0.写在前面
项目地址(GitHub):FlinkStreamETL
需求描述:利用Flink实时计算Mysql数据中的增量数据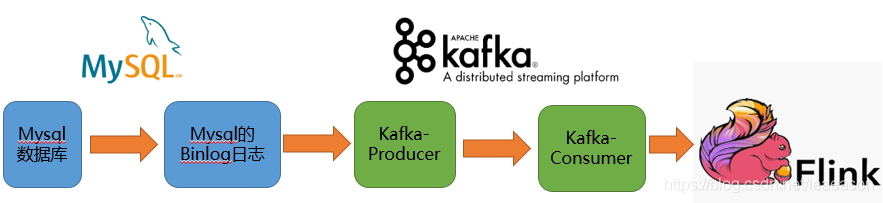
方案:利用Canal实时读取Mysql数据库的Binlog日志,将其作为Kafka的生产者(Producer);然后利用Flink作为kafka的消费者(Consumer),读取Kafka中的数据。目前只是读取kafka中的数据,为Json格式,后面需要根据业务需求编写实时计算逻辑
所用的版本 —>服务器:
Kafka:Kafka 2.1.0-cdh6.2.0
Flink:<flink.version>1.9.0</flink.version>
Java:<java.version>1.8</java.version>
所用的版本 —>本机上:
Flink:<flink.version>1.9.0</flink.version>
Scala:<scala.binary.version>2.12</scala.binary.version>
Java:<java.version>1.8</java.version>
Kafka:flink-connector-kafka_${scala.binary.version}(Scala版本是2.12)
1.创建Maven项目
mvn archetype:generate
-DarchetypeGroupId=org.apache.flink
-DarchetypeArtifactId=flink-quickstart-java
-DarchetypeVersion=1.9.0
-DgroupId=flink-connector-kafka
-DartifactId=flink-connector-kafka
-Dversion=0.1
-Dpackage=myflink
-DinteractiveMode=false
pom文件
<!--
Licensed to the Apache Software Foundation (ASF) under one
or more contributor license agreements. See the NOTICE file
distributed with this work for additional information
regarding copyright ownership. The ASF licenses this file
to you under the Apache License, Version 2.0 (the
"License"); you may not use this file except in compliance
with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing,
software distributed under the License is distributed on an
"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
KIND, either express or implied. See the License for the
specific language governing permissions and limitations
under the License.
-->
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>flink-connector-kafka</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>0.1</version>
<packaging>jar</packaging>
<name>Flink Quickstart Job</name>
<url>http://www.myorganization.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.9.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
</properties>
