前言
卷积神经网络主要用来做图片分类、目标检测等图像相关的任务,这篇文章介绍了它在NLP中的应用:文本分类。本文先介绍了CNN,然后分析了CNN为什么能用在NLP中,最后讲解了Yoon Kim (2014)提出的CNN文本分类模型,代码见github。
什么是卷积
简单介绍一下卷积运算,卷积运算作用就是用滤波器来学习或者检测图片的特征。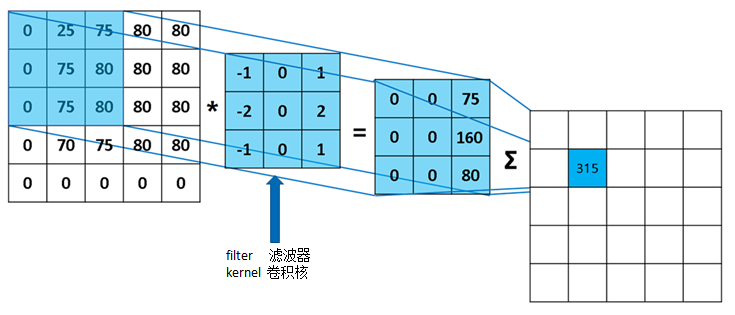
看上图,左边是一张5×5的黑白图片,现在是矩阵的形式,每个格子代表一个像素点。中间的3×3的矩阵叫做滤波器,也可以叫做卷积核。 星号代表的就是卷积运算,用滤波器对左边的图片做卷积运算,得出3×3的矩阵。具体怎么算呢? 先说结果的第一个元素:就是用滤波器,覆盖在图片的左上角,对应的每格元素相乘,得到9个数字,最后把这9个数字相加,就得到了第一个元素。 滤波器在图片上左移一格,再计算就得到了第二个元素,之后的元素同理。
卷积公式如下,其中S SS代表运算结果,I II是原始图片,K KK是卷积核,m mm、n nn是卷积核的高和宽,括号中的两个值代表元素的位置:
S ( i , j ) = ( I ∗ K ) ( i , j ) = ∑ m ∑ n I ( i + m , j + n ) K ( m , n ) S(i,j)=(I*K)(i,j)=\sum_m\sum_nI(i+m,j+n)K(m,n)S(i,j)=(I∗K)(i,j)=m∑n∑I(i+m,j+n)K(m,n)
其实该函数叫互相关函数(cross-correlation),和卷积函数几乎一样,只是没有对卷积核进行翻转,很多深度学习的库实现的都是这个函数而并非真正的卷积函数。在深度学习中我们默认它为卷积函数。
现在知道卷积运算了,那么CNN呢?
CNN的结构:(卷积层+非线性激活函数(Relu或tanh)+池化层)× n + 几个全连接层。
刚开始的卷积层提取低阶特征,比如曲线等,层数越深提取的特征越高级,深层的卷积层提取的高级特征比如人脸识别中的鼻子、嘴巴等。
池化层:对每个不重叠的n ∗ n n*nn∗n的区域进行降采样,有最大池化、平均池化等。比如2 ∗ 2 2*22∗2最大池化层:从原矩阵每个不重叠的2 ∗ 2 2*22∗2的四个元素中选出一个最大值,组成一个矩阵。
池化层的作用:
- 可以提将输出矩阵的尺寸固定不变。
- 减少输出维度,但是保存重要特征。
Channels通道:通道是输入数据的不同“视图”。
比如图片中的RGB(红色,绿色,蓝色)是三个通道。在NLP中通道可以是不同的词嵌入(word2vec和GloVe)或者是相同句子不同的语言。
通道
卷积层和全连接层有什么本质上的区别:
- 卷积层权重只有一个卷积核,是共享的,参数远少于全连接层。
- 卷积层可以提取相对位置信息(相邻的权重是相关的)。
CNN in NLP
以上特点使得cnn在计算机视觉方向应用很广,但是在nlp中,cnn貌似并不适合使用。一句话说法有很多种,语义相关的词中间可能会穿插不相关的词,而且提取出来的语句的高阶特征也不如视觉方向那么明显。下面看看CNN如何应用在NLP中。
cnn最适合做的是文本分类,由于卷积和池化会丢失句子局部字词的排列关系,所以纯cnn不太适合序列标注和命名实体识别之类的任务。
nlp任务的输入都不再是图片像素,而是以矩阵表示的句子或者文档。矩阵的每一行对应一个单词或者字符。也即每行代表一个词向量,通常是像 word2vec 或 GloVe 词向量。在图像问题中,卷积核滑过的是图像的一“块”区域,但在自然语言领域里我们一般用卷积核滑过矩阵的一“行”(单词)。
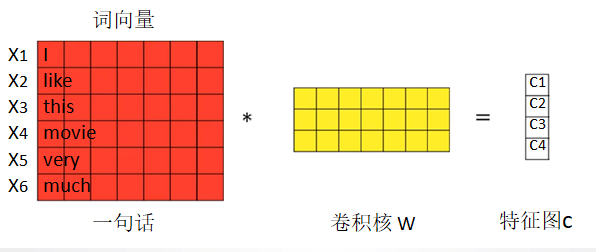
如上图,如果一个句子有6个词,每个词的词向量长度为7,那输入矩阵就是6x7,这就是我们的“图像”。可以理解为通道为1的图片。
其计算公式如下,其中⊕ \oplus⊕是按行拼接,f ff为非线性激活函数:
X 1 : n = x 1 ⊕ x 2 ⊕ . . . ⊕ x n X_{1:n}=x_1\oplus x_2\oplus ... \oplus x_nX1:n=x1⊕x2⊕...⊕xn
