Redis
本篇文章主要讲解:订阅发布,主从复制,哨兵模式,缓存穿透、击穿、雪崩
文章目录
一、Redis订阅发布
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
例如:微信公众号的关注
订阅/发布消息图: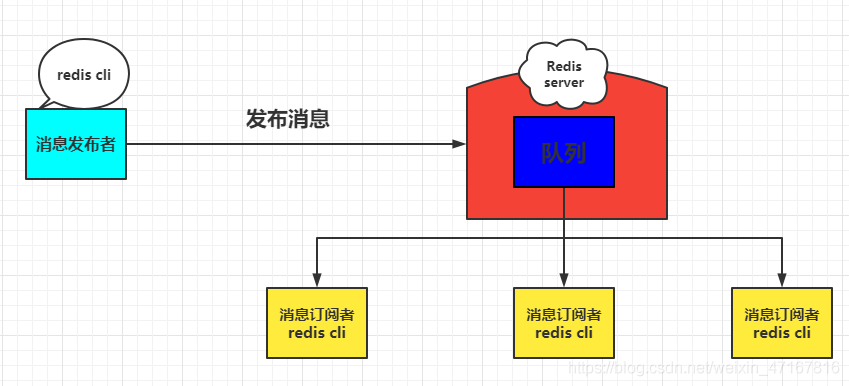
命令描述
- PSUBSCRIBE pattern [pattern…] 订阅一个或多个符合给定模式的频道。
- PUNSUBSCRIBE pattern [pattern…] 退订一个或多个符合给定模式的频道。
- PUBSUB subcommand [argument[argument]] 查看订阅与发布系统状态。
- PUBLISH channel message 向指定频道发布消息
- SUBSCRIBE channel [channel…] 订阅给定的一个或多个频道。
- SUBSCRIBE channel [channel…] 退订一个或多个频道
测试
订阅端:
127.0.0.1:6379> subscribe guhuixiang //订阅一个频道 guhuixiang
Reading messages... (press Ctrl-C to quit)
//等待读取信息
1) "subscribe"
2) "guhuixiang"
3) (integer) 1
1) "message" //消息
2) "guhuixiang" //哪个频道的消息
3) "nb,guhuixang" //消息具体内容
发送端:
127.0.0.1:6379> publish guhuixiang "nb,guhuixang" //发布者发布消息到频道
(integer) 1
比如我们关注一个人,假如我们要看到他发的消息,首先我们必须要关注他,然后只要他一发送动态或者文章我们便可以看到它发的消息。
消息订阅:公众号订阅,微博关注等等
图解:
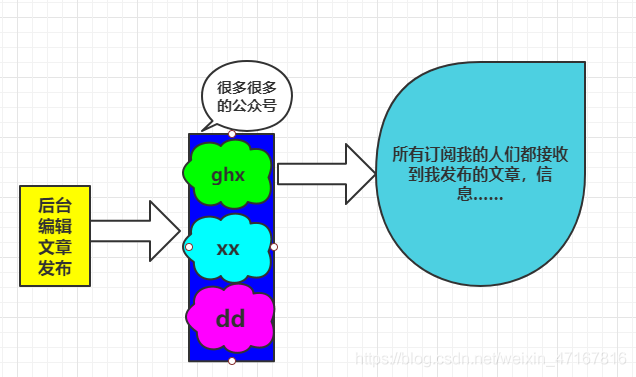
原理
Pub/Sub从字面上理解就是发布( Publigh )与订阅( Subscribe ),在Redis中,你可以设定对某一个key值进行消息发布及消息订阅,当一个key值上进行了消息发布后,所有订阅它的客户端都会收到相应的消息。这一功能最明显的用法就是用作实时消息系统,比如普通的即时聊天,群聊等功能。
二、Redis主从复制(redis的集群环境)
主从复制,读写分离,在大多数情况下是在进行读操作,减缓服务器的压力,架构中经常使用!一主二从
为什么要使用集群:
1.单台服务器难以负载大量的请求
2.单台服务器故障率高,系统崩坏概率大
3.单台服务器内存容量有限。
概念:
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master/leader),后者称为从节点(slave/follower);数据的复制是单向的,只能由主节点到从节点。Master以写为主,Slave以读为主。
默认情况下,每台Redis服务器都是主节点;且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点(一个爸爸可以有多个儿子,而一个儿子不可能有多个爸爸)。
主从复制的作用主要包括:
- 数据冗余∶主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复︰当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
- 负载均衡︰在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
- 高可用(集群)基石∶除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
环境配置
只配置从库,不用配置主库
127.0.0.1:6379> info replication //查看当前库的信息
# Replication
role:master //角色 master
connected_slaves:0 //没有从机
master_failover_state:no-failover
master_replid:6c320bb3f460a6b53cc054def29509fb35c56932
