分布式系统一致性初探
摘要:随着大规模系统及应用的高并发访问、海量数据处理等场景越来越多,如何实现此类系统的高可用、易伸缩、可扩展、安全等目标就显得尤为重要,而分布式系统架构的建设是解决上述问题的不错选择。依据分布式领域的CAP理论可知,当前任意分布式系统都无法同时满足一致性、可用性以及分区容错性这三大基本需求,最多只能满足其中之二。但无论在CAP三者之间如何权衡,都无法彻底地放弃一致性。因为一致性的放弃,表明系统中数据缺乏可信性,则该系统便没有任何价值可言。所以,无论如何,分布式一致性问题是分布式系统最为关键及重要的问题。本文从一致性简述、一致性协议分析及一致性协议算法在高可用分布式系统中的应用等三个方面对分布式系统的一致性进行初步探究。
0 引言
随着互联网技术和应用的高速发展,数据规模呈爆炸式的增长,继而使分布式系统得到越来越广泛的运用。数据分片存储、多副本冗余和多节点并发更新等多种机制在使分布式系统具备高可扩展性、高并发性等优势的同时,也引入了一致性、可用性的问题[1]。而实现分布式系统的动态一致性,需具备两大特性:a.操作一致性,即并发的更新操作在各个局部节点上串行化执行顺序和全局的串行化执行顺序是等价的;b.多副本一致性,即主节点和冗余备份节点之间数据的更新序列是一致的。分布式系统的一致性需要确保串行化执行顺序、节点的最终状态是全局一致的。保证了操作一致性、多副本一致性,就可以实现全局状态和局部状态不断地从一个一致的状态到达另一个一致状态,实现一种动态的一致。可用性指分布式系统能够自动容错,并持续地对外提供服务。
根据CAP理论[2],在分布式环境下,可用性和一致性只能保证一点。然而,一致性和可用性的权衡不必是两者达到彼此的极致。一致性可分为极致一致性、强一致性、最终一致性和弱一致性等多个级别,可用性可分为较高可用性、高可用性和弱可用性等。不同级别的可用性和一致性组合可满足不同的应用需求。很多互联网应用对一致性要求不高,采取最终一致和较高可用的组合,这是一种一致性换可用性的做法。而另一些对一致性要求较高的关键应用,比如银行系统和金融证券业,可以采取强一致性和高可用的组合,在保证多数派副本完全一致的前提下,将可用性尽可能地最大化[3]。
实现分布式系统的强一致性,关键是选取合适的分布式一致性协议(distributed consensus protocol)来保证一致性。由于数据分布在多个节点和网络的不确定性等因素,而各节点上的数据更新是相互隔离且独立进行的,因此,可能会出现的问题有:1)更新顺序不同即上文所述操作一致性问题;2)主备副本数据不同步即上文所述多副本一致性问题,继而需要使用分布式一致性协议来协调多节点并发更新和主备节点操作序列的同步,保证分布式系统的操作一致性和多副本一致性。
综上,分布式一致性协议是实现分布式系统所需的强一致性和高可用性的重要基础。本文梳理并总结了前人在提出一致性理论,设计一致性协议以及探索高可用性分布式系统方面进行的研究工作,进行了初步的分析与探索。
1 一致性简述
1.1 一致性问题概述
1.1.1 问题描述
通常情况下,我们所说的分布式一致性问题通常指的是数据一致性问题。因此本文主要以数据一致性为切入点,概要介绍一致性问题。数据一致性其实是数据库系统中的概念。我们可以简单的把一致性理解为正确性或者完整性,那么数据一致性通常指关联数据之间的逻辑关系是否正确和完整。在数据库系统中通常用事务(访问并可能更新数据库中各种数据项的一个程序执行单元)来保证数据的一致性和完整性。而在分布式系统中,数据一致性往往指的是由于数据的复制,不同数据节点中的数据内容是否完整并且相同。虽然分布式系统有着诸多优点,但是由于采用多机器进行分布式部署的方式提供服务,必然存在着数据的复制。分布式系统的数据复制需求主要来源于以下两个原因:1、可用性。将数据复制到分布式部署的多台机器中,可以消除单点故障,防止系统由于某台(些)机器宕机导致的不可用状态。2、性能。通过负载均衡技术,能够让分布在不同地方的数据副本全都对外提供服务,有效提高系统性能。
在分布式系统引入复制机制后,不同的数据节点之间由于网络延时等原因很容易产生数据不一致的情况。复制机制的目的是为了保证数据的一致性。但是数据复制面临的主要难题也是如何保证多个副本之间的数据一致性。假设有这样的场景,有两个人同时去两个不同的火车站买票(A去A火车站,B去B火车站),为了保证合理的卖票,需要在A火车站和B火车站之间共享关于剩余票数的数据。但是A和B要买的票只剩下一张,并且一张票当然只能卖给一个人。如果为了保证系统性能,那么A和B在买票的时候应该都可以买票成功(因为他们在买票过程中余票数据都显示还有一张余票)。两人在买完票之后,系统在做数据复制时发现一张票被卖出了两次,这时就要让A和B两人其中一人手中得票作废掉。这时就要花费很大的力气来通知后买到这张票的人这个消息。如果为了保证数据一致性,那么就需要在A买票的过程中,B只能等着。等A买票结束,并且把余票结果同步到B火车站的售票窗口。然后B才能知道还有没有余票可以购买。上面的例子可以简单的说明一个系统如果想保证数据一致性很有可能影响其性能。因为并发的写请求需要在前一个写请求结束之后才能进行。
