预备知识
古代计数单位


现代汉语兆的定义
【兆】在现代汉语语境中存在两种不同的解释:
- 一种为 百万,即 1,000,000,即 10^6;
- 另一种为 万亿 ,即 1,000,000,000,000,即 10^12。
在台湾、新加坡、韩国及日本规定的词头体系中,兆指万亿 1,000,000,000,000(10^12),相当于英语词头Tera;
在中华人民共和国规定的词头体系中,以及民国初年的习惯用法中,兆指百万 1,000,000(10^6),相当于英语词头Mega;
现代电子产品中常见的数码照相机中的多少兆像素、计算机中多少兆赫兹速度的CPU等都是这个用法。如:兆欧(电阻单位,一百万欧的电阻为一兆欧);

2进制,8进制,16进制

位,字节, 字符
比特位(bit)【百度百科】:
字节(Byte)【百度百科】:
字符 【百度百科】:
位(bit,简写为b)::是计算机 最小的存储单位;比特位上的值只能存 0 或 1;数据传输大多是以 位 为单位。
字节(Byte,简写为B):是计算机信息技术用于计量存储容量的一种计量单位;
8位为一个字节,是一个很具体的存储空间。0x01, 0x45, 0xFA……
二进制数据存储是以【字节】为基本单位
二进制数据存储的单位有:B、KB、MB、GB、TB
字符 (character):是指计算机中使用的字母、数字、字和符号,通俗的说就是人们使用的记号,抽象意义上的一个符号。包括:1、2、3、A、B、C、~!·#¥%……—*()+等等。
不同编码标准里,字符和字节的对应关系不同。
ASCII码中:
- 一个英文字母(不分大小写)占
一个字节的空间; - 一个中文汉字占
两个字节的空间。
Unicode编码中:
- 一个英文字符等于
两个字节; - 英文标点占
一个字节; - 一个中文(含繁体)等于
两个字节; - 中文标点占
两个字节.
UTF-8编码中:
- 一个英文字符等于
一个字节; - 英文标点占
一个字节 - 一个中文(含繁体)等于
三个字节 - 中文标点占
三个字节,
UTF-16编码中:
- 一个英文字母字符需要
2个字节 - 一个汉字字符存储需要
2个字节(Unicode扩展区的一些汉字存储需要4个字节)。
UTF-32编码中:
- 世界上任何字符的存储都需要
4个字节。
什么是字符集??
严格来说,计算机无法保存电影、音乐、图片、字符……计算机只能保存二进制码。因此电影、音乐、图片、字符都需要先转换为二进制码,然后才能保存。
对于保存字符就简单多了,直接把所有需要保存的字符编号,当计算机要保存某个字符时,只要将该字符的编号转换为二进制码,然后保存起来即可。所谓字符集,就是给所有字符的编号组成总和。
ASCII
最早的字符集叫 American Standard Code for Information Interchange(美国信息交换标准代码),简称 ASCII,由 American National Standard Institute(美国国家标准协会)制定。
1.鼻祖,ascii,7位(bit) 范围128个字符
ASCII 字符集总共规定了 128 种字符规范,但是并没有涵盖西文字母之外的字符。范围是0x00 - 0x7F 共128个字符。
2.随之出现扩展ascii, 8位范围256
后来发现,如果需要按照表格方式打印这些字符的时候,缺少了“制表符”。于是又扩展了ASCII的定义,使用一个字节的全部8位(bit)来表示字符了,这就叫扩展ASCII码。范围是0x00 - 0xFF 共256个字符。
GB2312、GBK 、GB18030
3.中国最早出现gb-2312,支持中文
GB 2312 就是解决中文编码的字符集,由国家标准委员会发布。
同时考虑到中文语境中往往也需要使用西文字母,GB2312 也实现了对 ASCII 的向下兼容,原理是西文字母使用和 ASCII 中相同的代码。但是 GB2312 只涵盖了 6000 多个汉字,还有很多没有包含在其中,又进行扩展。
4.随之出现gbk,扩展的gb-2312,包含复杂中文和繁体
扩展之后的编码方案被称为 GBK 标准,GBK包括了GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。
5.进一步扩展GB18030
后来少数民族也要用电脑了,于是我们再扩展,又加了几千个新的少数民族文字,GBK扩成了 GB18030。从此之后,中华民族的文化就可以在计算机时代中传承了。中国的程序员们看到这一系列汉字编码的标准是好的,于是通称他们叫做 “DBCS“(Double Byte Charecter Set 双字节字符集)。
Unicode
6. unicode标准字符集统一全球
Unicode之前,世界各个国家都有自己的编码标准,导致国家与国家之间的编码转换很有问题。为了把全世界人民所有的所有的文字符号都统一进行编码,于是一个叫 ISO (国际标谁化组织)的国际组织制定了”Universal Multiple-ctet Coded Character Set”,简称 UCS, 俗称 “unicode“,规定2个字节表示一个字符。
如何表示Unicode的字符?