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
复制3个redis.conf配置文件
[root@localhost gconfig]# ls
redis.conf
[root@localhost gconfig]# cp redis.conf redis80.conf
[root@localhost gconfig]# cp redis.conf redis81.conf
[root@localhost gconfig]# cp redis.conf redis82.conf
进行redis.conf配置文件更改
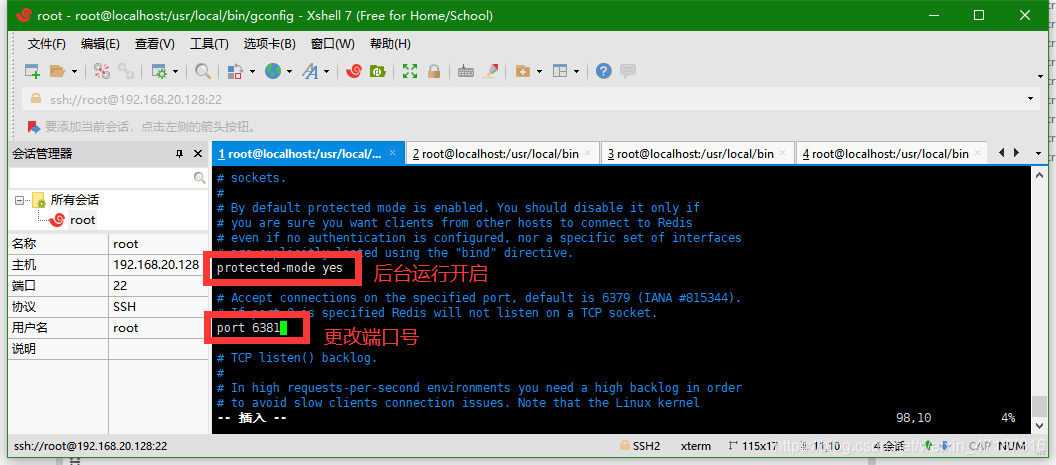
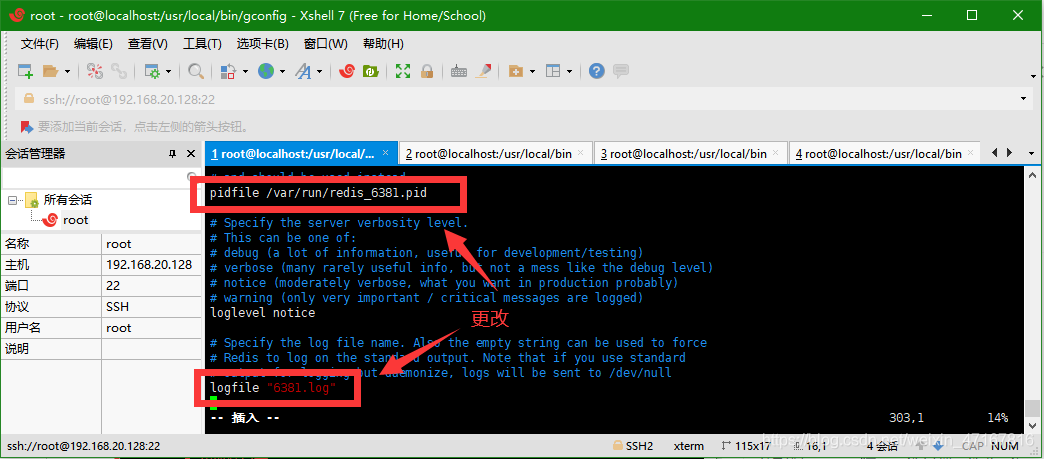
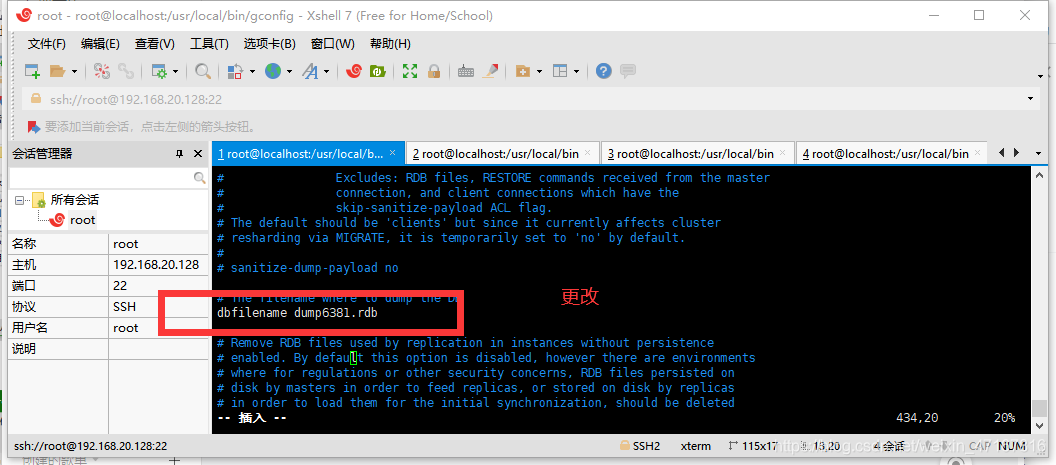
启动3个redis配置
> 启动成功:
root@localhost bin]# redis-server gconfig/redis79.conf
[root@localhost bin]# redis-server gconfig/redis80.conf
[root@localhost bin]# redis-server gconfig/redis81.conf
[root@localhost bin]# ps -ef|grep redis
root 5012 1 0 14:03 ? 00:00:13 redis-server 127.0.0.1:6379
root 11564 1 0 15:54 ? 00:00:00 redis-server 127.0.0.1:6380
root 11586 1 1 15:55 ? 00:00:00 redis-server 127.0.0.1:6381
一主二从
默认情况下,每台redis服务器都是主节点
一般情况下只配置从机就好啦,一个主机(6379),二从机(6380,6381)
全部启动(6379,6380,6381)
6379:
root@localhost bin]# redis-cli -p 6379
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:6c320bb3f460a6b53cc054def29509fb35c56932
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6379>
6380:
[root@localhost bin]# redis-cli -p 6380
127.0.0.1:6380> ping
PONG
127.0.0.1:6380> info replication
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:3685ea167b25d316b88df80fdbc3600078bed3fc
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6380>
6381:
[root@localhost bin]# redis-cli -p 6381
127.0.0.1:6381> ping
PONG
127.0.0.1:6381> info replication
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:4620daf010467de87a0475a353ac2bbe15a8f3e4
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6381>
认主(6379主)
slaveof host 端口号 #认主
6380:
127.0.0.1:6380> slaveof 127.0.0.1 6379
OK
127.0.0.1:6380> info replication
# Replication
role:slave //当前角色为从机
master_host:127.0.0.1 //可以看到主机信息
master_port:6379 //可以看到主机信息
master_link_status:up
master_last_io_seconds_ago:10
master_sync_in_progress:0