因此,如何能既保证数据一致性,又保证系统的性能,是每一个分布式系统都需要重点考虑和权衡的。一致性模型可以在做这些权衡的时候给我们很多借鉴和思考。
1.1.2 模型介绍
一致性模型大概可以分为一下几种,分别是强一致性、弱一致性、最终一致性以及一致性的相关变种。
强一致性是指当更新操作完成之后,任何多个后续进程或者线程的访问都会返回最新的更新过的值。这种是对用户最友好的,就是用户上一次写什么,下一次就保证能读到什么。但是这种实现对性能影响较大。
弱一致性是指系统并不保证进程或者线程的访问都会返回最新的更新过的值。系统在数据写入成功之后,不承诺立即可以读到最新写入的值,也不会具体的承诺多久之后可以读到。但会尽可能保证在某个时间级别(比如秒级别)之后,可以让数据达到一致性状态。
最终一致性其实是弱一致性的特定形式。系统保证在没有后续更新的前提下,系统最终返回上一次更新操作的值。在没有故障发生的前提下,不一致窗口的时间主要受通信延迟,系统负载和复制副本的个数影响。
最终一致性模型的相关变种,包括因果一致性、读已所写一致性、会话一致性、单调度一致性、单调写一致性等。1、因果一致性:如果A进程在更新之后向B进程通知更新的完成,那么B的访问操作将会返回更新的值。如果没有因果关系的C进程将会遵循最终一致性的规则;2、读己所写一致性:因果一致性的特定形式。一个进程总可以读到自己更新的数据;3、会话一致性:读己所写一致性的特定形式。进程在访问存储系统同一个会话内,系统保证该进程读己之所写;4、单调读一致性:如果一个进程已经读取到一个特定值,那么该进程不会读取到该值以前的任何值;5、单调写一致性:系统保证对同一个进程的写操作串行化。
1.2 一致性理论概述
1.2.1 CAP理论
2000年7月,加州大学伯克利分校的Eric Brewer教授在ACM PODC会议上提出CAP猜想。2年后,麻省理工学院的Seth Gilbert和Nancy Lynch从理论上证明了CAP。之后,CAP理论正式成为分布式计算领域的公认定理。CAP理论指的是一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。一致性是指所有的节点在同一时刻所看到的数据是一致的,即更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致;可用性是指无论何时何地读写都是成功的,即服务一直可用,而且是正常响应时间;分区容忍性是指系统即使在部分节点丢失或出错的情况下依然能持续性提供服务,即分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。CAP理论严格证明了任何一个分布式系统都无法同时满足一致性、可用性、分区容错性这三个基本需求,最多只能满足其中两项。若选择放弃P(分区容错性),即选择加强一致性和可用性,其本质就是传统单机数据库的选择;而若选择放弃A(可用性),则其所导致的网络等问题会使整个系统不可用;又若选择放弃C(一致性,一般指强一致性),则表明该系统中数据不可信且无价值意义。但需要明确的一点是,对于一个分布式系统而言,分区容错性是一个最基本的要求。因为既然是一个分布式系统,那么分布式系统中的组件必然需要被部署到不同的节点,否则也就无所谓分布式系统了,从而必然出现子网络。而对于分布式系统而言,网络问题又是一个必定会出现的异常情况,因而分区容错性也就成为了一个分布式系统必然需要面对和解决的问题。而通常系统架构师往往需要把精力花在如何根据业务特点在一致性和可用性之间寻求平衡。
1.2.2 BASE理论
eBay的架构师Dan Pritchett源于对大规模分布式系统的实践总结,在ACM上发表文章提出BASE理论[4],BASE理论是对CAP理论的延伸,核心思想是即使无法做到强一致性(Strong Consistency,CAP的一致性就是强一致性),但应用可以采用适合的方式达到最终一致性(Eventual Consitency)。基本可用性是指分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用。例如电商大促时,为了应对访问量激增,部分用户可能会被引导到降级页面,服务层也可能只提供降级服务。这就是损失部分可用性的体现。软状态是指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。分布式存储中一般一份数据至少会有三个副本,允许不同节点间副本同步的延时就是软状态的体现。最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。
