@author: huangyongye
1. RNN基础
对于RNN,我看到讲得最通俗易懂的应该是Andrej发的博客:
The Unreasonable Effectiveness of Recurrent Neural Networks
这里有它的中文翻译版本:
递归神经网络不可思议的有效性
如果想了解 LSTM 的原理,可以参考这篇文章:(译)理解 LSTM 网络 (Understanding LSTM Networks by colah)。
下面的连接中对RNN还有BPTT(RNN的反向传播算法),LSTM和GRU的原理和实现讲解得也是非常棒:
http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/
2.seq2seq
2.1 seq2seq 模型分析
首先介绍几篇比较重要的 seq2seq 相关的论文:
[1] Cho et al., 2014 . Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
[2] Sutskever et al., 2014. Sequence to Sequence Learning with Neural Networks
[3] Bahdanau et al., 2014. Neural Machine Translation by Jointly Learning to Align and Translate
[4] Jean et. al., 2014. On Using Very Large Target Vocabulary for Neural Machine Translation
[5] Vinyals et. al., 2015. A Neural Conversational Model[J]. Computer Science
顾名思义,seq2seq 模型就像一个翻译模型,输入是一个序列(比如一个英文句子),输出也是一个序列(比如该英文句子所对应的法文翻译)。这种结构最重要的地方在于输入序列和输出序列的长度是可变的。
举个栗子
在机器翻译:输入(hello) -> 输出 (你好)。输入是1个英文单词,输出为2个汉字。
在对话机器中:我们提(输入)一个问题,机器会自动生成(输出)回答。这里的输入和输出显然是长度没有确定的序列(sequences).
要知道,在以往的很多模型中,我们一般都说输入特征矩阵,每个样本对应矩阵中的某一行。就是说,无论是第一个样本还是最后一个样本,他们都有一样的特征维度。但是对于翻译这种例子,难道我们要让每一句话都有一样的字数吗,那样的话估计五言律诗和七言绝句又能大火一把了,哈哈。但是这不科学呀,所以就有了 seq2seq 这种结构。

图1. 论文[1] 模型按时间展开的结构
论文[1]Cho et al. 算是比较早提出 Encoder-Decoder 这种结构的,其中 Encoder 部分应该是非常容易理解的,就是一个RNNCell(RNN ,GRU,LSTM 等) 结构。每个 timestep, 我们向 Encoder 中输入一个字/词(一般是表示这个字/词的一个实数向量),直到我们输入这个句子的最后一个字/词 XT,然后输出整个句子的语义向量 c(一般情况下, c=hXT, XT是最后一个输入)。因为 RNN 的特点就是把前面每一步的输入信息都考虑进来了,所以理论上这个 c就能够把整个句子的信息都包含了,我们可以把
