selenium篇之半自动发帖机
前言
selenium不用多说,是一个非常强大的用于爬虫、网页自动化测试的库。在我看来,对比于一般的基于http/https协议的爬虫来说,其优势可以分为以下两点:
1.不需要了解协议的具体实现细节,这也就避免了对部分加密参数繁琐的解密过程。
2.因为selenium是模拟真实用户的访问,可以有效避免部分网站采取的反爬、或网页优化策略导致爬虫制作难度、成本提高(如字体加密、懒加载等)的问题。
但其缺点也很致命,需要更多的资源、速度较慢。
综上所述,对于一般网站而言http/https协议的爬虫有着很大的优势,但对于不熟悉协议的新手或者网站爬取难度较大的情况下,使用selenium来操作无疑是一个省时省力的最佳选择。
需求分析
某论坛阅读帖子需要较高等级,而等级可以通过发言得到积分来提升,但发言要有间隔才能有效获取积分,所以需要设置多个帖子的定时发送,并预设评论,从而有效的获取积分。
主要工作
0X00 论坛登录
使用谷歌浏览器进行操作,其中一个主要原因是利用谷歌浏览器提供的无头模式,这样可以不影响正常工作。
chrome_options.add_argument('--headless')
首次访问论坛时,必须登录账号,并保持会话。
1.填写表单并提交
2.获取cookie并保存到本地,其主要目的是,后台长时间的等待指令执行时可以先关闭浏览器对象节约资源,并在启动一个新的浏览器后,将cookie填入实现免登录。
相关的cookie保存于读取代码如下
# 保存cookie操作
def save_cookie(self):
with open('cookies', 'wb') as f_obj:
pickle.dump(obj=self.__driver.get_cookies(), file=f_obj)
# 读取cookie操作
def load_cookie(self):
with open('cookies', 'rb') as f_obj:
cookies = pickle.load(file=f_obj)
for cookie in cookies:
self.__driver.add_cookie(cookie)
此处有一个坑在于,重新启动浏览器时必须要先加载页面,填入cookie,然后再加载页面,如果没有先加载页面,那么填入cookie时就会报错
selenium.common.exceptions.UnableToSetCookieException: Message: unable to set cookie
0x01 获取论坛帖子的链接并保存到本地
首先需输入需要爬取的帖子列表页数,由于python的input()函数没有格式化输入,所以得自己实现限定只能输入整数。
page_count = None
while True:
try:
page_count = int(input('请输入爬取帖子页数'))
if type(page_count) == int:
break
except:
pass
之后通过selenium提供的css选择器来定位元素和获取帖子标题和链接,并按格式保存到本地文本文档。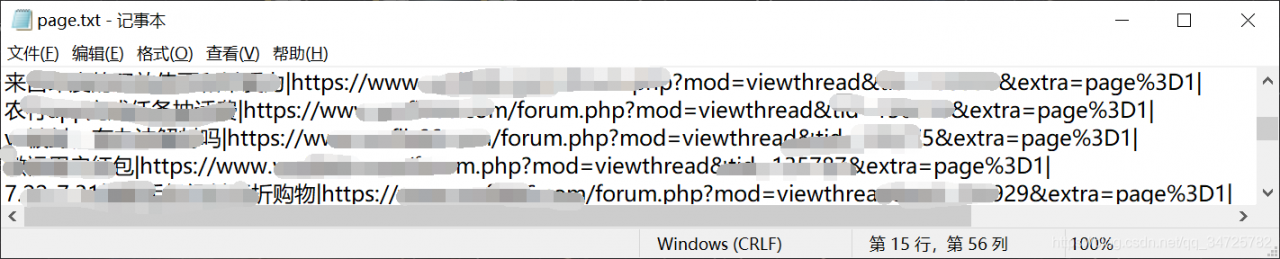
0x02 人工浏览感兴趣的帖子并预设评论
爬取帖子后,对于感兴趣的帖子可以浏览后在文本文档每一行后预设评论,保存后继续执行。
0x03 随机间隔时间提交评论
由于多任务(对每个已经预设评论的帖子)可以设置为串行的,所以只需要设置一个定时器,按队列顺序随机时间间隔来执行任务。
def __set_time_reply(self):
try:
dict_data = next(self.iter)
time = random.randint(400, 600)
print('下一条回帖时间' + (datetime.datetime.now() + datetime.timedelta(seconds=time)).strftime("%H:%M:%S"))
self.timer = threading.Timer(time, self.__reply, [dict_data])
self.timer.start()
except StopIteration:
print('完成')
def __reply(self, dict_data):
print('开始回帖-' + dict_data['title'])
#省略回帖逻辑
print('回帖完成')
if self.timer is not None:
self.timer.cancel()
#回调函数中重新调用原函数
self.__set_time_reply()
并将成功执行完成的任务保存到本地以便查看和去重。
0x04 最后成果展示
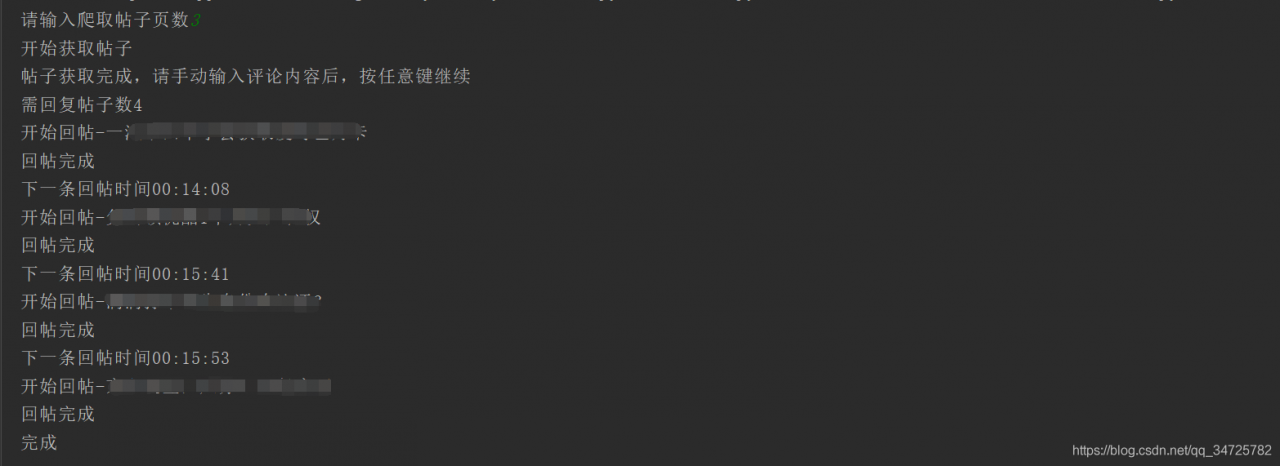
改进方向
由于需要人工审贴并发表评论这种半自动的操作方式,导致了该软件的效率不会很高。如果能根据贴子内容自动生成评论,那么其应用意义会更大。
对于纯图片贴,可以预设通用的话术,并对其进行随机的排列组合;
对于文字贴,可以提取其标题和内容生成摘要,但是摘要是否能作为评论内容,并通过论坛的人工审核还有待商榷。