1.2.3 ACID与一致性理论的区别与联系
ACID是传统数据库常用的设计理念,即一个事务执行必须坚持A(原子性)、C(一致性)、I(隔离性)、D(持久性)这四大特性,以保证数据的安全、一致、持久,是追求强一致性的模型。而BASE理论面向的是大型高可用、高可扩展的分布式系统,其通过牺牲强一致性来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态。ACID和BASE代表了两种截然相反的设计哲学,在分布式系统设计的场景中,不同业务单元和系统组件对数据一致性要求是不同的,因此在具体的分布式系统架构设计过程中,ACID特性和BASE理论往往又会结合在一起。
2 一致性协议分析
在分布式系统中,为了保证数据的高可用,通常,我们会将数据保留多个副本(replica),这些副本会放置在不同的物理的机器上。为了对用户提供正确的增、删、改、差等语义,我们需要保证这些放置在不同物理机器上的副本是一致的。为了解决这种分布式一致性问题,前人在性能和数据一致性的反反复复权衡过程中总结了许多典型的协议。其中比较著名的有二阶提交协议(2PC Two Phase Commitment Protocol)[5][6][7]、Paxos算法[8][9][10]…….这些策略很多已经成为了工业标准,在工程实践中得到了越来越广泛的运用。分布式一致性协议的发展简史如图1所示。

图1分布式一致性协议发展简史
如图1所示,两阶段提交协议通过预提交阶段(投票阶段)和正式提交阶段的两轮消息交互,使得协调者和参与者可以就某项决定达成一致,该协议的详细步骤在有具体的介绍。三阶提交协议(3PCThree Phase Commitment Protocol)[11]是两阶段提交协议的优化,解决了两阶段提交协议的阻塞问题。Quorum[12]算法由Gifford于1979年提出,主要数学思想来源于鸽巢原理,通过限定读写操作最小参与的副本数目,实现读写操作的互斥来支持多副本的并发更新。Basic Paxos算法是Leslie Lamport于1998年提出的一种基于消息传递模型且具有高度容错特性的一致性算法。通过“提案阶段(Prepare)”和“接受阶段(Accept)”两个阶段使得提案者(proposer)和接受者(acceptor)就某项决议达成一致。除了Basic Paxos, Lamport还研究了多个变种算法,如Cheap Paxos[13]、Fast Paxos[14]和Vertical Paxos[15]等。Raft算法[16]是斯坦福大学的Diego Ongaro和John Ousterhout研究的一个管理日志复制的一致性算法。
2.1 分布式事务
分布式事务是指会涉及到操作多个数据库的事务。其实就是将对同一库的事务的概念扩大到了对多个库的事务。目的是为了保证分布式系统中的数据一致性。分布式事务处理的关键是必须有一种方法可以知道事务在任何地方所做的所有动作,提交或回滚事务的决定必须产生统一的结果(全部提交或全部回滚)。在分布式系统中,各个节点之间在物理上相互独立,通过网络进行沟通和协调。由于存在事务机制,可以保证每个独立节点上的数据操作可以满足ACID。但是,相互独立的节点之间无法准确的知道其他节点中的事务执行情况。所以从理论上讲,两台机器理论上无法达到一致的状态。如果想让分布式部署的多台机器中的数据保持一致性,那么就要保证在所有节点的数据写操作,要不全部都执行,要么全部的都不执行。但是,一台机器在执行本地事务的时候无法知道其他机器中的本地事务的执行结果。所以他也就不知道本次事务到底应该Commit还是 Roolback。所以,常规的解决办法就是引入一个“协调者”的组件来统一调度所有分布式节点的执行。
2.2 XA规范
