1 安装
pip install elasticsearch
官方文档是:Python Elasticsearch Client — Elasticsearch 7.15.2 documentation
中文社区:Elastic中文社区
权威指南:https://es.xiaoleilu.com/index.html
2 连接
obj = ElasticSearchClass("0.0.0.0", "9200", "", "")
from elasticsearch import Elasticsearch
class ElasticSearchClass(object):
def __init__(self, host, port, user, passwrod):
self.host = host
self.port = port
self.user = user
self.password = passwrod
self.connect()
def connect(self):
"""客户端的连接"""
self.es = Elasticsearch(hosts=[{'host': self.host, 'port': self.port}],
http_auth=(self.user, self.password ))
def create():
result = es.indices.create(index='news', ignore=400) # 创建 Index
return result
def insert(self, index, type, body, id=None):
'''
插入一条body给指定的index、指定的type下;
可指定Id,若不指定,ES会自动生成
:param index: 待插入的index值
:param type: 待插入的type值, # es7后取消
:param body: 待插入的数据 # dict型
:param id: 自定义Id值
:return:
'''
self.es.create(index=index, doc_type=type, body=body, id=id) # 需指定
return self.es.index(index=index, doc_type=type, body=body, id=id)
def count(self, indexname):
"""
:return: 统计index总数
"""
return self.conn.count(index=indexname)
def delete(self, indexname, doc_type, id):
"""
:param indexname:
:param doc_type:
:param id:
:return: 删除index中具体的一条
"""
self.es.delete(index=indexname, doc_type=doc_type, id=id)
def delete_by_query(self, index, unique_id=False):
if unique_id:
self.es.delete(index=index, id=unique_id)
else:
self.es.delete_by_query(index, body= {'query': {'match_all': {}}})
def delete_index(self, index):
# 删除所有索引
if not index:
for index in es.indices.get("*"):
es.indices.delete(index)
else:
es.indices.delete(index)
def get(self, doc_type, indexname, id):
# index中具体的一条
return self.es.get(index=indexname,doc_type=doc_type, id=id)
def update(self, doc_type, indexname, body=data, id):
# 更新其中具体的一条
return self.es.update(index=indexname,doc_type=doc_type, body=data, id=id)
def searchindex(self, index):
"""
查找所有index数据
"""
try:
return self.es.search(index=index)
except Exception as err:
print(err)
def searchDoc(self, index=None, type=None, body=None):
'''
查找index下所有符合条件的数据
:param index:
:param type:
:param body: 筛选语句,符合DSL语法格式
:return:
'''
return self.es.search(index=index, doc_type=type, body=body)
def search(self,index,type,body,size=10,scroll='10s'):
"""
根据index,type查找数据,
其中size默认为十条数据,可以修改为其他数字,但是不能大于10000
"""
return self.es.search(index=index,
doc_type=type,body=body,size=size,scroll=scroll)
def scroll(self, scroll_id, scroll):
"""
根据上一个查询方法,查询出来剩下所有相关数据
"""
return self.es.scroll(scroll_id=scroll_id, scroll=scroll)
def proportion_not_null(self, index, field=None):
"""非空统计"""
a = self.count(index)['count']
b = self.count(index, {'query': {'bool': {'must': {'exists': {'field':
field}}}}})['count']
print(field, a, b, b / a)
def aggs_terms(self, index, field, size=15):