slave_repl_offset:42
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:7d09f58566516db5bdde30589fc338c22f22dc6e
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:42
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:42:
6381:
127.0.0.1:6381> slaveof 127.0.0.1 6379
OK
127.0.0.1:6381> info replication
# Replication
role:slave //当前角色为从机
master_host:127.0.0.1 //可以看到主机信息
master_port:6379 //可以看到主机信息
master_link_status:up
master_last_io_seconds_ago:2
master_sync_in_progress:0
slave_repl_offset:70
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:7d09f58566516db5bdde30589fc338c22f22dc6e
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:70
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:29
repl_backlog_histlen:42
在主机中查看(6379):
127.0.0.1:6379> ifno replication
(error) ERR unknown command `ifno`, with args beginning with: `replication`,
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2 //多了从机的配置
slave0:ip=127.0.0.1,port=6380,state=online,offset=112,lag=1 //每台从机的信息
slave1:ip=127.0.0.1,port=6381,state=online,offset=112,lag=0 //每台从机的信息
master_failover_state:no-failover
master_replid:7d09f58566516db5bdde30589fc338c22f22dc6e
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:112
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:112
真实的主从复制是在我们的redis.conf配置文件中配置(永久的)
这里我们用的命令(暂时的)
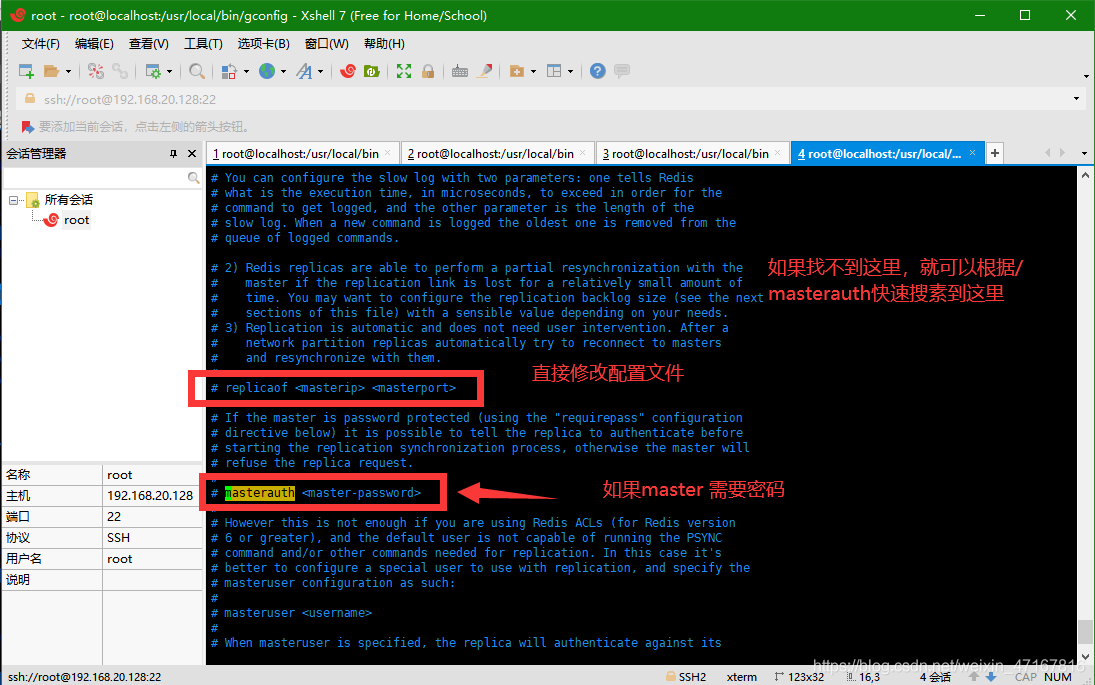
主机负责写(主机可以读也可以写),从机负责读(只能读)
主机中的所有数据和信息都会自动被从机保存
主机断开或者宕机,从机依旧连接到主机的数据
如果使用命令行,来配置的主从,如果我们这个时候重启了,就会变成主机,只要变成从机,立马就会从主机中获取值
复制原理:
Slave启动成功连接到master后会发送一个sync同步命令
Master 接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,并完成一次完全同步。
全量复制︰而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。(当我们变为从机的时候)
增量复制:Master继续将新的所有收集到的修改命令依次传给slave,完成同步(每当我们主机添加数据的时候会使用增量复制给我们的从机)
但是只要是重新连接master,一次完全同步(全量复制)将被自动执行,我们在从机中也可以看到
如果我们的主机宕机,或者断开连接(slaveof no one)让自己变成主机
127.0.0.1:6381> slaveof no one
OK
127.0.0.1:6381> info replication