X/Open 组织(即Open Group)定义了分布式事务处理模型。 X/Open DTP 模型(1994)包括应用程序(AP)、事务管理器(TM)、资源管理器(RM)、通信资源管理器(CRM)四部分。一般,常见的事务管理器(TM)是交易中间件,常见的资源管理器(RM)是数据库,常见的通信资源管理器(CRM)是消息中间件。通常把一个数据库内部的事务处理,如对多个表的操作,作为本地事务看待。数据库的事务处理对象是本地事务,而分布式事务处理的对象是全局事务。所谓全局事务,是指分布式事务处理环境中,多个数据库可能需要共同完成一个工作,这个工作即是一个全局事务,例如,一个事务中可能更新几个不同的数据库。对数据库的操作发生在系统的各处但必须全部被提交或回滚。此时一个数据库对自己内部所做操作的提交不仅依赖本身操作是否成功,还要依赖与全局事务相关的其它数据库的操作是否成功,如果任一数据库的任一操作失败,则参与此事务的所有数据库所做的所有操作都必须回滚。一般情况下,某一数据库无法知道其它数据库在做什么,因此,在一个 DTP 环境中,交易中间件是必需的,由它通知和协调相关数据库的提交或回滚。而一个数据库只将其自己所做的操作(可恢复)影射到全局事务中。XA 就是 X/Open DTP 定义的交易中间件与数据库之间的接口规范(即接口函数),交易中间件用它来通知数据库事务的开始、结束以及提交、回滚等。 XA 接口函数由数据库厂商提供。
二阶提交协议和三阶提交协议就是根据这一思想衍生出来的。可以说二阶段提交其实就是实现XA分布式事务的关键,即两阶段提交主要保证了分布式事务的原子性:即所有结点要么全做要么全不做。
2.3 2PC协议
二阶段提交是指在计算机网络以及数据库领域内,为了使基于分布式系统架构下的所有节点在进行事务提交时保持一致性而设计的一种算法(Algorithm)。通常,2PC也被称为是一种协议(Protocol)。在分布式系统中,每个节点虽然可以知晓自己的操作时成功或者失败,却无法知道其他节点的操作的成功或失败。当一个事务跨越多个节点时,为了保持事务的ACID特性,需要引入一个作为协调者的组件来统一掌控所有节点(称作参与者)的操作结果并最终指示这些节点是否要把操作结果进行真正的提交(比如将更新后的数据写入磁盘等等)。因此,2PC的算法思路可以概括为:参与者将操作成败通知协调者,再由协调者根据所有参与者的反馈情报决定各参与者是否要提交操作还是中止操作。所谓的两个阶段是指:第一阶段:准备阶段(投票阶段)和第二阶段:提交阶段(执行阶段)。
2.3.1 准备阶段
事务协调者(事务管理器)给每个参与者(资源管理器)发送Prepare消息,每个参与者要么直接返回失败(如权限验证失败),要么在本地执行事务,写本地的redo和undo日志,但不提交,到达一种“万事俱备,只欠东风”的状态。
可以进一步将准备阶段分为以下三个步骤:
1)协调者节点向所有参与者节点询问是否可以执行提交操作(vote),并开始等待各参与者节点的响应。
2)参与者节点执行询问发起为止的所有事务操作,并将Undo信息和Redo信息写入日志。(注意:若成功这里其实每个参与者已经执行了事务操作)
3)各参与者节点响应协调者节点发起的询问。如果参与者节点的事务操作实际执行成功,则它返回一个“同意”消息;如果参与者节点的事务操作实际执行失败,则它返回一个“中止”消息。
2.3.2 提交阶段
如果协调者收到了参与者的失败消息或者超时,直接给每个参与者发送回滚(Rollback)消息;否则,发送提交(Commit)消息;参与者根据协调者的指令执行提交或者回滚操作,释放所有事务处理过程中使用的锁资源。
分别在两种情况下讨论提交过程,当协调者节点从所有参与者节点获得的相应消息都为“同意”时:

图2响应消息为“同意”的节点提交过程
1)协调者节点向所有参与者节点发出“正式提交(Commit)”的请求。
2)参与者节点正式完成操作,并释放在整个事务期间内占用的资源。
3)参与者节点向协调者节点发送“完成”消息。
4)协调者节点受到所有参与者节点反馈的“完成”消息后,完成事务。
若任一参与者节点在第一阶段返回的响应消息为“中止”,或者 协调者节点在第一阶段的询问超时之前无法获取所有参与者节点的响应消息时:
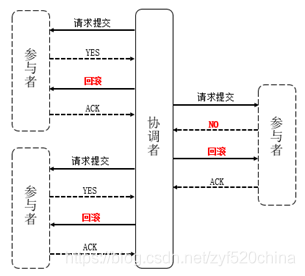
图3响应消息为“中止”的节点提交过程
1)协调者节点向所有参与者节点发出“回滚操作(rollback)”的请求。
2)参与者节点利用之前写入的Undo信息执行回滚,并释放在整个事务期间内占用的资源。
3)参与者节点向协调者节点发送“回滚完成”消息。
4)协调者节点受到所有参与者节点反馈的“回滚完成”消息后,取消事务。
二阶段提交看起来确实能够提供原子性的操作,但不幸的是2PC协议还是有几个缺点的:
- 同步阻塞问题。执行过程中,所有参与节点都是事务阻塞型的。当参与者占有公共资源时,其他第三方节点访问公共资源不得不处于阻塞状态。
- 单点故障。由于协调者的重要性,一旦协调者发生故障。参与者会一直阻塞下去。尤其在第二阶段,协调者发生故障,那么所有的参与者还都处于锁定事务资源的状态中,而无法继续完成事务操作。(如果是协调者挂掉,可以重新选举一个协调者,但是无法解决因为协调者宕机导致的参与者处于阻塞状态的问题)