<repositories>
<repository>
<id>apache.snapshots</id>
<name>Apache Development Snapshot Repository</name>
<url>https://repository.apache.org/content/repositories/snapshots/</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
<dependencies>
<!-- Apache Flink dependencies -->
<!-- These dependencies are provided, because they should not be packaged into the JAR file. -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- Flink-Kafka-Connector. -->
<!-- <dependency>-->
<!-- <groupId>org.apache.flink</groupId>-->
<!-- <artifactId>flink-connector-kafka-0.11_${scala.binary.version}</artifactId>-->
<!-- <version>${flink.version}</version>-->
<!-- </dependency>-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- Add connector dependencies here. They must be in the default scope (compile). -->
<!-- Example:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.10_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
-->
<!-- Add logging framework, to produce console output when running in the IDE. -->
<!-- These dependencies are excluded from the application JAR by default. -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
<scope>runtime</scope>
</dependency>
</dependencies>
<build>
<plugins>
<!-- Java Compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
</configuration>
</plugin>
<!-- We use the maven-shade plugin to create a fat jar that contains all necessary dependencies. -->
<!-- Change the value of <mainClass>...</mainClass> if your program entry point changes. -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.0.0</version>
<executions>
<!-- Run shade goal on package phase -->
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>org.apache.flink:force-shading</exclude>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>myflink.StreamingJob</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
<pluginManagement>
