本文是“函数型数据计量经济学”的第2篇原创文章
证券市场出现5分钟(1分钟)实时交易数据促使更多研究者基于高频数据进行交易策略的制定。传统的金融建模方法多是基于等间隔、低频的离散观测数据,而函数型数据分析方法能将频率混杂、不等间隔的离散观测值纳入平滑的连续函数范畴,从而能够准确描述数据的潜在规律性[1]。分析思路的现实普适性和方法本身的相对优势使得函数型数据分析成为大数据时代金融数据挖掘的重要方法[2]。
股市上午开盘是红盘还是绿盘,可能会影响投资者对股市当天走势的判断,进而影响其决策行为。本推文利用242个交易日的上证指数高频1分钟日内价格数据(intra-day data),构建函数型时间序列样本,建立函数型数据Logit回归模型研究股指日内交易价格变化对次日股市开盘的影响;应用上,该模型可以在股市收盘后,对次日的开盘情况进行预测,为投资者提供投资决策依据。
构建函数型数据Logit回归模型:
选取上证指数从2018年1月至2018年12月的每日一分钟高频交易数据,一共有243个交易日,每个交易日共有242个交易价格数据。由于我们能够获得的每天1分钟交易价格样本观测点是有限的、离散的,函数型数据分析的第一步是把离散的样本观测点重构为函数曲线。这样242个交易日的每天242个交易价格数据,重构出242个函数样本。引入二分类变量Y作为描述大盘是否上涨的变量,Y=1,表示大盘为红盘;Y=0,表示表示大盘为绿盘。建立函数型数据Logit回归模型如下: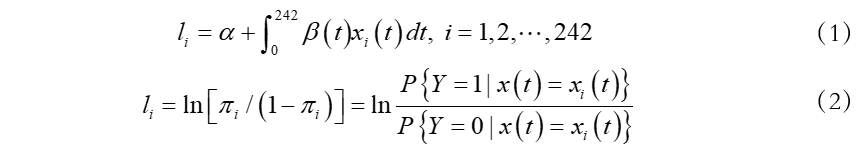 li 表示第 i 日上证指数红绿盘的对数发生比,xi (t ) 为第 i 日的日内交易价格函数,α 为常数回归参数,β(t )为解释变量的回归系数函数。
li 表示第 i 日上证指数红绿盘的对数发生比,xi (t ) 为第 i 日的日内交易价格函数,α 为常数回归参数,β(t )为解释变量的回归系数函数。
参数估计:
在构建了函数型数据Logit回归模型之后,本文采用Fourier基函数组对xi (t )进行展开,其展开式如下: 其中,Φj (t )为Fourier基函数组,再采取同样的基函数来展开参数函数,即
其中,Φj (t )为Fourier基函数组,再采取同样的基函数来展开参数函数,即 便可将(1)式化为:
便可将(1)式化为: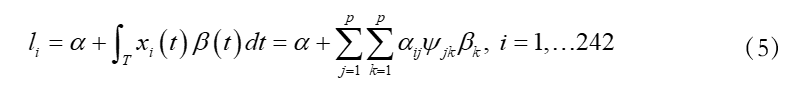 其中,α是实数参数,βk是待估计的系数,
其中,α是实数参数,βk是待估计的系数,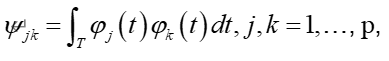 为参数函数β(t )与xi (t )各自Fourier基的乘积。利用矩阵工具,(5)式还可以变为
为参数函数β(t )与xi (t )各自Fourier基的乘积。利用矩阵工具,(5)式还可以变为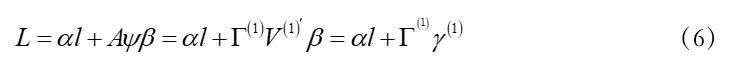 其中:
其中: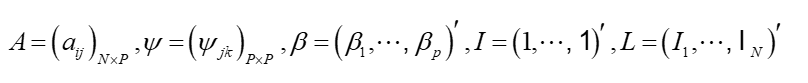 在Logit模型的估计过程中,考虑到日内价格函数样本相依性,为消除相依性的影响,本文采用Escabias(2004)提出的一种改进后的函数主成分分析(FPCA)对函数型Logit回归模型中参数函数的估计。
在Logit模型的估计过程中,考虑到日内价格函数样本相依性,为消除相依性的影响,本文采用Escabias(2004)提出的一种改进后的函数主成分分析(FPCA)对函数型Logit回归模型中参数函数的估计。
如何预测:
选取前220天的上证指数开盘价作为训练集,剩下的22天作为预测集。得到训练集的回归方程之后,将测试集的X带入训练集估计的参数当中便可以得到模型预测的Y,然后将预测的Y与真实的Y进行对比,便可以计算预测的准确率。红盘的预测准确率等于预测的红盘天数/实际的红盘天数,绿盘的预测准确率等于预测的红盘天数/实际的红盘天数。上述估计与预测,通过调用R软件包fda.usc,得到函数型数据Logit回归模型的预测结果,并将结果与RBF核SVM模型进行对比,表3两种建模方法准确率对比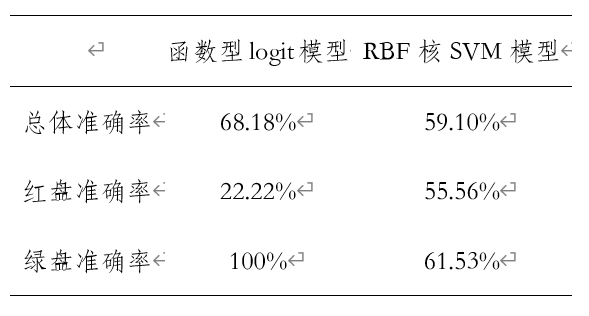 从上表可知:在红盘准确率方面,函数型logit模型的预测准确率要低于RBF核SVM模型,但是在绿盘准确率与总体准确率方面函数型logit模型的预测能力要优于RBF核SVM模型。模型优势在于,在每日的收盘后,即可预测第二天开盘情况,函数型logit模型充分利用了最新股价信息。另一方面,受限于方法的局限性,传统的Logit模型的解释变量只能为低频的离散观测数据,而一般的机器学习类模型并未考虑高频实时股价数据的相依性。
从上表可知:在红盘准确率方面,函数型logit模型的预测准确率要低于RBF核SVM模型,但是在绿盘准确率与总体准确率方面函数型logit模型的预测能力要优于RBF核SVM模型。模型优势在于,在每日的收盘后,即可预测第二天开盘情况,函数型logit模型充分利用了最新股价信息。另一方面,受限于方法的局限性,传统的Logit模型的解释变量只能为低频的离散观测数据,而一般的机器学习类模型并未考虑高频实时股价数据的相依性。
函数型数据Logit回归模型核心R代码
rm(list=ls())#载入所需的包 require(fda.usc)library(fda)library(fda.usc)#将数据转化为函数型数据x.fdata=fdata(X,argvals=seq(0,1,length.out = M),rangeval=c(0,1),fdata2d=F)#创建傅里叶基x.basis=create.fourier.basis(c(0,1), nbasis=x.out$numbasis.opt)x.harmaccelLfdx.fdPar #平滑数据x.fd =smooth.basis(argvals=seq(0,1,length.out =M), t(X) ,x.fdPar)$fd #主成分分析x.pca = pca.fd(x.fd, x.out$numbasis.opt,x.fdPar)#进行KL展开x.evalfor (i in 1:N) { x.fd2 x.eval[i,]#前220个Y作为训练集Y1#后22个Y作为测试集Y2datafdat=list("df"=dataf,"x"=x.fdata[1:220])#进行logit分类,将主成分基函作为回归系数的基底a1newdat#进行预测p1table(Y2,p1)#计算准确率sum(p1==Y2)/22参考文献:
[1]Ramsay J O,Ramsey J B.Functional Data Analysis of the Dynamics of the Monthly Index of Nondurable Goods Production[J].Journal of Econometrics,2002,107( 1 /2) : 327-344.[2]Tsay R S.Some Methods for Analyzing Big Dependent Data[J].Journal of Business & Economic Statistics,2016,34( 4) : 1-47.[3]苏梽芳,李气芳,陈美源. 相依函数型数据回归模型:估计与应用实例. 华侨大学工作论文.