- 数据不一致。在二阶段提交的阶段二中,当协调者向参与者发送Commit请求之后,发生了局部网络异常或者在发送Commit请求过程中协调者发生了故障,这回导致只有一部分参与者接受到了Commit请求。而在这部分参与者接到Commit请求之后就会执行Commit操作。但是其他部分未接到Commit请求的机器则无法执行事务提交。于是整个分布式系统便出现了数据部一致性的现象。
- 二阶段无法解决的问题:协调者再发出Commit消息之后宕机,而唯一接收到这条消息的参与者同时也宕机了。那么即使协调者通过选举协议产生了新的协调者,这条事务的状态也是不确定的,没人知道事务是否被已经提交。
2.4 3PC协议
由于二阶段提交存在着诸如同步阻塞、单点问题、脑裂等缺陷,所以,研究者们在二阶段提交的基础上做了改进,提出了三阶段提交。三阶段提交,也叫三阶段提交协议,是二阶段提交的改进版本。
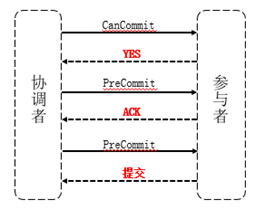
图4三阶段提交过程
与两阶段提交不同的是,三阶段提交有两个改动点:
1)引入超时机制。同时在协调者和参与者中都引入超时机制。
2)在第一阶段和第二阶段中插入一个准备阶段。保证了在最后提交阶段之前各参与节点的状态是一致的。
也就是说,除了引入超时机制之外,3PC把2PC的准备阶段再次一分为二,这样三阶段提交就有CanCommit、PreCommit、DoCommit三个阶段。
2.4.1 CanCommit阶段
3PC的CanCommit阶段其实和2PC的准备阶段很像。协调者向参与者发送Commit请求,参与者如果可以提交就返回Yes响应,否则返回No响应。
1)事务询问。协调者向参与者发送CanCommit请求。询问是否可以执行事务提交操作。然后开始等待参与者的响应。
2)响应反馈。参与者接到CanCommit请求之后,正常情况下,如果其自身认为可以顺利执行事务,则返回Yes响应,并进入预备状态。否则反馈No。
2.4.2 PreCommit阶段
协调者根据参与者的反应情况来决定是否可以记性事务的PreCommit操作。根据响应情况,有以下两种可能。
假如协调者从所有的参与者获得的反馈都是Yes响应,那么就会执行事务的预执行。
1)发送预提交请求。协调者向参与者发送PreCommit请求,并进入Prepared阶段。
2)事务预提交。参与者接收到PreCommit请求后,会执行事务操作,并将undo和redo信息记录到事务日志中。
3)响应反馈。如果参与者成功的执行了事务操作,则返回ACK响应,同时开始等待最终指令。
假如有任何一个参与者向协调者发送了No响应,或者等待超时之后,协调者都没有接到参与者的响应,那么就执行事务的中断。
1)发送中断请求。协调者向所有参与者发送abort请求。
2)中断事务。参与者收到来自协调者的abort请求之后(或超时之后,仍未收到协调者的请求),执行事务的中断。
2.4.3 DoCommit阶段
该阶段进行真正的事务提交,也可以分为以下两种情况。
执行提交:
1)发送提交请求。协调接收到参与者发送的ACK响应,那么将从预提交状态进入到提交状态。并向所有参与者发送doCommit请求;
2)事务提交。参与者接收到doCommit请求之后,执行正式的事务提交。并在完成事务提交之后释放所有事务资源;
3)响应反馈。事务提交完之后,向协调者发送Ack响应;
4)完成事务。协调者接收到所有参与者的ack响应之后,完成事务。
中断事务 协调者没有接收到参与者发送的ACK响应(可能是接受者发送的不是ACK响应,也可能响应超时),那么就会执行中断事务。
1)发送中断请求。协调者向所有参与者发送abort请求;
2)事务回滚。参与者接收到abort请求之后,利用其在阶段二记录的undo信息来执行事务的回滚操作,并在完成回滚之后释放所有的事务资源;
3)反馈结果。参与者完成事务回滚之后,向协调者发送ACK消息;
4)中断事务。协调者接收到参与者反馈的ACK消息后,执行事务的中断。
相对于2PC,3PC主要解决的单点故障问题,并减少阻塞,因为一旦参与者无法及时收到来自协调者的信息之后,他会默认执行Commit。而不会一直持有事务资源并处于阻塞状态。但是这种机制也会导致数据一致性问题,因为,由于网络原因,协调者发送的abort响应没有及时被参与者接收到,那么参与者在等待超时之后执行了Commit操作。这样就和其他接到abort命令并执行回滚的参与者之间存在数据不一致的情况。
2.5 分布式一致性协议比较