通常会用“U+”一组十六进制的数字来表示这一个字符。
UNICODE 的范围是 0x0000 - 0xFFFF 共60000多个字符,其中光汉字就占用了40000多个。
对于ASCII里的那些英文“半角”字符,其原编码不变,只是将其长度由原来的8位扩展为16位,高位补0。而其他文化和语言的字符则全部重新统一编码。这种大气的方案在保存英文文本时会多浪费一倍的空间。这样全世界任何一个地区的软件,可以不用修改地就能在另一个地区运行了。虽然我用 IE 浏览日本网站,显示出我不认识的日文文字,但至少不会是乱码了。
unicode 的三种表现形式:&#、&#x、\u参考链接: link.
如:
{ "a":""}
可以表示为:
{    "a":""}
//这是unicode编码在html中的一种表示方法,即"&#+unicode编码的十六进制数+;".
{    "a":""}
\u007b\u0020\u0020\u0020\u0020\u0022\u0061\u0022\u003a\u0022\u0022\u007d
字符编码
UTF-8:
7.UTF-8 是「编码规则」
UTF是“Unicode Transformation Format”的缩写,可以翻译成Unicode字符集转换格式,即怎样将Unicode定义的数字转换成程序数据。
字符统一成Unicode编码,乱码问题从此消失了。但是Unicode只是一个 Character Set(字符集)。字符集只是给所有的字符一个唯一编号,但是却没有规定如何存储。Unicode最常用的是用两个字节表示一个字符,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
用什么规则存储 Unicode 字符就成了关键。
unicode和ascii是一种编码方式。UTF-8,UTF-16等是一种存储方式,在存储和传输上节约空间、提高性能的一种编码形式。
在Unicode中,我们有很多方式将字符表示成程序中的数据,包括:UTF-8、UTF-16、UTF-32。
例如,“汉字”对应的数字是0x6c49和0x5b57,而编码的程序数据是:
char data_utf8[] = {0xE6,0xB1,0x89,0xE5,0xAD,0x97}; //UTF-8编码
char16_t data_utf16[] = {0x6C49,0x5B57}; //UTF-16编码
char32_t data_utf32[] = {0x00006C49,0x00005B57}; //UTF-32编码
我们可以规定,一个字符使用四个字节存储,也就是 32 位,这样就能涵盖现有 Unicode 包含的所有字符,这种编码方式叫做UTF-32(UTF 是 UCS Transformation Format 的缩写)。UTF-32 的规则虽然简单,但是缺陷也很明显很浪费空间,假设使用 UTF-32 和 ASCII 分别对一个只有西文字母的文档编码,前者需要花费的空间是后者的四倍(ASCII 每个字符只需要一个字节存储)。
在存储和网络传输中,通常使用更为节省空间的"变长编码方式" UTF-8。UTF-8是一套以 8 位为一个编码单位的可变长编码。会将一个码位编码为1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。
比如:一个编号为 65 的字符,只需要一个字节就可以存下,但是编号 40657 的字符需要两个字节的空间才可以装下,而更靠后的字符可能会需要三个甚至四个字节的空间。
UTF-8 的编码规则如下(U+ 后面的数字代表 Unicode 字符代码):
Unicode编码(十六进制) UTF-8 字节流(二进制)
U+ 0000 ~ U+ 007F: 0XXXXXXX
U+ 0080 ~ U+ 07FF: 110XXXXX 10XXXXXX
U+ 0800 ~ U+ FFFF: 1110XXXX 10XXXXXX 10XXXXXX
U+10000 ~ U+1FFFF: 11110XXX 10XXXXXX 10XXXXXX 10XXXXXX
可以看到,UTF-8 通过开头的标志位位数实现了变长。对于单字节字符,只占用一个字节,实现了向下兼容 ASCII,并且能和 UTF-32 一样,包含 Unicode 中的所有字符,又能有效减少存储传输过程中占用的空间。
汉字: 知
Unicode码: 30693
Unicode码的十六进制表示为: 0x77E5
根据utf-8的上表中的编码规则,「知」字的码位U+77E5属于第三行的范围:所以需要3个字节(byte)
7 7 E 5
0111 0111 1110 0101 二进制的 77E5
--------------------------
1110XXXX 10XXXXXX 10XXXXXX 模版(由77E5范围,取上表第三行)
0111 011111 100101 根据模板格式调整77E5二进制的结构
11100111 10011111 10100101 代入模版
E 7 9 F A 5 转化回16进制
这就是将 U+77E5 按照 UTF-8 编码为字节序列 E79FA5 的过程。反之亦然。
乱码:
为什么会出现乱码呢?