论文[1] 中的公式表示如下:
同样,根据 h<t>我们就能够求出 yt的条件概率:
这里有两个函数 f和 g, 一般来说,
论文[1]Cho et al. 中除了提出 Encoder-Decoder 这样一个伟大的结构以外,还有一个非常大的贡献就是首次提出了 Gated Recurrent Unit (GRU)这个使用频率非常高的 RNN 结构。
注意到在论文[1]Cho et al. 的模型结构中(如 图1 所示),中间语义 c不仅仅只作用于 decoder 的第 1 个时刻 ,而是每个时刻都有
而在论文[2] 中,Decoder 预测第 t 个 timestep 的输出时可以表示为:
也就是, 在论文[2] 中,Encoder 最后输出的中间语义只作用于 Decoder 的第一个时刻,这样子模型理解起来其实要比论文[1] 更容易一些。
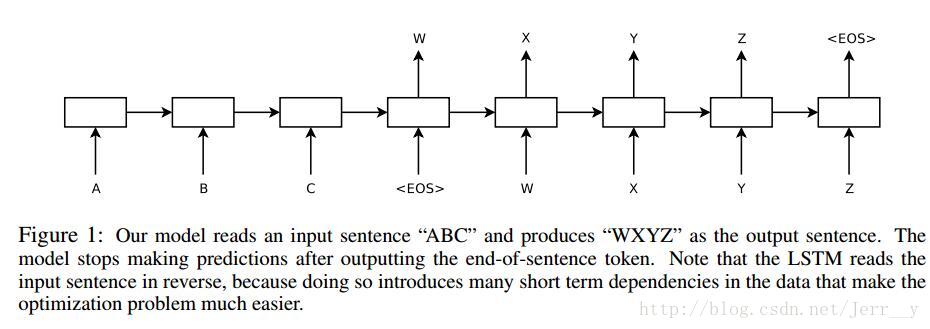
图2. 论文[2] 模型结构
论文[2]Sutskever et al. 中的 Encoder-Decoder 其实是最简单的,我在 github 上面找到下面这张非常棒的图,描述了这个模型的结构,由于该图最初来源网址打不开了,所以详细的介绍我也看不了,在 github 的网址为: https://github.com/nicolas-ivanov/tf_seq2seq_chatbot

图3. 论文[2] seq2seq 模型结构(原文为 4 层 LSTM,这里展示的是 1 层 LSTM)
图3 中展示的是一个邮件对话的应用场景,图中的 Encoder 和 Decoder 都只展示了一层的普通的 LSTMCell。从上面的结构中,我们可以看到,整个模型结构还是非常简单的。 EncoderCell 最后一个时刻的状态 [cXT,hXT]就是上面说的中间语义向量 c,它将作为 DecoderCell 的初始状态。然后在 DecoderCell 中,每个时刻的输出将会作为下一个时刻的输入。以此类推,直到 DecoderCell 某个时刻预测输出特殊符号
论文 [2]Sutskever et al. 也是我们在看 seq2seq 资料是最经常提到的一篇文章, 在原论文中,上面的Encoder 和 Decoder 都是 4 层的 LSTM,但是原理其实和 1 层 LSTM 是一样的。原文有个小技巧思想在上面的邮件对话模型结构没展示出来,就是原文是应用在机器翻译中的,作者将源句子顺序颠倒后再输入 Encoder 中,比如源句子为“A B C”,那么输入 Encoder 的顺序为 “C B A”,经过这样的处理后,取得了很大的提升,而且这样的处理使得模型能够很好地处理长句子。此外,Google 那篇介绍机器对话的文章(论文[5] )用的就是这个 seq2seq 模型。
在 CS224n lecture1 中, 也介绍了论文[2]的这个模型,下图是该课件中展示的模型结构。原文中提到的模型是 4 层的,课件上只是展示了三层,但是已经足够帮助我们理解模型结构了。
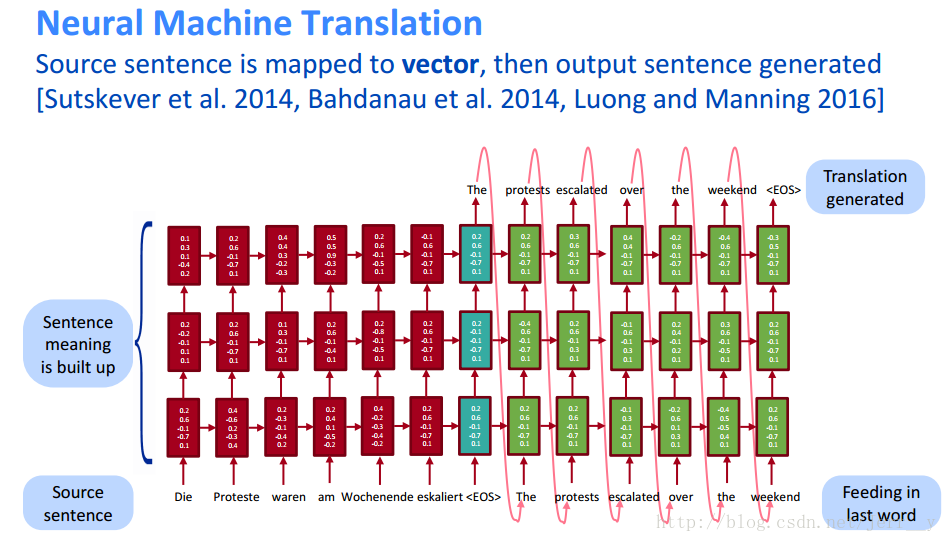
图4. 多层LSTM的 seq2seq 模型结构(来自 CS224n lecture1)