综合考虑分布式一致性协议的发展历程和特性,可以发现它们之间存在着微妙的继承关系和相关性。比如Paxos算法融合了两阶段提交协议和Quorum算法的思想,通过Quorum算法W>N/2(W:参与更新操作的最小副本数;N:系统中的总副本数)的“多数派”思想来实现更新操作的互斥性,使得只有一个决议值会被“多数派”节点认可。两个阶段(提案阶段和接受阶段)的消息交互借鉴了两阶段提交的思路,保证多个节点之间更新操作的一致性。通过两轮信息交互,多数派达成一致的决议值,其状态一定是确定的(要么是已提交状态,要么是失败状态)。引入“多数派”的思想,减小了系统阻塞问题的发生概率,不需要确保系统中所有节点通信状况良好,只要保证至少存在多数派节点的通信状况正常,系统就是是可用的,“多数派”的策略一定程度上提高了系统的可用性。
相较于两阶段提交协议,Paxos增加了一种“学习者”角色,将“参与者”的功能一分为二,即“参与决策”交由“接受者”,“知晓决定”交由“学习者”。“接受者”和“学习者”的角色可以由同一节点来担任(此时等同于两阶段提交协议中的“参与者”),也可以由不同节点来承担。这种更灵活和细化的角色分工,使得“参与决策”和“知晓决定”两个功能彼此分开,从某种意义上减少系统阻塞的发生概率。
协议名称 | 解决的一致性问题 | 优点 | 缺点 | 应用分析 |
两阶段提交 | 状态一致性 | 提供了多节点之间的强一致性。 | 网络异常或是单节点故障会导致系统阻塞。 1.协调者宕机或提交阶段出现协调者与参与者之间的网络故障,此时参与者无法获知协调者的决定,只能持续等待,除非协调者恢复正常工作状态并且网络通信恢复,否则参与者将进入无限等待状态导致系统阻塞; 2.参与者宕机或预提交阶段出现协调者与参与者之间的网络故障,此时协调者不能确定某个参与者的状态,无法做出提交/撤销的决定,协调者将持续等待参与者恢复而导致系统阻塞。 | 需要系统处于良好的网络状态中,适用于对一致性要求较高的应用,是协调分布式事务原子性提交的经典协议。 |
Quorum | 多副本一致性 | 用户可根据实际的需求灵活配置NWR参数来实现不同级别的一致性。 | 不能保证多副本之间更新操作执行顺序的一致性,需要上层应用来协调冲突。 | 适用于对一致性要求不高的应用,比如购物车、朋友圈和图片分享等。 |
Paxos | 操作一致性、多副本一致性 | 可容忍少于半数的节点故障,可用性较高。 | 接受者可以承诺多个投票者、回复的内容可能是空值或是已经接收到的最大决议值,这些不确定的处理操作使得系统的未决状态较多,增大了工程实现的难度。 | 需要至少有多数派节点之间的网络通信状态良好,适用于对一致性要求较高的应用,支持多副本并发更新。 |
Raft | 操作一致性、多副本一致性 | 易于理解、相较于Paxos算法,工程实现难度较小。 | 网络分区情况下,容易出现“频繁选举”和“双领导者”的问题。 | 适用于无网络分区状况的分布式环境。 |
表1分布式一致性协议的特性简析
而Raft算法是Paxos算法的变种,使用更加严格的消息传递方式以及选举规则,使得算法更加易于理解和工程实现。Raft算法引入了选举期(term)的概念,用于标识从当前轮次的选举开始至下一轮选举开始的这段时期。每个选举期内,所有的伴随者只能投票给一个候选者,这种“先到先得”的投票规则,相较于Paxos算法中的接受者可以多次投票、每次需要回复已接收到的最大决议值的做法,要更加清晰和简单。
3 一致性协议在高可用分布式系统中的应用
实现分布式的强一致性和高可用性,需要引入分布式一致性协议,来协调分布式事务的提交(状态一致性)、多节点并发更新(操作一致性)和主备节点操作序列的同步(多副本一致性)。这些落实到具体系统中,需要实现“分布式事务提交”、“主节点选举”和“日志同步”三个模块。
3.1 应用概述
分布式事务的一致性提交,保证了分布式事务的原子性。分布式事务的相关节点需要就事务的最终状态(提交或失败)达成一致,不能出现某些节点局部提交事务的情况。如果违背了事务的原子性,状态一致性则无法保证。通用的分布式事务提交策略通过两阶段提交协议来实现,经过投票阶段和提交阶段的信息交互,使得协调者和参与者看到的事务最终状态是一致的。
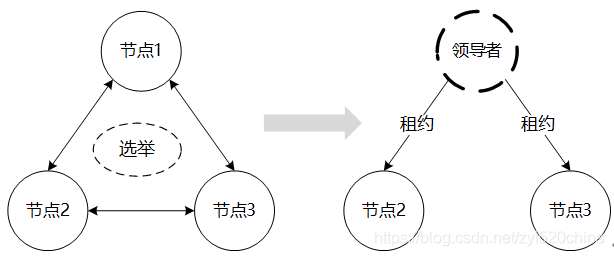
图5主节点选举
主节点的选举,指的是从系统中的所有节点中选取领导者,如图5所示。领导者可以是整个系统的管理者、主副本或是分布式事务的协调者。领导者往往是全局唯一的,并且能被所有节点感知到的节点,选领导者的问题是分布式节点就“领导者信息”达成一致的问题。根据选举规则的不同,选举可分为“不基于节点状态”和“基于节点状态”的两类。若领导者的选取,对节点的状态和功能无特殊要求,可选取任意活跃的节点成为领导者,选举则是“不基于节点状态”的。“不基于节点状态”的选举,可以采取Raft中“先到先得”,或是欺负算法和环算法[17]中“进程号最大优先”的策略来制定选举规则。若选举需要考量节点的状态,即对节点的状态、通信状况和功能等有一定的要求时,往往需要采取基于消息传递的一致性算法,比如Paxos算法,让竞选者通过消息交互,针对某些属性值进行较量,来进行选举。