因为在文件 存的格式 和 读取格式 不一致就会乱码了。
简单的说乱码的出现是因为:编码 (encode)和解码(decode)时用了不同或者不兼容的字符集。
encode的作用:是将unicode编码的字符串编码成二进制数据。
如:str2.encode('utf-8'),表示将unicode编码的字符串编码成utf-8。
decode的作用:是将二进制数据解码成unicode编码。
简单的来说:decode就是把二进制数据(bytes)转化成人看的懂得英文或者汉字(decode用的比较多)
如:str1.decode('utf-8'),表示按utf-8编码将字符串解码成unicode编码。
注意:
在计算机内存中,统一使用Unicode编码,保存到硬盘/传输的时候,就转换为UTF-8编码。
例如:
- 用记事本编辑的时候,从
文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件。 - 浏览网页的时候,服务器会把动态生成的
Unicode内容转换为UTF-8再传输到浏览器: - 我们平常在做编码转换时候,通常用
unicode作为中间编码。先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码格式。
String urlString = "TOP 好的";//TOP 好的
urlString = URLEncoder.encode(urlString, "utf-8");//encode:--->TOP+%E5%A5%BD%E7%9A%84
urlString = URLDecoder.decode(urlString, "utf-8");//decode:--->TOP 好的
String.getBytes(Stringdecode)//方法会根据指定的encode编码返回某字符串在该编码下的byte数组表示
byte[] b_utf8 = "知".getBytes("UTF-8"); // b_utf8的长度为3
11100111 10011111 10100101
[-25, -97, -91] //没有转化成16进制,而是有符号的十进制
byte[] b_gbk = "知".getBytes("GBK");
[-42, -86]
byte[] b_unicode = "知".getBytes("unicode"); // b_unicode长度为4
[-2, -1, 119, -27]
byte[] b_iso88591 = "知".getBytes("ISO8859-1");// b_iso88591的长度为1
[63]//所有中文都是这个数值,因为不识别
//通过new String(byte[], decode),根据指定的decode编码来将byte[]解析成字符串。
String s_utf8 = new String(b_utf8, "UTF-8");
知
String s_gbk = new String(b_gbk, "GBK");
知
String s_unicode = new String(b_unicode, "unicode");
知
String s_iso88591 = new String(b_iso88591, "ISO8859-1");
?//encode都是不对的,decode指定是错的
//为了让中文字符适应某些特殊要求(如http header头要求其内容必须为iso8859-1编码),可能会通过将中文字符按照字节方式来编码的情况
String aaa = new String("知".getBytes("UTF-8"), "ISO8859-1");
//把 '知' 按照 UTF-8 encode ---> [-25, -97, -91] 再按照 ISO8859-1 decode 成 乱码'知'
String bbb = new String(aaa.getBytes("ISO8859-1"), "UTF-8");
//把乱码'知' 按照 ISO8859-1 encode ---> [-25, -97, -91], 再按照 UTF-8 decode 成 '知'
在开发时会检查字符长度,以免数据库字段的长度不够而报错,考虑到中英文的差异,肯定不能用String.length()方法判断,而需采用String.getBytes().length;还可以用指定编码方式查看长度:String.getBytes("GBK").length