<plugins>
<!-- This improves the out-of-the-box experience in Eclipse by resolving some warnings. -->
<plugin>
<groupId>org.eclipse.m2e</groupId>
<artifactId>lifecycle-mapping</artifactId>
<version>1.0.0</version>
<configuration>
<lifecycleMappingMetadata>
<pluginExecutions>
<pluginExecution>
<pluginExecutionFilter>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<versionRange>[3.0.0,)</versionRange>
<goals>
<goal>shade</goal>
</goals>
</pluginExecutionFilter>
<action>
<ignore/>
</action>
</pluginExecution>
<pluginExecution>
<pluginExecutionFilter>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<versionRange>[3.1,)</versionRange>
<goals>
<goal>testCompile</goal>
<goal>compile</goal>
</goals>
</pluginExecutionFilter>
<action>
<ignore/>
</action>
</pluginExecution>
</pluginExecutions>
</lifecycleMappingMetadata>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
<!-- This profile helps to make things run out of the box in IntelliJ -->
<!-- Its adds Flink's core classes to the runtime class path. -->
<!-- Otherwise they are missing in IntelliJ, because the dependency is 'provided' -->
<profiles>
<profile>
<id>add-dependencies-for-IDEA</id>
<activation>
<property>
<name>idea.version</name>
</property>
</activation>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>compile</scope>
</dependency>
</dependencies>
</profile>
</profiles>
</project>
2.Java代码
package myflink;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import java.util.Properties;
import java.util.stream.Stream;
import static org.apache.flink.streaming.api.TimeCharacteristic.*;
public class Main {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment Env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "master:9092,slave01:9092,slave02:9092");
properties.setProperty("zookeeper.connect", "master:2181,slave01:2181,slave02:2181");