图6日志同步
日志同步,或称为日志数据的复制用于主备节点之间同步更新操作的序列,如图3.2所示。主节点将更新操作以日志记录的方式发送给备份节点,备节点通过执行这些日志记录中的更新操作,达到和主节点一致的状态。主备节点的日志记录必须是相同和确定的,日志同步问题即是分布式节点就“每个日志号对应的日志内容”达成一致的问题。主备节点的日志同步,主要包括两种策略,立即复制(Eager replication)和延迟复制(Lazy replication)[18]。立即复制将同步到备机的操作并入事务的更新操作中,在立即复制模式下,主节点需要收到备份节点关于日志同步操作的回复之后,才能提交事务并答复客户端,确保已提交的事务在备节点中一定有相应的日志记录,实现主备节点之间的强一致性。在延迟复制的模式下,主节点执行更新操作,同时异步地向所有备机发送日志,主节点不用等到备机回复即可提交事务。
3.2 新型DBMS中分布式一致性的实现
为了实现系统的高可用性,分布式一致性协议已经被广泛地应用到很多成熟的分布式产品中,本节通过介绍Google Spanner和OceanBase系统中处理分布式事务、主节点选举和日志同步的设计思路,来分析新型分布式系统的高可用策略,并在表3-1中呈现结论。
Spanner[19]是由Google公司研发的一个全球分布式的、多版本、支持同步复制的可扩展分布式。采用两阶段提交协议来协调分布式事务的提交,主节点选举和日志同步都是基于Paxos算法的。Spanner以基于时间戳的方式实现了数据读写的全局一致性,在TrueTime API提供的精确时间戳的基础上,通过Paxos选举产生领导者来协调、管理事务提交的绝对时间和提交次序,进而保证数据的读写一致性。关于日志同步,主节点向多个备份节点同步redo日志,同步流程和Paxos的两个阶段类似,通过Paxos协议保证主备节点之间日志序列的确定性和一致性,从而保证数据在多个副本上是一致的。
OceanBase[20][21][22]是由阿里集团研发的支持海量数据、可扩展的高性能分布式。开源版本OceanBase0.4.2中,借助第三方软件Linux HA来进行主备切换,Linux HA通过心跳监控集群管理节点(集群管理节点是整个集群的管理者和协调者,管理系统中的所有节点,并维护元数据表的信息),一旦检测到主集群管理节点故障,Linux HA会将Vip漂移到备份的集群管理节点,来实现主备节点的切换。OceanBase0.4.2的日志同步使用的是主备复制的模型,日志同步发生在主备事务管理节点之间。OceanBase系统执行更新操作时,主事务管理节点需要将操作日志发送到备机,备份事务管理节点通过回放操作日志达到和主事务管理节点一致的分布式状态。OceanBase0.4.2同样是通过两阶段提交协议来协调分布式事务的提交。
4 总结与展望
分布式一致性协议是实现分布式系统高可用性的基础。本文梳理和分析了流行的分布式一致性协议的特点,并借助一些成熟的分布式系统来介绍生产实践中如何通过分布式一致性协议来实现分布式事务提交、主节点选举和日志同步。随着数据规模的不断扩大,使用分布式系统是必然的发展趋势。未来的研究工作,将基于学界和工业界已有的分布式一致性理论和成熟的分布式产品,探究并设计普适和完整的高可用方案来解决分布式系统中的一致性和可用性问题。
参考文献
- Lampson B W. How to build a highly available system using consensus [J]. In Distributed Algorithms, O. Baboaglu and K. Marzullo, Eds. Springer-Verlag, 1996, pp. 1–17.
- CAP定理[EB/OL].http://zh.wikipedia.org/zh-cn/CAP定理.
- 浅谈分布式系统的基本问题:可用性与一致性[EB/OL].https://yq.aliyun.com/articles/2709.
- Pritchett D. BASE: An Acid Alternative[J]. 2008.
- Gray J. Notes on data base operating systems [J]. In Operating Systems-An Advanced Cource, Lecture Notes in Computer Science, vol. 60. Springer-Verlag. New York.1978.