Set<String> charsetNames = Charset.availableCharsets().keySet();
System.out.println("-----the number of jdk1.67's charset is " + charsetNames.size() + "-----");
for (Iterator it = charsetNames.iterator(); it.hasNext();) {
String charsetName = (String) it.next();
System.out.println(charsetName);
}
基本数据类型
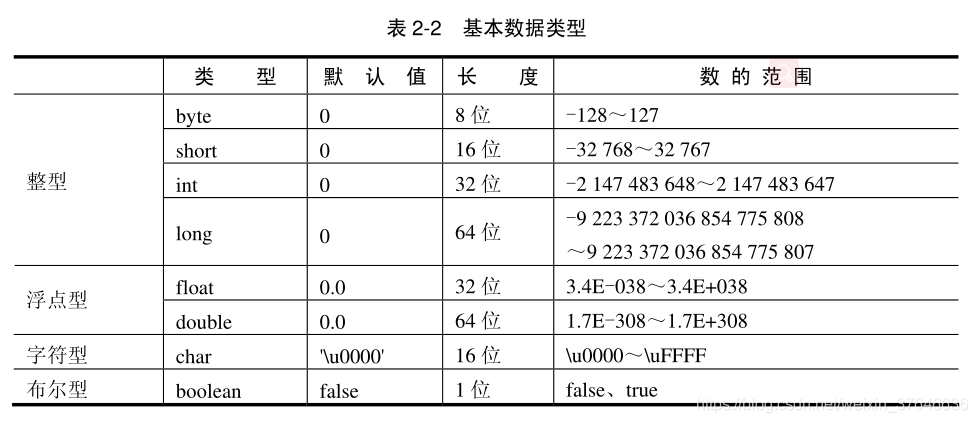
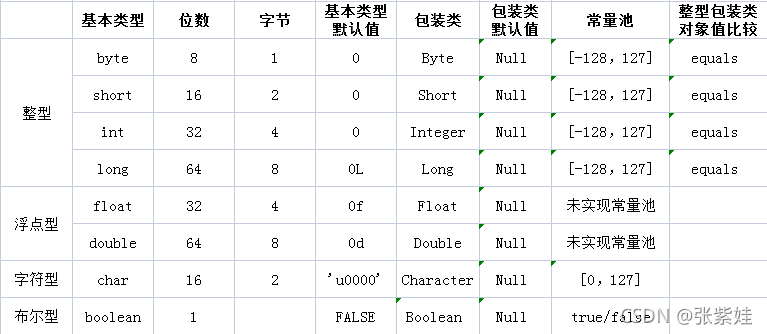 自动装箱:将基本数据类型重新转化为对象
自动装箱:将基本数据类型重新转化为对象
Integer num = 9;
正常应该如下写法
Integer num = Integer.valueOf(9);
自动拆箱:将对象重新转化为基本数据类型
Integer num = 9;
对象时不能直接进行运算的,而是要转化为基本数据类型后才能进行加减乘除;
进行计算时隐含的有自动拆箱;
System.out.print(num--);
基本类型和包装类型有什么区别?
- 包装类型可以为 null,而基本类型不可以。它使得包装类型可以应用于 POJO 中,而基本类型则不行。那为什么 POJO 的属性必须要用包装类型呢?《阿里巴巴 Java 开发手册》上有详细的说明, 数据库的查询结果可能是 null,如果使用基本类型的话,因为要自动拆箱,就会抛出 NullPointerException 的异常。
- 包装类型可用于泛型,而基本类型不可以。泛型不能使用基本类型,因为使用基本类型时会编译出错。因为泛型在编译时会进行类型擦除,最后只保留原始类型,而原始类型只能是 Object 类及其子类。
- 基本类型比包装类型更高效。基本类型在
栈中直接存储的具体数值,而包装类型则存储的是堆中的引用。 很显然,相比较于基本类型而言,包装类型需要占用更多的内存空间。
int 和 Integer 有什么区别?
- Integer是int的
包装类;int是基本数据类型; - Integer变量必须
实例化后才能使用;int变量不需要; - Integer实际是
对象的引用,指向此new的Integer对象;int是直接存储数据值; - Integer的默认值是
null;int的默认值是0。
Integer变量和int变量的对比
int a = 128;
Integer b = 128;
Integer c = new Integer(128);
System.out.println(a == b); // true
System.out.println(a == c); // true
因为包装类Integer和基本数据类型int比较时,java会自动拆包装为int,然后进行比较,实际上就变为两个int变量的比较
非new生成的Integer变量 和 new Integer()生成变量的对比
Integer c = new Integer(128);
Integer c1 = new Integer(128);
System.out.println(c1 == c); // false
new生成的Integer变量永远是不相等的(因为new生成的是两个对象,其内存地址不同)
Integer b = 128;
Integer b1 = 128;
System.out.println(b1 == b); // false
Integer缓存范围是[-128 ~ 127],超出此范围,会在堆中new出一个对象来存储。
System.out.println(c == b); // false
变量b是java常量池中存储的引用,指向堆中的对象,而变量c指向堆中新建的对象,两者在内存中的地址不同
Integer d = 100;
Integer d1 = 100;
System.out.println(d1 == d); // true
Integer缓存范围是[-128 ~ 127],存在缓存里