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:59a562f79fab78a4c74a5bf3b1da149eadc454c6
master_replid2:7d09f58566516db5bdde30589fc338c22f22dc6e
master_repl_offset:7702
second_repl_offset:7703
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:29
repl_backlog_histlen:7674
哨兵模式
概述:
主从切换技术的方法是︰当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式。Redis从2.8开始正式提供了Sentinel (哨兵)架构来解决这个问题。谋朝篡位的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库。
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理<>是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
单机哨兵: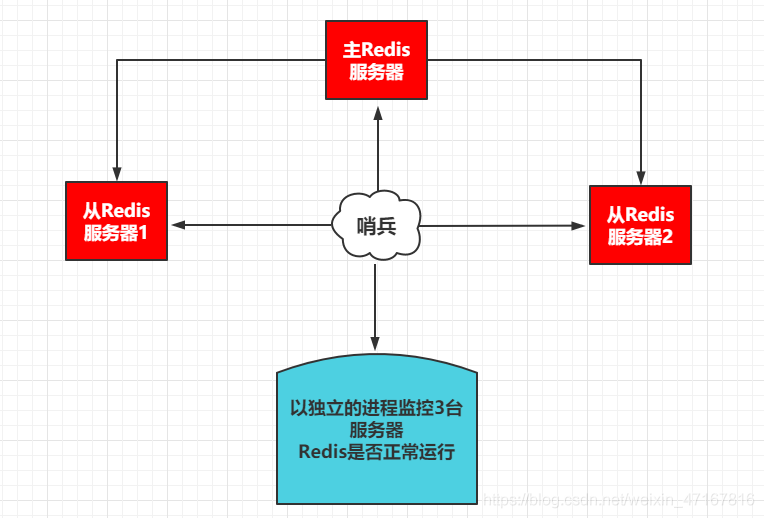
这里的哨兵有两个作用
- 通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器。
- 当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机。
然而一个哨兵进程对Redis服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。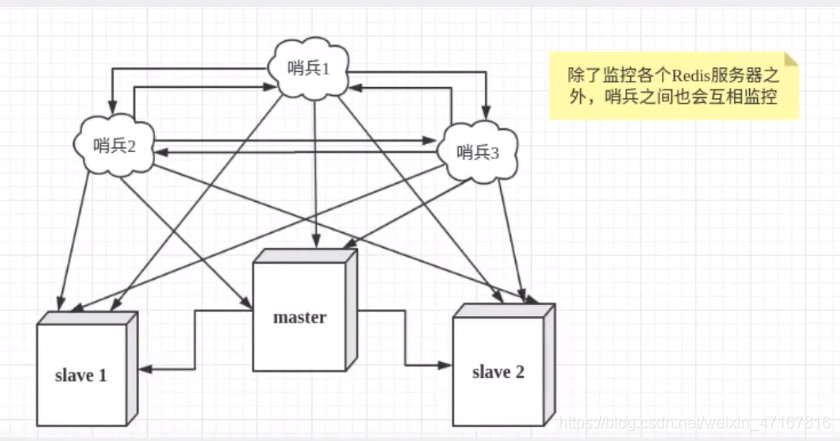
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover(选举故障)过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover[故障转移]操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线。
配置哨兵配置文件(一主二从)
配置哨兵配置文件sentinel.conf
// sentinel monitor 被监视的名称 host port 1
sentinel monitor myredis 127.0.0.1 6379 1
//后面这个数字,代表主机挂了,slave投票看让谁接替成为主机,票数最多的,就会成为主机
启动哨兵
[root@localhost bin]# redis-sentinel gconfig/sentinel.conf
23492:X 27 Jun 2021 23:00:19.531 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
23492:X 27 Jun 2021 23:00:19.531 # Redis version=6.2.4, bits=64, commit=00000000, modified=0, pid=23492, just started
23492:X 27 Jun 2021 23:00:19.531 # Configuration loaded
23492:X 27 Jun 2021 23:00:19.533 * Increased maximum number of open files to 10032 (it was originally set to 1024).
23492:X 27 Jun 2021 23:00:19.533 * monotonic clock: POSIX clock_gettime
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 6.2.4 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in sentinel mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 26379