- C. Mohan, Bruce Lindsay and R. Obermarck. Transaction management in the R* distributed database management system [C],ACM Transactions on Database Systems(TODS), Volume 11 Issue 4, Dec. 1986, Pages 378 - 396.
- B. Lampson and D. Lomet. A New Presumed Commit Optimization for Two Phase Commit [C]. Proc. Int’l Conf. Very Large Data Bases, pp. 630-640, 1993.
- Lamport L. Paxos made simple [J]. ACM SIGACT News, 2001, 32(4): 18—25.
- Chandra T. Griesemer R. Redstone J. Paxos made live [J]. PODC '07: 26th ACM Symposium on Principles of Distributed Computing, 2007.
- Lamport L. The part-time parliament [J]. ACM Transactions on Computer Systems 16, 2(May 1998), 133–169.
- D. Skeen, Nonblocking Commit Protocols [C], Proc. ACM SIGMOD Conf on Management of Data, pp.133-147, Orlando, FL, June 1982.
- David K. Gifford. Weighted Voting for Replicated Data [C].ACM 1979.
- Lamport L. Mike M.Cheap Paxos[J]. Proceedings of theInternational Conference on Dependable Systems and Networks (DSN 2004).
- Lamport L. Fast Paxos [J]. Distributed Computing 19, 2(October 2006)79-103.
- L. Lamport, D. Malkhi, and L. Zhou. Vertical paxos and primary-backup replication [C]. Technical Report MSR-TR-2009-63, Microsoft Research, 2009.
- Ongaro D, Ousterhout J. In search of an understandable consensus algorithm [J]. In Proc ATC’14,USENIX Annual Technical Conference(2014), USENIX.
- Coulouris G, Dollimore J, Kindberg T. et al. Distrinbuted Systems Concepts and Design [M].第5版.机械工业出版社,2015:378-380.
- Gray J. Helland P. Neil P O. et al. The Dangers of Replication and a Solution [J]. 1996 ACM SIGMOD Conference at Montreal, pp. 173-182
- J Corbett J C, Dean J, Epstein M. et al. Spanner: Google's globally distributed database [J]. In Proceedings of the 5th Biennial Conference on Innovative Data Systems Research(CIDR ’11)January 9-12, 2011, Asilomar, California, USA.
- 阳振坤.OceanBase关系分布式架构[J].华东师范大学学报(自然科学版). 2014-09-25.
- OceanBase [EB/OL], http://alibaba.github.io/oceanbase/.
- 杨传辉.OceanBase高可用方案[J].华东师范大学学报(自然科学版),2014-09-25.