一、前导库用法
Json库
bs4、lxml主要针对html语言编写的代码,有时请求的内容返回Json代码,就需要用到Json库( Java Script Object Notation)。
Json库常用的方法是json.loads,用于解码 JSON 数据。该函数返回 Python 字段的数据类型。
import json
jsonData = '{"a":1,"b":2,"c":3,"d":4,"e":5}';
text = json.loads(jsonData)
print text
样板:
#获取智联招聘职位信息
import requests
from lxml import etree
import json
def get_urls():
url = 'https://fe-api.zhaopin.com/c/i/sou?start=0&pageSize=90&cityId=765&salary=0,0&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=pcb&kt=3&=0&_v=0.94714929&x-zp-page-request-id=ab2041e0e0b84d7'
rec = requests.get(url=url)
if rec.status_code == 200:
j = json.loads(rec.text) #解析之后的类型为字典类型
results = j.get('data').get('results')
for i in results:
jobname=i.get('jobName')#获取职位名称
print(jobname)
get_urls()
lxml库
是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高。
1、使用 lxml 的 etree 库,可以自动修正 HTML 代码。
from lxml import etree # 导入 lxml etree 库
html = etree.HTML(text) # 获取 html 内容 元素
result = etree.tostring(html)# 将内容元素转换为字符串
print(result.decode("utf-8"))# utf-8 格式输出
2、利用 parse 方法来读取文件
from lxml import etree
html = etree.parse('text.xml')# text.xml 是一个 xml 文件,并在当前文件同目录下
# pretty_print: 优化输出
result = etree.tostring(html, pretty_print=True)
print(result)
样板:
#获取网站的标题
import requests
from lxml import etree#导入相关的库
url = 'https://www.ftms.com.cn/footernav/tendernotice'
data = requests.get(url) #获取 url 网页源码
data.encoding="utf-8"
html = etree.HTML(data.text)#将网页源码转换为 XPath 可以解析的格式
title = html.xpath('/html/head/title/text()') #获取title
print(title)
requests 库
1、get方法的常用请求参数:url,headers,proxies
rec = requests.get(url) #url为请求的网址,必填参数
rec = requests.get(url,headers,proxies)#headers,proxies两个参数为可选,是反爬虫用
2、请求后生成rec的 Response 对象,该对象的主要方法有:
* rec.url:返回请求网站的 URL
* rec.status_code:返回响应的状态码,正常相应为200,
* rec.content:返回 bytes 类型的响应体
* rec.text:返回 str 类型的响应体,相当于 response.content.decode('utf-8')
* rec.json():返回 dict 类型的响应体,相当于 json.loads(response.text)
注意:.text 和 .content 的区别:
(1)text 返回的是unicode 型的数据,一般是在网页的header中定义的编码形式。content返回的是bytes,二进制型的数据。
(2)一般来说 .text直接用比较方便,返回的是字符串,但是有时候会解析不正常导致,返回的是一堆乱码这时用 .content.decode(‘utf-8’) 就可以使其显示正常。
(3)提取文本用text,提取图片、文件用content。
骨干样板:
import requests
url = 'http://www.yhjbox.com'
data = requests.get(url) #请求网页
完善点样板(加上headers、proxies参数):
import requests
url="http://www.yhjbox.com"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1"
"Cookie": "dafbaidaodf"}#设置请求网页时候的请求头
proxies = {"http": "http://1.197.203.57:9999"} #设置代理ip
rec = requests.get(url=url,headers=headers,proxies=proxies)
print(data.text)#打印网页源代码,字符串,正常解析
print(data.content)#打印网页源代码,二进制形式
二、四大选择器用法 / 对比