| `-._ `._ / _.-' | PID: 23492
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | https://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
23492:X 27 Jun 2021 23:00:19.659 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
23492:X 27 Jun 2021 23:00:19.672 # Sentinel ID is b8c8e6ec25a1f98e2a0777e8756220251b06f709
23492:X 27 Jun 2021 23:00:19.672 # +monitor master myredis 127.0.0.1 6379 quorum 1
23492:X 27 Jun 2021 23:00:19.723 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ myredis 127.0.0.1 6379
23492:X 27 Jun 2021 23:00:19.735 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ myredis 127.0.0.1 6379
假如我们的主机宕机或者断开连接时
23492:X 27 Jun 2021 23:06:52.104 # +sdown master myredis 127.0.0.1 6379
23492:X 27 Jun 2021 23:06:52.104 # +odown master myredis 127.0.0.1 6379 #quorum 1/1
23492:X 27 Jun 2021 23:06:52.104 # +new-epoch 1
23492:X 27 Jun 2021 23:06:52.104 # +try-failover master myredis 127.0.0.1 6379
23492:X 27 Jun 2021 23:06:52.229 # +vote-for-leader b8c8e6ec25a1f98e2a0777e8756220251b06f709 1
23492:X 27 Jun 2021 23:06:52.229 # +elected-leader master myredis 127.0.0.1 6379
23492:X 27 Jun 2021 23:06:52.229 # +failover-state-select-slave master myredis 127.0.0.1 6379
23492:X 27 Jun 2021 23:06:52.292 # +selected-slave slave 127.0.0.1:6380 127.0.0.1 6380 @ myredis 127.0.0.1 6379
23492:X 27 Jun 2021 23:06:52.292 * +failover-state-send-slaveof-noone slave 127.0.0.1:6380 127.0.0.1 6380 @ myredis 127.0.0.1 6379
23492:X 27 Jun 2021 23:06:52.344 * +failover-state-wait-promotion slave 127.0.0.1:6380 127.0.0.1 6380 @ myredis 127.0.0.1 6379
23492:X 27 Jun 2021 23:06:53.110 # +promoted-slave slave 127.0.0.1:6380 127.0.0.1 6380 @ myredis 127.0.0.1 6379
23492:X 27 Jun 2021 23:06:53.110 # +failover-state-reconf-slaves master myredis 127.0.0.1 6379
23492:X 27 Jun 2021 23:06:53.182 * +slave-reconf-sent slave 127.0.0.1:6381 127.0.0.1 6381 @ myredis 127.0.0.1 6379
