豆瓣用户每天都在对“看过”的电影进行“很差”到“力荐”的评价,豆瓣根据每部影片看过的人数以及该影片所得的评价等综合数据,通过算法分析产生豆瓣电影 Top 250。
首先 我们进入到豆瓣top250这个界面,首先,我们先确认要爬取的内容是不是在页面源代码中,如果在源代码中,我们直接解析html即可,如果不在,我们需要调试找到请求。
右键查看源代码,发现所看到的内容直接就在源代码中,直接请求即可。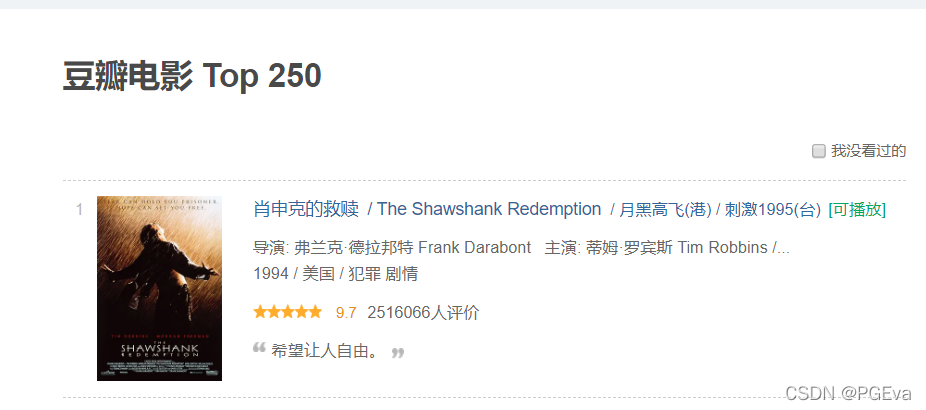

代码如下:
import re
import requests
import csv
f = open("result.csv", mode="a+", newline='')
csvwriter = csv.writer(f)
#因为每一页只有25个影片 通过更改请求url的内容来依次请求250个影片
for i in range (0, 10):
url = 'https://movie.douban.com/top250?start={}'.format(i*25)
_headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"
}
ret = requests.get(url, headers = _headers)
page_content = ret.text
# 解析数据
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>'
r'.*?<p class="">.*?<br>(?P<year>.*?) '
r'.*?<span class="rating_num" property="v:average">(?P<score>.*?)</span>'
r'.*?<span>(?P<number>.*?)人评价</span>', re.S)
#开始匹配
ret = obj.finditer(page_content)
for it in ret:
dic = it.groupdict()
dic['year'] = dic['year'].strip()
csvwriter.writerow(dic.values())
f.close()
print('Over')
最后读取了影片名 上映日期 评分 参与评分人数,并写入csv文件中。效果如下: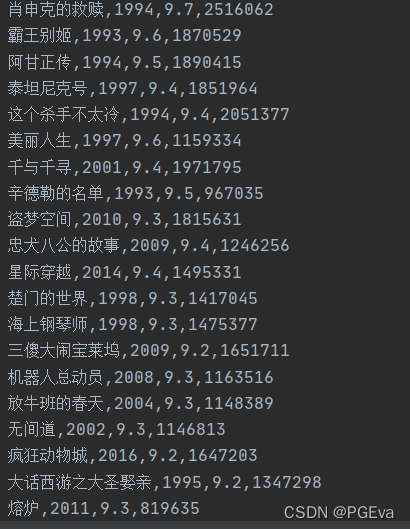
版权声明:本文为ProgramVAE原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。