Mysql基本架构示意图
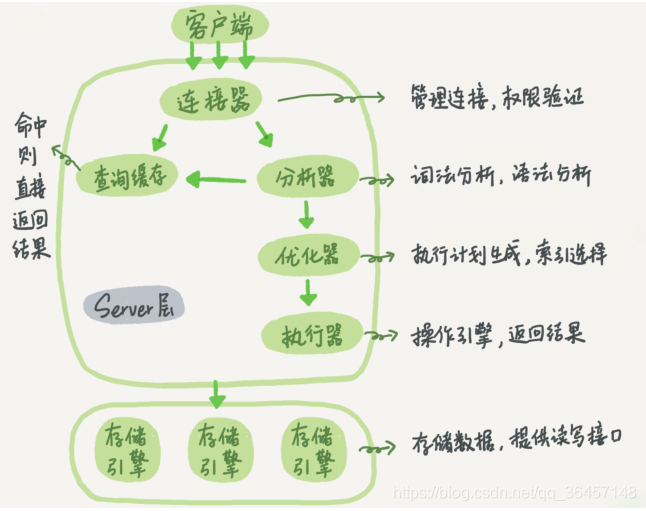
大体来说,MySQL 可以分为 Server 层和存储引擎层两部分。
Server 层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核
心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引
擎的功能都在这一层实现,比如存储过程、触发器、视图等。
存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持 InnoDB、
MyISAM、Memory 等多个存储引擎。现在最常用的存储引擎是 InnoDB,它从 MySQL
5.5.5 版本开始成为了默认存储引擎。
也就是说,你执行 create table 建表的时候,如果不指定引擎类型,默认使用的就是
InnoDB。不过,你也可以通过指定存储引擎的类型来选择别的引擎,比如在 create table
语句中使用 engine=memory, 来指定使用内存引擎创建表。不同存储引擎的表数据存取
方式不同,支持的功能也不同
连接器
连接器是连接我们客户端和服务器首先经过的第一个功能模块,当我们连接我们的Mysql的时候,首先就会执行一条语句
mysql -h[ip地址] -P[端口号] -u[用户名] -p[密码]
这条语句做的事情就是让本机连接上远端或者本地的Mysql服务器,从而进行管理Mysql
此时连接器就是用来验证我们的用户名和密码是否正确的,正确则可以得到操作的权限,其实就是和我们网站的第一个入口—>登陆是一个意思,进行用户验证
如果连接了之后,没有别的操作,则当前连接就正处于一个空闲状态
当连接上数据库的时候,会保持一个连接,这个连接是长连接,直到连接关闭,否则一直保持连接,中途所有的客户端请求,都由该连接进行工作。短连接只能保证客户端在某个时间段的请求由该连接进行工作,下次查询将会使用一个新的连接
使用长连接也会由问题:
因为长连接保持连接,所以长时间下来,当连接数很多的时候,所占用的内存就会很多
解决办法如下:
1.定期断开长连接
2.Mysql5.7版本之后,每次执行一个比较大的操作后,通过执行mysql_reset_connection来重新初始化连接资源。这个过程不需要重连和重新做权限验证,速度会比较快
查询缓存
我们首先可以查看mysql关于缓存的配置
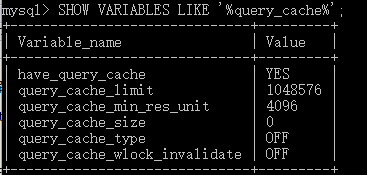
query_cache_type: 查询缓存类型,是否打开缓存
可选项
1、0(OFF):关闭 Query Cache 功能,任何情况下都不会使用 Query Cache;
2、1(ON):开启 Query Cache 功能,但是当SELECT语句中使用SQL_NO_CACHE提示后,将不使用Query Cache;
3、2(DEMAND):开启Query Cache 功能,但是只有当SELECT语句中使用了SQL_CACHE 提示后,才使用Query Cache。
备注1:
如果query_cache_type为on而又不想利用查询缓存中的数据,可以用下面的SQL:
SELECT SQL_NO_CACHE * FROM my_table WHERE condition;
如果值为2,要使用缓存的话,需要使用SQL_CACHE开关参数:
SELECT SQL_CACHE * FROM my_table WHERE condition;
但是大多情况下,建议不要使用查询缓存,因为查询缓存的失效非常频繁,任意一个表的更新操作,这个表上的所有查询缓存都会被清空了,所以查询缓存的命中率非常低,除非表中基本上只会涉及到查操作而很少更新操作的时候可以考虑使用查询缓存的方式
Mysql8.0没有查询缓存的功能,已被彻底抛弃
分析器
往上说的,如果开启了缓存机制的,就在缓存里查,否则就要走分析器了,所谓分析器,就是判断你输入的这条语句到底是什么意思,是要做查操作呢还是更新操作呢,还是语法有错误呢,都是由分析器去做的事情
优化器
经过了分析器,Mysql就知道你要做的是查还是更新还是什么,此时,到优化器,顾名思义,就是如何优化你查的方式
比如:
select * from t1 join t2 using(ID) where t1.c = 10 and t2.d =20
既可以先从表 t1 里面取出 c=10 的记录的 ID 值,再根据 ID 值关联到表 t2,再判断 t2
里面 d 的值是否等于 20。
也可以先从表 t2 里面取出 d=20 的记录的 ID 值,再根据 ID 值关联到 t1,再判断 t1
里面 c 的值是否等于 10。
这两种执行方法的逻辑结果是一样的,但是执行的效率会有不同,而优化器的作用就是决
定选择使用哪一个方案。
执行器
通过分析器,知道要做什么了,通过优化器知道选择什么的方式做了,执行器就是根据上面的两个结论去做,调用InnoDB引擎去取表中的数据
总结
这就是Mysql的逻辑架构,对一个Sql语句完整执行流程的各个阶段有一个初步的认识
————————————————
版权声明:本文为CSDN博主「ymbcxb」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_36457148/article/details/89146821