23492:X 27 Jun 2021 23:06:54.086 * +slave-reconf-inprog slave 127.0.0.1:6381 127.0.0.1 6381 @ myredis 127.0.0.1 6379
23492:X 27 Jun 2021 23:06:54.086 * +slave-reconf-done slave 127.0.0.1:6381 127.0.0.1 6381 @ myredis 127.0.0.1 6379
23492:X 27 Jun 2021 23:06:54.186 # +failover-end master myredis 127.0.0.1 6379
23492:X 27 Jun 2021 23:06:54.186 # +switch-master myredis 127.0.0.1 6379 127.0.0.1 6380
23492:X 27 Jun 2021 23:06:54.187 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ myredis 127.0.0.1 6380
23492:X 27 Jun 2021 23:06:54.187 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ myredis 127.0.0.1 6380
23492:X 27 Jun 2021 23:07:24.253 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ myredis 127.0.0.1 6380 //新的主机6380
自动给我们选举新的主机
此时我们的6380变为我们的主机
127.0.0.1:6380> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6381,state=online,offset=40512,lag=1
master_failover_state:no-failover
master_replid:0948d11cbf400a53f8bfaea5e1fe7e61446bda83
master_replid2:7d09f58566516db5bdde30589fc338c22f22dc6e
master_repl_offset:40512
second_repl_offset:39288
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:40512
127.0.0.1:6380>
如果主机回来了,那么也只能作为我们新的主机的从机
127.0.0.1:6379> info replication
# Replication
role:slave //6379变为从机
master_host:127.0.0.1
master_port:6380 //6380为6379的主机
master_link_status:up
master_last_io_seconds_ago:0
master_sync_in_progress:0
slave_repl_offset:75729
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:0948d11cbf400a53f8bfaea5e1fe7e61446bda83
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:75729
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:75165
repl_backlog_histlen:565
哨兵模式优缺点
- 优点:
1、哨兵集群,基于主从复制模式,所有的主从配置优点,它全有
2、主从可以切换,故障可以转移,系统的可用性就会更好
3、哨兵模式就是主从模式的升级,手动到自动,更加健壮 - 缺点:
1、Redis 不好啊在线扩容的,集群容量一旦到达上限,在线扩容就十分麻烦
2、实现哨兵模式的配置其实是很麻烦
完整的哨兵模式配置文件 sentinel.conf
# Example sentinel.conf
# 哨兵sentinel实例运行的端口 默认26379 多个哨兵配置多个端口号
port 26379
# 哨兵sentinel的工作目录
dir /tmp