properties.setProperty("group.id", "example_group");
FlinkKafkaConsumer<String> myConsumer = new FlinkKafkaConsumer<String>("example",new SimpleStringSchema(),properties);
myConsumer.setStartFromLatest();
myConsumer.setStartFromGroupOffsets();
Env.setParallelism(2).setStreamTimeCharacteristic(EventTime);
DataStream<Tuple2<String,Integer>> stream = Env.addSource(myConsumer)
.flatMap((String lines, Collector<Tuple2<String,Integer>> out) ->
Stream.of(lines.split(","))
.forEach(a -> out.collect(Tuple2.of(a,1))))
.returns(Types.TUPLE(Types.STRING,Types.INT))
.keyBy(0)
//.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.sum(1)
;
//stream.writeAsText("C:\\Users\\yaowentao\\Desktop\\a");
stream.print();
Env.execute("my first stream flink");
}
}
3.运行示例
- 开启Canal
$CANAL_HOME/bin/startup.sh ## 在canal安装目录下的logs文件夹会下生成两个日志文件:logs/canal/canal.log、logs/example/example.log,查看这两个日志,保证没有报错日志。 tail -f $CANAL_HOME/logs/example/example.log tail -f $CANAL_HOME/logs/canal/canal.log

向Mysql数据库中写入数据
## 开启服务 service mysqld start ##插入两条数据

利用Kafka-Consumer进行查看
kafka-console-consumer --bootstrap-server master:9092,slave01:9092,slave02:9092 --topic example --from-beginning利用IDEA中进行查看
## IDEA中的输出 ## 现在是JSON格式的数据,后面需要对JSON格式的日志进行解析,做逻辑处理。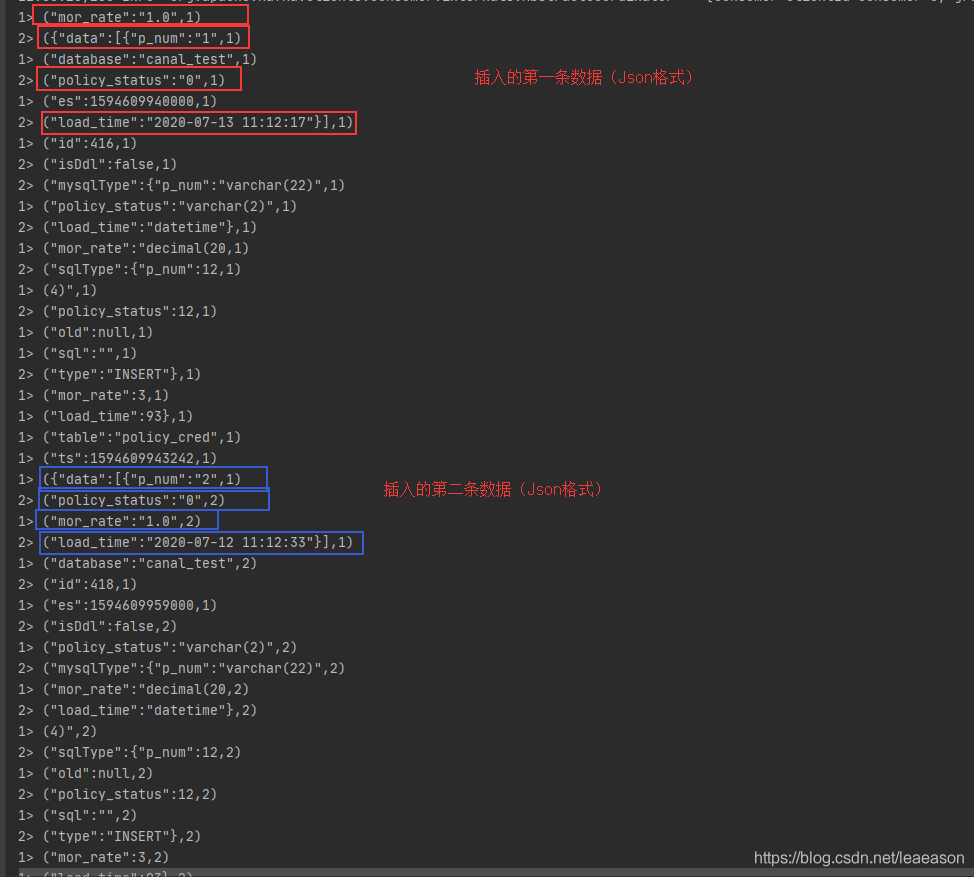
将项目打成Jar包,上传到FlinkWeb上
## 在本机项目的pom所在路径下,执行下面的Maven命令 mvn clean package -Dmaven.test.skip=true -U
## 将target路径下的flink-connector-kafka-0.1.jar上传到WebUI
## Flink的WebUI是:master:8081,master是我的服务器主机名
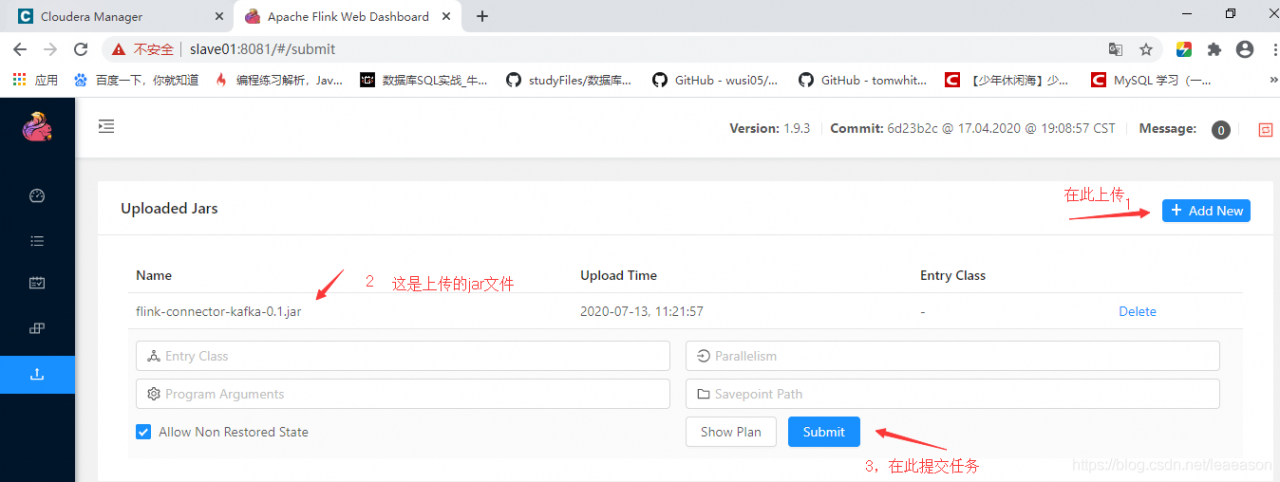
遇到的问题
点击Submit之后,执行报错
报错截图如下
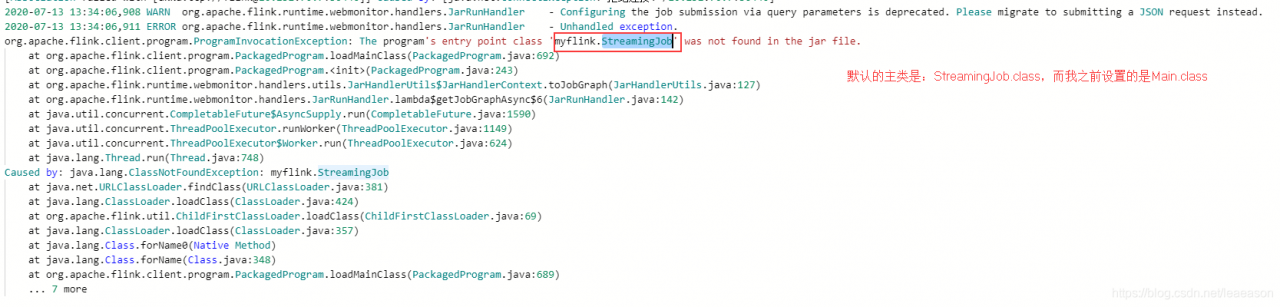
重新编写一个主类:StreamingJob.class,只改主类名即可,其他不需要改结果展示

点击Submit,查看正在执行的任务
查看输出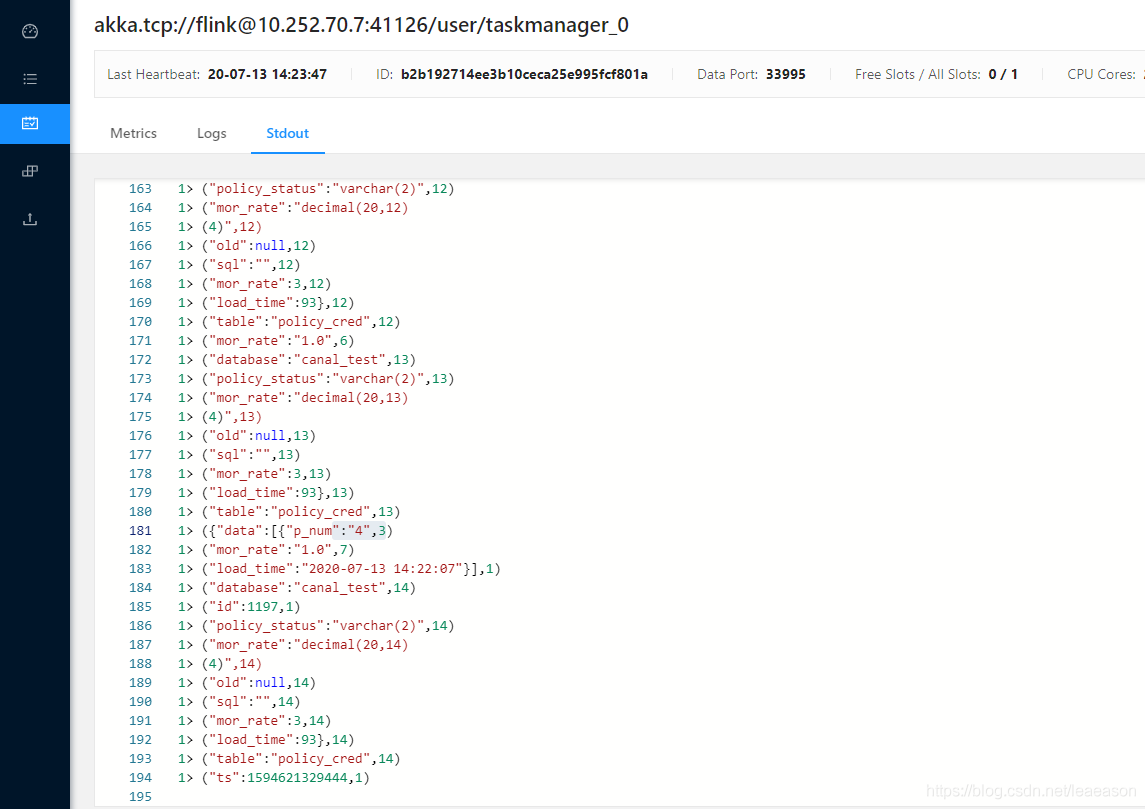
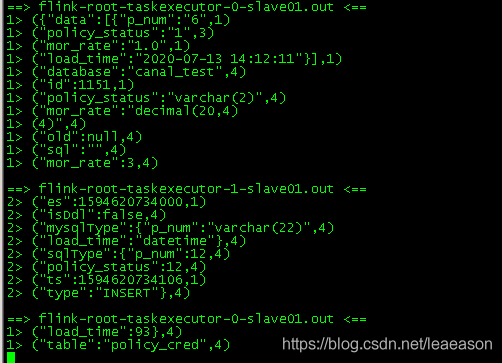
在服务器查看后台日志
cd /opt/softwares/flink-1.9.3/log
tail -f flink-root-taskexecutor-*.out
停止运行
版权声明:本文为leaeason原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。