论文[3] Bahdanau et al. 是在 Encoder 和 Decoder 的基础上提出了注意力机制。在上面提到的结构中,每次预测都是从句向量 c中进行信息提取。但是如果句子很长的话,
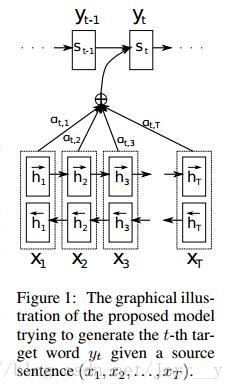
图5. 论文[3] 模型结构
如果你已经对论文[1]的模型结构充分理解,那么理解引入注意力机制的这个模型还是很容易的。在论文[1] 的 decoder 中,每次预测下一个词都会用到中间语义 c,而这个
此外,在论文[3] 中,Encoder用的是双端的 GRU,这个结构其实非常直观,在这种 seq2seq 中效果也要比单向的 GRU 要好。至于模型的细节可以看原论文来进行理解,在这里我就不做展开,有兴趣的也可以参考下面这篇文章,讲得非常好:张俊林: 自然语言处理中的Attention Model:是什么及为什么
论文[4]介绍了机器翻译在训练时经常用到的一个方法(小技巧)sample_softmax ,主要解决词表数量太大的问题。
关于seq2seq是什么,下面这篇文章讲得挺不错的,我最开始就是看了这篇文章,可以参考。
使用机器学习进行语言翻译:神经网络和seq2seq为何效果非凡?
2.2 模型应用
seq2seq其实可以用在很多地方,比如机器翻译,自动对话机器人,文档摘要自动生成,图片描述自动生成。比如Google就基于seq2seq开发了一个对话模型([5]A Neural Conversational Model),和论文[1,2]的思路基本是一致的,使用两个LSTM的结构,LSTM1将输入的对话编码成一个固定长度的实数向量,LSTM2根据这个向量不停地预测后面的输出(解码)。只是在对话模型中,使用的语料是((input)你说的话-我答的话(input))这种类型的pairs 。而在机器翻译中使用的语料是(hello-你好)这样的pairs。
此外,如果我们的输入是图片,输出是对图片的描述,用这样的方式来训练的话就能够完成图片描述的任务。等等,等等。
可以看出来,seq2seq具有非常广泛的应用场景,而且效果也是非常强大。同时,因为是端到端的模型(大部分的深度模型都是端到端的),它减少了很多人工处理和规则制定的步骤。在 Encoder-Decoder 的基础上,人们又引入了attention mechanism等技术,使得这些深度方法在各个任务上表现更加突出。
3. 模型细节
由于自己还没有编程实现过模型,所以现在只是根据论文做一些理解,可能有些地方不太正确,还得经过自己实践才能理解透彻。
下面对论文[1] 和论文[2] 的模型进行细致的分析和比较。
在论文[1] 的原文中,作者采用的是 GRUCell,这是 LSTMCell 的一个变种,图6 所示是 GRU 的模型结构。(注意下图中第四个式子和原文中的公式是有点不同的地方,就是 1−zt和 zt的位置和原文刚好相反,但是二者其实效果是一样的 ,后面的分析都是根据下面图示的结构来分析)
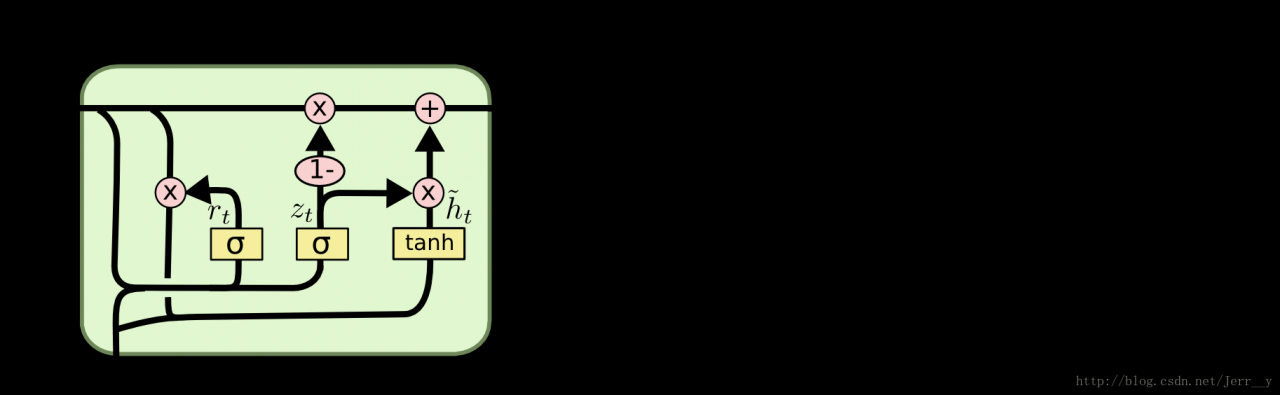
图6. GRU 结构(图片来自: Understanding LSTM Networks)
其中, rt表示重置门, zt表示更新门。重置门决定是否将之前的状态忘记。当 rt趋于 0 的时候,前一个时刻的状态信息 ht−1会被忘掉,隐藏状态 ht~会被重置为当前输入的信息。更新门决定是否要将隐藏状态更新为新的状态 ht~。