# 哨兵sentinel监控的redis主节点的 ip port
# master-name 可以自己命名的主节点名字 只能由字母A-z、数字0-9 、这三个字符".-_"组成。
# quorum 当这些quorum个数sentinel哨兵认为master主节点失联 那么这时 客观上认为主节点失联了
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
sentinel monitor mymaster 127.0.0.1 6379 1
# 当在Redis实例中开启了requirepass foobared 授权密码 这样所有连接Redis实例的客户端都要提供密码
# 设置哨兵sentinel 连接主从的密码 注意必须为主从设置一样的验证密码
# sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster MySUPER--secret-0123passw0rd
# 指定多少毫秒之后 主节点没有应答哨兵sentinel 此时 哨兵主观上认为主节点下线 默认30秒
# sentinel down-after-milliseconds <master-name> <milliseconds>
sentinel down-after-milliseconds mymaster 30000
# 这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同步,
这个数字越小,完成failover所需的时间就越长,
但是如果这个数字越大,就意味着越 多的slave因为replication而不可用。
可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。
# sentinel parallel-syncs <master-name> <numslaves>
sentinel parallel-syncs mymaster 1
# 故障转移的超时时间 failover-timeout 可以用在以下这些方面:
#1. 同一个sentinel对同一个master两次failover之间的间隔时间。
#2. 当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那里同步数据时。
#3.当想要取消一个正在进行的failover所需要的时间。
#4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了
# 默认三分钟
# sentinel failover-timeout <master-name> <milliseconds>
sentinel failover-timeout mymaster 180000
# SCRIPTS EXECUTION
#配置当某一事件发生时所需要执行的脚本,可以通过脚本来通知管理员,例如当系统运行不正常时发邮件通知相关人员。
#对于脚本的运行结果有以下规则:
#若脚本执行后返回1,那么该脚本稍后将会被再次执行,重复次数目前默认为10
#若脚本执行后返回2,或者比2更高的一个返回值,脚本将不会重复执行。
#如果脚本在执行过程中由于收到系统中断信号被终止了,则同返回值为1时的行为相同。
#一个脚本的最大执行时间为60s,如果超过这个时间,脚本将会被一个SIGKILL信号终止,之后重新执行。
#通知型脚本:当sentinel有任何警告级别的事件发生时(比如说redis实例的主观失效和客观失效等等),将会去调用这个脚本,
#这时这个脚本应该通过邮件,SMS等方式去通知系统管理员关于系统不正常运行的信息。调用该脚本时,将传给脚本两个参数,
#一个是事件的类型,
#一个是事件的描述。
#如果sentinel.conf配置文件中配置了这个脚本路径,那么必须保证这个脚本存在于这个路径,并且是可执行的,否则sentinel无法正常启动成功。
#通知脚本
#shell编程
# sentinel notification-script <master-name> <script-path>
sentinel notification-script mymaster /var/redis/notify.sh