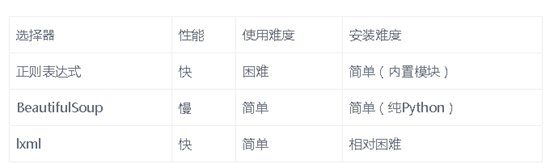
结论:
(1)上手难易度:bs4、xpath比较容易上手但是功能有限,正则比较晦涩难懂但是功能超级强大。
(2)爬虫个人目的:
(2-1)如果你的爬虫瓶颈是下载网页,而不是抽取数据,那么用较慢的方法(如BeautifulSoup) 也不成问题。
(2-2)如果只需抓取少量数据,并且想要避免额外依赖的话,那么正则表达式可能更加适合。
(2-3)but,通常lxml是抓取数据的最好选择,因为该方法既快速又健壮,而正则和bs只在某些特定场景下有用。
(3)效率 / 同一工作耗时:首选正则表达式,如果用正则表达式实在难于实现,再考虑xpath,另外,在使用xpath的时候一定要选用高效的库,比如lxml。特别是在数据量特别大的时候,效率显得尤为重要。
正则表达式
依赖于 re 模块,样板:requests和re库
import requests
import re #导入相关的库
url="https://www.yhjbox.com"
data = requests.get(url) #请求网页
pattern = re.compile(r'<title>(.*?)</title>') # 查找数字
title = pattern.findall(data.text)
print(title)
bs4
全名 BeautifulSoup,是编写 python 爬虫常用库之一,主要用来解析 html 标签。官方文档点击
一个完整讲解的案例
样板1:
#获取网页文章的标题
import requests
from bs4 import BeautifulSoup as bs#导入相关的库
url="http://www.yhjbox.com"
rec = requests.get(url=url)#请求网页
html = rec.text #.text方法获得字符串形式的网页源代码
soup = bs(html, "lxml") #对网页进行解析
titles=soup.find_all('img',class_="thumb") #获取文章标题 ,find是获取第一个标题,find_all是获取页面所有标题
for title in titles:
print(title.get('alt'))
样板2:
from bs4 import BeautifulSoup
import lxml
import requests
url='https://www.yhjbox.com'
data = requests.get(url)
soup = BeautifulSoup(data.content, 'lxml') #两个参数:第一个参数是要解析的html文本,第二个参数是使用哪种解析器
#对于HTML来讲就是html.parser,这是bs4自带的解析器;也可用lxml库来作为解析器,效率更高,这里正是!
title = soup.find_all('title')[0].string
print(title)
基本用法
from bs4 import BeautifulSoup
soup = BeautifulSoup(html,'lxml')
soup.prettify() #格式化网页代码,缺少的补齐等等
soup.title #获取<title>标签
soup.title.string #获取title的文本内容
soup.p #获取p标签
soup.p["class"] #获取p标签的class属性
soup.find_all('a') #返回所有的a标签,返回列表
xpath
是一种在 XML 文档中查找信息的语言。使用Chrome浏览器来手动获取XPath路径,复制xpath然后粘贴到代码里:
test = html.xpath('//a[@href]') #匹配某种规则
样板: requests、lxml(etree)库
import requests
from lxml import etree
url = 'https://www.yhjbox.com'
data = requests.get(url) #请求网页
html = etree.HTML(data.text)#解析网页
title = html.xpath('/html/head/title/text()') #提取网页数据
print(title)#打印title的内容
CSS
——————————————————————————————————————
通过爬取豆瓣电影top250学习requests库的使用 - https://www.cnblogs.com/airnew/p/9981599.html
Python网络爬虫实战一个完整系列(从理论到案例) https://www.jianshu.com/p/a13dc955d1f8
两个简短的小案例(仅仅使用几个基本库)
http://www.yhjbox.com/2019/08/4113/
https://mp.weixin.qq.com/s?__biz=MzIzMTU2OTkwOQ==&mid=2247485367&idx=1&sn=e1db9c77335d90dd9c92c6cf5354f53a&chksm=e8a3672ddfd4ee3b0162716751e2a2e543bfbd5df250128cc8167d134073f32a5007c59b35a3&scene=21#wechat_redirect
一个完整的案例-CSDN博客
https://blog.csdn.net/qq_36759224/article/details/101572275?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
网页基础手法讲解+scrapy模型实例[爬虫] 爬取豆瓣电影排行榜 - https://blog.csdn.net/makesomethings/article/details/89375462