c i = f ( w ⋅ x i : i + h − 1 + b ) c_i=f(w \cdot x_{i:i+h-1}+b)ci=f(w⋅xi:i+h−1+b)
c = [ c 1 , c 2 , . . . , c n − h + 1 ] c=[c_1,c_2,...,c_{n-h+1}]c=[c1,c2,...,cn−h+1]
卷积核的“宽度”就是输入矩阵的宽度(词向量维度),“高度”可能会变(句子长度),但一般是每次扫过2-5个单词,是整行整行的进行的。这有点像n-gram语言模型,
也称为n元语言模型。n元语言模型简单来说就是:一个词出现的概率只与它前面的n-1个词有关,考虑到了词与词之间的关联。一般来说,在大的词表中计算3元语言模型就会很吃力,更别说4甚至5了。由于参数量少,CNN做这种类似的计算却很轻松。
卷积核的大小:由于在卷积的时候是整行整行的卷积的,因此只需要确定每次卷积的行数即可,这个行数也就是n-gram模型中的n。一般来讲,n一般按照2,3,4这样来取值,这也和n-gram模型中n的取值相照应。
实例:
从头开始实现一个CNN文本分类的模型,对影评进行二分类,分为消极和积极两类。
分预处理和模型两部分:
一. 预处理
将数据集的所有词标号,构建一个词表,如下图所示。

每个词也对应一个词向量,词向量是预训练好的,我们只需要用它行了。数据的格式如下图。
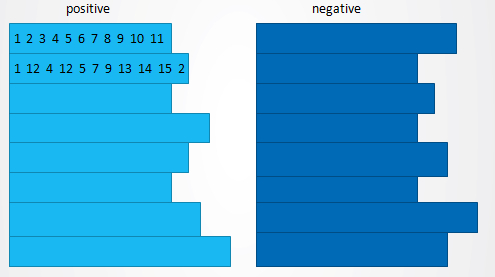
将积极样本和消极样本放在一起,并填充、打标签,如下图。

打乱顺序

打乱顺序后参数不易陷入局部最优,模型能够更容易达到收敛。
模型

这幅简化的图大致能表现出模型的结构,下面的讲解请结合图片一起看。
从左往右看,首先输入数据(一句话),经过预处理,此处每个样本填充为7个词,进入embedding层,将句子中每个词按照词表转为索引,再转变成词向量,此处词向量维度为5,输入到模型中。需要注意的是这里的embedding矩阵可以设置为**trainable=True,也可设置为trainable=False**,前者代表embedding矩阵可以微调,后者表示不对其进行训练。
注:这里可以设置为多个通道。
下一层是卷积层,一共有三种尺寸的卷积核:2,3,4,分别对应2-gram,3-gram和4-gram,这个简化的图中每种尺寸的卷积核的数量都是2,实际会设置为几十上百个,我们不会只用一个卷积核对输入图像进行过滤,因为一个核提取的特征是单一的。这就有点像是我们平时如何客观看待事物,必须要从多个角度分析事物,这样才能尽可能地避免对该事物产生偏见。接下来用三个尺寸的卷积核对输入矩阵做卷积运算,每个卷积操作都会得到一个feature map。
然后是池化层:我们对每一个feature map,进行最大池化,就是简单地从feature map中提取最大的值,这里最大的值也就代表着最重要的特征信息,将每个Feature Map的维度全部下降为1,这样,句子填充对结果就没有影响了,因为不管feature map中有多少个值,只取最大的值,即最重要的特征。
接着将所有池化得到的特征值拼接到一起,形成单个feature map。
下一层将这个feature map通过全连接的方式连接到一个softmax层,进行分类。
训练的时候,在全连接的部分使用dropout,并对全连接层的权值参数进行L2正则化的限制。用来防止隐藏单元自适应,从而减轻过拟合程度。
其中L2正则化使每个参数不会很大。对于Dropout,它会使神经网络的隐藏单元按照一定的概率暂时从网络中丢弃,它使的所有神经单元变得不那么重要,因为没准下次迭代它就被shuts down了。不依赖于任何一个特征,因为该单元的输入可能随时被清除。Dropout提高了2%-4%的性能。
下面是Yoon Kim (2014)提出的四种模型:
| 论文提出的模型 | 在数据集Movie Review的准确率 |
|---|---|
| CNN-rand | 76.1% |
| CNN-static | 81.0% |
| CNN-non-static | 81.5% |
| CNN-multichannel | 81.1% |
四种模型的区别在embedding层:
CNN-rand:baseline模型,所有词随机初始化然后随着训练不断修改。
