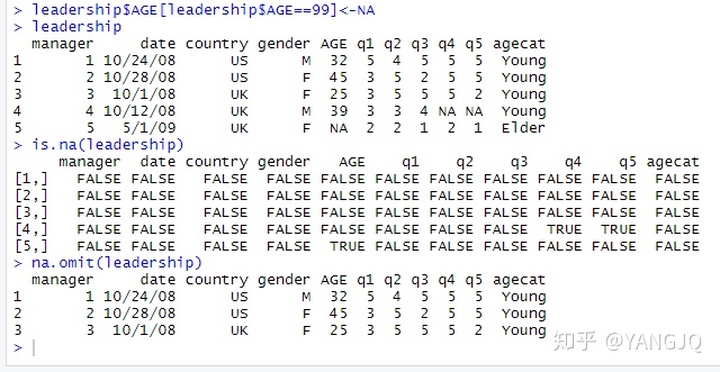
leadership$AGE[leadership$AGE==99]<-NA
leadership
is.na(leadership)
na.omit(leadership)运行结果如下:
#日期值
%d 数字表示的日期(0~31)
%a 缩写的星期名(Mon)
%A 非缩写的中文名(Monday)
%m 月份(00~12)
%b 缩写的月份(Jan)
%B 非缩写的月份(January)
%y 两位数的年份(07)
%Y 四位数的年份(2007)日期值的默认输入格式为yyy-mm-dd。
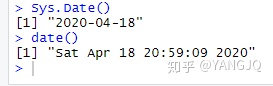
Sys.Date()可以返回当天的日期,而date()则返回当前的日期和时间。
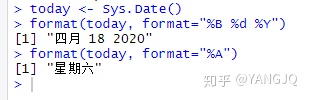
- 函数format(x,format="output_format")是用来输出指定格式的日期值,并且可以提取日期值中的某些部分:
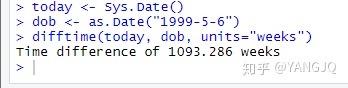
- 在日期值上还可以执行算术运算:

- 最后,也可以使用函数difftime()来计算时间间隔,并以星期、天、时、分、秒来表示。
#类型转换
名为is.datatype()这样的函数返回TRUE或FALSE,而as.datatype()这样的函数则将其参数转换为对应的类型。如下所示:

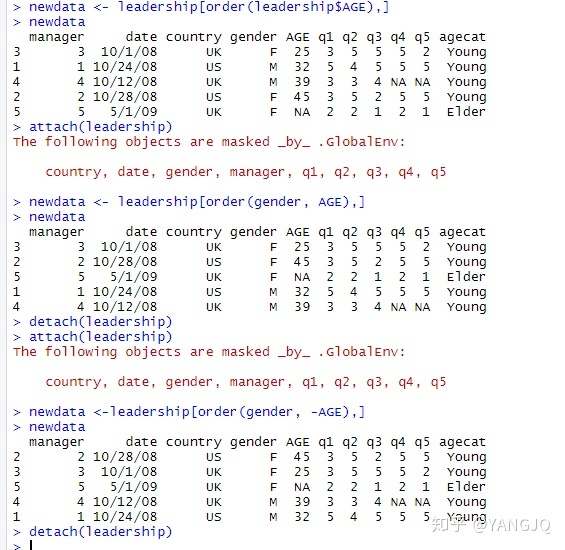
#数据排序
可以用order()函数对一个数据框进行排序,默认的排序顺序是升序,在排序变量的前边加一个减号即可得到降序的排序结果。如下:
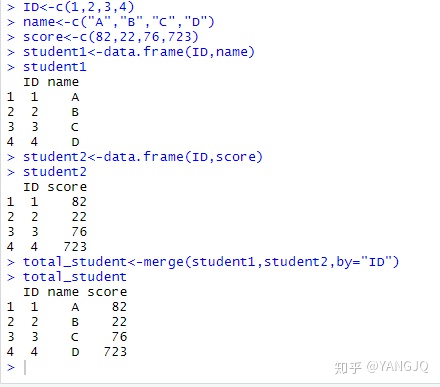
#数据集的合并
- 横向合并
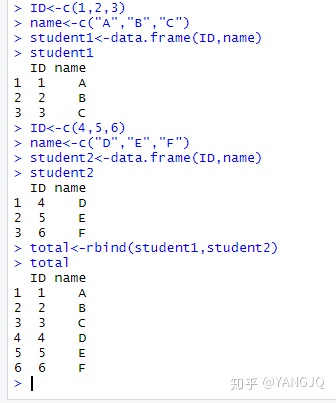
- 纵向合并
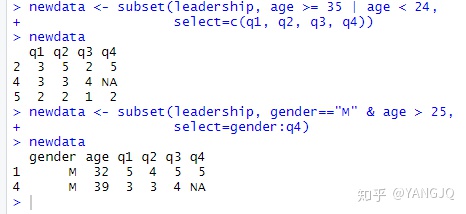
#剔除变量

#subset()函数
选择变量和观测变量最简单的方法。示例如下:
#随机抽样
sample( )函数可以实现数据的随机抽样。基本表达形式为:
sample(x, size, replace = FALSE)
简介:其中x是数值型向量,size是抽样个数,replace表示是否有放回抽样,默认FALSE是无放回抽样,TRUE是有放回抽样。

以上就是我这周的课堂学习笔记啦~代码大部分都是课本里的哦,还有老师课堂上讲的一些~实不相瞒,我也还学艺未精,如果看到的小伙伴发现有什么错误,望批评指正哦~大家一起学习吧!学习R语言一定要有耐心哦~