"""单字段统计"""
return self.search({
'aggs': {
'CUSTOM NAME': {
'terms': {
'field': field,
'size': size, # 解决aggs显示不全
}
}
}
}, index)['aggregations']['CUSTOM NAME']['buckets']
3 操作
from elasticsearch import Elasticsearch
# 1.elasticsearch的连接
obj = ElasticSearchClass("0.0.0.0", "9200", "", "")
# 2.数据的的插入
obj.insertDocument(index=”question”,type='text,id=9,
body= {"any":body,"timestamp":datetime.now()})
# 其中index和type是固定传入,id可以自己传入也可以系统生成,其中body数据为自己组合的数据
# 3.数据的删除
dd = obj.delete(index='question', type='text', id=7310)
# 数据删除时候是根据id进行删除,删除数据时候,
# index,type需要和之前传入时候的index,type保持一致
# 4. 数据的搜索
# 4.1、通过index搜索数据 其中,搜索之后数据显示默认为十条数据
res = obj.search(indexname=index)
# 4.2、通过body搜索数据
# 4.2.1、全部匹配:
# 查询所有数据
body = {
"query":{
"match_all":{}
}
}
response = obj.search(index="question",type="text",body=body)
# 返回的数据默认显示为十条数据,其中hits[“total”]为查询数量总数
# 其中Match_all 默认匹配所有的数据
# 4.2.2、广泛匹配某个字段
body = {
"query" : {
"match" : {
"data.content" : "马上马上"
}
}
}
# Match默认匹配某个字段
response = obj.search(index="question",type="text",body=body)
# 4.2.3、匹配多个字段
body = {
"query": {
"bool": {
"should": [
{ "match": { "data.content": "一根铁丝" }},
{ "match": { "data.question_content": "一根铁丝" }},
{ "match": { "data.ask_content.content": '一根铁丝' }}
],
}
}
}
# Should或匹配可以匹配某个字段也可以匹配所有字段,其中至少有一个语句要匹配,与 OR 等价
response = obj.search(index="question",type="text",body=body,scroll='5s')
# 4.2.4、匹配所有字段
body = {
"query": {
"bool": {
"must": [
{ "match": { "data.content": "李阿姨" }},
{ "match": { "data.question_content": "李阿姨" }},
{ "match": { "data.ask_content.content": '李阿姨' }}
],
}
}
}
Must必须匹配所有需要查询的字段, 与 and 等价
response = obj.search(index="question",type="text",body=body,scroll='5s')
# 4.2.5、短语匹配查询:
# 精确匹配一系列单词或者短语
body = {
"query" : {
"match_phrase" : {
"data.content" : "一根铁丝"
}
}
}
response = obj.search(index="question",type="text",body=body,scroll='5s')
# 4.2.6、高亮搜索:
# Elasticsearch 中检索出高亮片段。highlight 参数:
Body = {
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
},
"highlight": {
"fields" : {
"about" : {}
}
}
}
# 当执行该查询时,返回结果与之前一样,与此同时结果中还多了一个叫做 highlight 的部分。
# 这个部分包含了about 属性匹配的文本片段,并以 HTML 标签 <em></em> 封装:
{
...
"hits": {
"total": 1,
"max_score": 0.23013961,
"hits": [
{
...
"_score": 0.23013961,
"_source": {
"data.content": "李阿姨"
},
"highlight": {
"about": [
"张阿姨和<em>李阿姨</em>"
]
}
}
]
}
}
#5 分页+排序
{
'from': 20,
'size': 10,
'query': {'match': {'full_name': '老婆'}},
'sort': {'_id': {'order': 'asc'}}
}
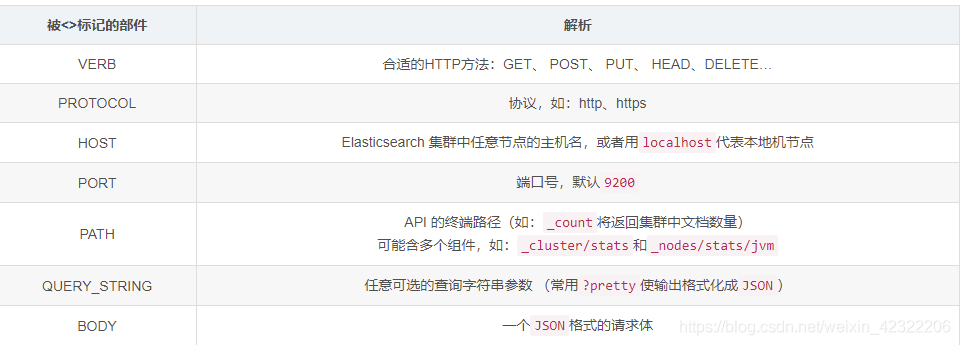
4 curl命令交互
cURL是一个利用URL语法在命令行下工作的文件传输工具(CommandLine Uniform Resource Locator)
curl -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'
curl -XGET 'http://localhost:9200/_count?pretty' -d '
{"query": {"match_all": {}}}
'
参考:
版权声明:本文为weixin_42322206原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。