CNN-static:使用经过word2vec预训练的词向量,而未覆盖在内的词则随机初始化。训练过程中,预训练的词向量不变,随机初始化的词向量不断修改。
CNN-non-static:同上,但预训练的词向量会在训练过程中微调(fine-tune)
CNN-multichannel:用上面两种词向量,每一种词向量一个通道,一共两个通道。
TensorFlow实现CNN文本分类
代码见github,预训练词向量下载地址:https://nlp.stanford.edu/projects/glove/, 我用的是400,000个词汇的300维Glove词向量。
下面是tensorflow中卷积和池化的函数,拿出来讲解一下。
tf.nn.conv2d
tf.nn.conv2d(input,filter,strides,padding,use_cudnn_on_gpu=None,name=None)
参数:
input:
一个Tensor,每个元素的数据类型必须为float32或float64。
input的形状:[batch, in_height, in_width, in_channels],
batch为训练过程中每迭代一次迭代数据条数。
in_height, in_width分别为矩阵(图片)的高和宽
in_channels为矩阵(图片)的通道,比如图片可以有RGB三通道。
输入:(句子个数, 句子长度, embedding尺寸, 通道数)
filter:
卷积核,也是一个Tensor,元素类型和input类型一致。
filter的形状:[filter_height, filter_width, in_channels, out_channels]
(其中out_channels也是该卷积核的个数)。
参数分别为卷积核的高,宽,输入的channels和输出的channels
卷积核:(卷积核尺寸, embedding尺寸, 通道数, 卷积核个数)
stride:
步长,长度为4的list,元素类型为int。表示每一维度滑动的步长。其中strides[0] = strides[3] = 1。strides[1]和strides[2]分别表示在hight和width方向的步长。
padding:
可选参数为"SAME", “VALID”。
SAME表示填充,VALID不填充。
use_cudnn_on_gpu:
bool类型,有True和False两种选择。
name:
此操作的名字
tf.nn.max_pool
池化
tf.nn.max_pool(value, ksize, strides, padding, name=None)
参数和卷积很类似:
value:需要池化的输入,池化层通常跟在卷积层后面,所以输入的shape依然是[batch, hei ght, width, channels]。
ksize:池化窗口的大小,四维向量,一般是[1, height, width, 1],前后两个1对应的是batch和channels,都不池化所以为1
strides:步长,和卷积一样,前后都为1,中间两个分表表示窗口在每一个维度上滑动的步长,shape:[1, stride,stride, 1]
padding:‘VALID’ 或’SAME’
返回:一个Tensor,类型不变,shape仍然是[batch, height, width, channels]这种形式
总结
Yoon Kim (2014)的实验证明了CNN在NLP中的实用性,同时也可以看出预训练词向量对结果的巨幅提升,最近Google提出了BERT,它在11个NLP任务中刷新了成绩,需要好好研究研究,继续加油!
References:
[1] Yoon Kim (2014) Convolutional Neural Networks for Sentence Classification
[2] Implementing a CNN for Text Classification in TensorFlow
[3] Understanding Convolutional Neural Networks for NLP
[4] DNN/LSTM/Text-CNN情感分类实战与分析
[5] Tensorflow官方文档