# 客户端重新配置主节点参数脚本
# 当一个master由于failover而发生改变时,这个脚本将会被调用,通知相关的客户端关于master地址已经发生改变的信息。
# 以下参数将会在调用脚本时传给脚本:
# <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>
# 目前<state>总是“failover”,
# <role>是“leader”或者“observer”中的一个。
# 参数 from-ip, from-port, to-ip, to-port是用来和旧的master和新的master(即旧的slave)通信的
# 这个脚本应该是通用的,能被多次调用,不是针对性的。
# sentinel client-reconfig-script <master-name> <script-path>
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh
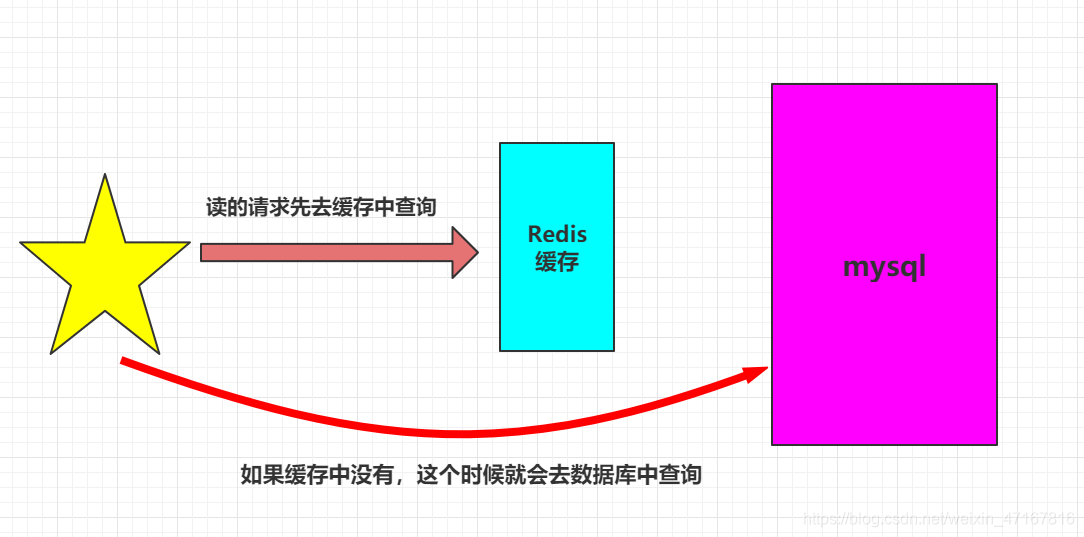
redis的缓存穿透缓和存击穿与缓存雪崩(高可用问题,三高)
缓存穿透(查不到)
概念:
在默认情况下,用户请求数据时,会先在缓存(Redis)中查找,若没找到即缓存未命中,再在数据库中进行查找,数量少可能问题不大,可是一旦大量的请求数据(例如秒杀场景)缓存都没有命中的话,就会全部转移到数据库上,造成数据库极大的压力,就有可能导致数据库崩溃。网络安全中也有人恶意使用这种手段进行攻击被称为洪水攻击。
解决方案
- 布隆过滤器: 对所有可能查询的参数以Hash的形式存储,以便快速确定是否存在这个值,在控制层先进行拦截校验,校验不通过直接打回,减轻了存储系统的压力。
- 缓存空对象: 一次请求若在缓存和数据库中都没找到,就在缓存中方一个空对象用于处理后续这个请求。
存在的问题:
- 存在的问题 :
- 如果空值能够被缓存起来,这就意味着缓存需要更多的空间存储更多的键,因为这当中可能会有很多的空值的键。
- 即使对空值设置了过期时间,还是会存在 缓存层和存储层 的数据会有一段时间窗口的不一致的问题,对于需要保持一致性的业务会有影响。
缓存击穿(查的量大,缓存过期)
概念:
相较于缓存穿透,缓存击穿的目的性更强,一个存在的key,在缓存过期的一刻,同时有大量的请求,这些请求都会击穿到DB,造成瞬时DB请求量大、压力骤增。这就是缓存被击穿,只是针对其中某个key的缓存不可用而导致击穿,但是其他的key依然可以使用缓存响应。比如热搜排行上,一个热点新闻被同时大量访问就可能导致缓存击穿。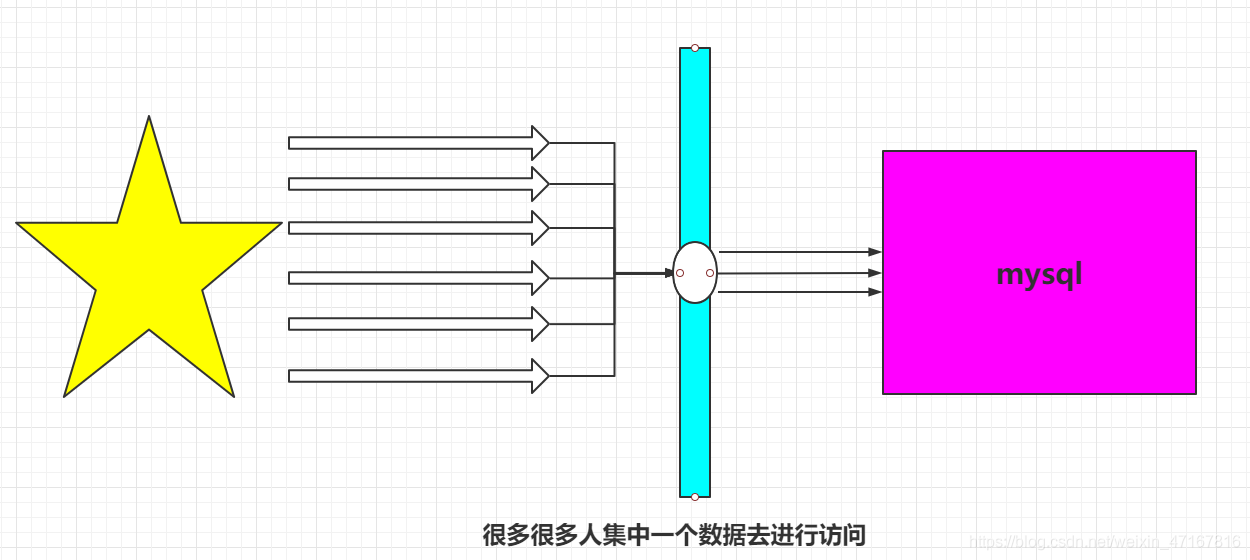
解决方案:
设置热点数据永不过期
这样就不会出现热点数据过期的情况,但是当Redis内存空间满的时候也会清理部分数据,而且此种方案会占用空间,一旦热点数据多了起来,就会占用部分空间。加互斥锁(分布式锁)
在访问key之前,采用SETNX(set if not exists)来设置另一个短期key来锁住当前key的访问,访问结束再删除该短期key。保证同时刻只有一个线程访问。这样对锁的要求就十分高。**
缓存雪崩
概念:
缓存雪崩,是指在某一个时间段,缓存集中过期失效。Redis 宕机
大量的key设置了相同的过期时间 或者 Redis 服务器宕机,导致在缓存在同一时刻全部失效,造成瞬时DB请求量大、压力骤增,引起雪崩。
产生雪崩的原因之一,比如在写本文的时候,马上就要到双十二零点,很快就会迎来一波抢购,这波商品时间比较集中的放入了缓存,假设缓存一个小时。那么到了凌晨一点钟的时候,这批商品的缓存就都过期了。而对这批商品的访问查询,都落到了数据库上,对于数据库而言,就会产生周期性的压力波峰。于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。
解决方案:
- redis高可用
这个思想的含义是,既然redis有可能挂掉,那我多增设几台redis,这样一台挂掉之后其他的还可以继续工作,其实就是搭建的集群 - 限流降级
这个解决方案的思想是,在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。 - 数据预热
数据加热的含义就是在正式部署之前,我先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中。在即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。