在 EncoderCell 中,模型结果就是上面图示的那样,理解应该没什么问题。最后一个输入 XT输入模型后,得到最后的隐藏状态为 hXT。但是跟论文[2] 不完全相同,这个 hXT还要做一次 tanh 变换后才得到最后的中间语义向量 c。
我觉得上面的矩阵 V一般都取单位阵(原文没说),这样子的话,就有:
这也是非常容易理解的,因为在 LSTM 中,输出 hT的时候是已经经过 tanh激活层处理,把输出值限制到 (-1,1) 中的。而在 GRU 的结构中,我们可以看到输出并没有经过 tanh激活层处理。
在 DecoderCell 中 ,我们从 EncoderCell 中已经拿到了刚刚输入的句子的语义向量 c,现在要逐步从
其中, ·’ 表示 DecoderCell 的隐含状态,和前面 EncoderCell 区分开。这里为什么又求了一次 tanh 我就不是太理解了。姑且不管这个,往下面看。下面的公式我就不再写上 ·’ 符号了,但是都是针对 DecoderCell 来说的:
具体是这样的:
其实和图5. 中的结构没有太大的区别,只是在每一步的输入中都加入了 c而已。假设输入词向量长度都是 embedding_size = 1000; 每层隐藏节点数都是 hidden_size = 1000 。那么就有:
rt,zt,c,ytϵR1000×1 - Wr,Wz,WϵR1000×3000
论文[2]相比论文[1] 要更容易理解一些,因为在 DecoderCell 中,直接用 Encoder 最后一个时间步的状态 [CXT,hXT]作为整个句子的中间语义 c,然后
c 直接作为Decoder 的初始状态。然后后面的计算中就没有再用到 c。
下面来推算一下改论文中说的模型参数规模。在论文中,主要实现了英文(source)到法文(target)的翻译。其中英文词典大小 source_vocab_size = 160,000,法文词典大小 target_vocab_size = 80,000,二者的词向量长度都是 embedding_size = 1,000。
- 每个 LSTMCell 中有 4 个权值矩阵
Wf,Wi,WC,WoϵR1000×2000 ,(可以参考: (译)理解 LSTM 网络 (Understanding LSTM Networks by colah))偏置参数太少忽略不计。那么每一层就有 2M × 4 = 8M 个参数。则 Encoder 和 Decoder 都是 4 层,就一共有 8M × 4 × 2 = 64M 参数。 - Embedding 矩阵大小为 embedding_size * vocab_size, 那么对于英文,有 1,000 × 160,000= 160 M; 对于法文, 有 1,000 × 80,000 = 80M。所以这里一共大约有 240M 参数。
- 对于 Decoder 的输出,采用 softmax 层输出每个类别(target word)的概率。所以这个全连接层的权值矩阵为 80,000 × 1,000= 80M。
所以一共大约有 64 + 240 + 80 = 384 M 参数,所以应该就是这样没错。
好吧,说了这么多细节都是纸上谈兵,还得赶紧实践一下才能真正理解呀。
- 每个 LSTMCell 中有 4 个权值矩阵