NNLM(神经网络语言模型)
简介
NNLM是从语言模型出发(即计算概率角度),构建神经网络针对目标函数对模型进行最优化,训练的起点是使用神经网络去搭建语言模型实现词的预测任务,并且在优化过程后模型的副产品就是词向量。词向量对后面深度学习在自然语言处理方面有很大的贡献,也是获取词的语义特征的有效方法。[B站视频](https://www.bilibili.com/video/BV1AT4y1J7bv/)一、模型的网络结构
NNLM模型直接通过一个神经网络结构对n元条件概率进行评估,NNLM模型的基本结构如下:
二、模型的原理
2.1 模型的输入
首先从语料库中搜集一系列长度为n的文本序列,然后组成训练集C。
2.2 模型的输出
输出词典长度的所有概率值和索引,选取概率值最大的索引对应的单词,其为本次的预测单词。
三、模型的实践
3.1 目标、参数和计算流程
输入固定长度文本的前 n-1 个单词,然后预测出下一个(第n个)单词
3.2 代码实现
3.2.1 数据处理
import torch
import torch.nn as nn
import torch.optim as optimizer
import torch.utils.data as Data
dtype = torch.FloatTensor
#长度为3的文本序列
sentences = ['i like cat', 'i love coffee', 'i hate milk']
sentences_list = " ".join(sentences).split() # ['i', 'like', 'cat', 'i', 'love'. 'coffee',...]
vocab = list(set(sentences_list)) #词汇去重
word2idx = {w:i for i, w in enumerate(vocab)} #词转索引
idx2word = {i:w for i, w in enumerate(vocab)} #索引转词
V = len(vocab) #词表长度
3.2.2 获取输入与目标数据
def make_data(sentences): #定义输入与输出
input_data = [] #前n-1个词
target_data = [] #第n个词(预测词)
for sen in sentences:
sen = sen.split() #空格切分 ['i', 'like', 'cat']
input_tmp = [word2idx[w] for w in sen[:-1]] #获取前n-1个词的索引
target_tmp = word2idx[sen[-1]] #获取第n个词的索引
input_data.append(input_tmp) #依次存入列表中
target_data.append(target_tmp)
return input_data, target_data
input_data, target_data = make_data(sentences)
#将列表格式的数据转化为tensor格式
input_data, target_data = torch.LongTensor(input_data), torch.LongTensor(target_data)
dataset = Data.TensorDataset(input_data, target_data)
loader = Data.DataLoader(dataset, 2, True) #DataLoader(dataset,batchsize,shuffle)
# parameters
m = 2 #v为行,m维度(列)
n_step = 2 #n_step:输入数据的长度(单词个数)【i like cat,输入为 i like 则为2,i very like cat,输入为i very like 则为3】
n_hidden = 10 #隐藏层神经元个数
3.2.3 模型的定义
class NNLM(nn.Module): #定义NNLM模型
def __init__(self):
super(NNLM, self).__init__()
self.C = nn.Embedding(V, m) #将词汇表转化为词向量矩阵C,v为行,m维度
self.H = nn.Parameter(torch.randn(n_step * m, n_hidden).type(dtype))
self.d = nn.Parameter(torch.randn(n_hidden).type(dtype))
self.b = nn.Parameter(torch.randn(V).type(dtype))
self.W = nn.Parameter(torch.randn(n_step * m, V).type(dtype))
self.U = nn.Parameter(torch.randn(n_hidden, V).type(dtype))
#nn.Parameter()的作用是将该参数添加进模型中,使其能够通过model.parameters()找到、管理、并且更新。
#使用很简单:torch.nn.Parameter(data, requires_grad=True),其中data为tensor
def forward(self, X): #X : [batch_size, n_step]
X = self.C(X) #将词汇表转化为词向量矩阵[batch_size, n_step, m] batchsize行,n_step列,每列中有m列
X = X.view(-1, n_step * m) # [batch_szie, n_step * m] #将batchsize每行的n_step列拼接成一列
hidden_out = torch.tanh(self.d + torch.mm(X, self.H)) # [batch_size, n_hidden]
output = self.b + torch.mm(X, self.W) + torch.mm(hidden_out, self.U)
return output
model = NNLM()
optim = optimizer.Adam(model.parameters(), lr=1e-3)
criterion = nn.CrossEntropyLoss()
重点解析:简单解释一下执行 X=self.C(X) 这一步之后 X 发生了什么变化,假设初始 X=[[0, 1], [0, 3], 通过 Embedding() 之后,会将每一个词的索引,替换为对应的词向量,例如 love 这个词的索引是 3,通过查询 Word Embedding 表得到行索引为 3 的向量为 [0.2, 0.1],于是就会将原来 X 中 3 的值替换为该向量,所有值都替换完之后,X=[[[0.3, 0.8], [0.2, 0.4]], [[0.3, 0.8], [0.2, 0.1]]]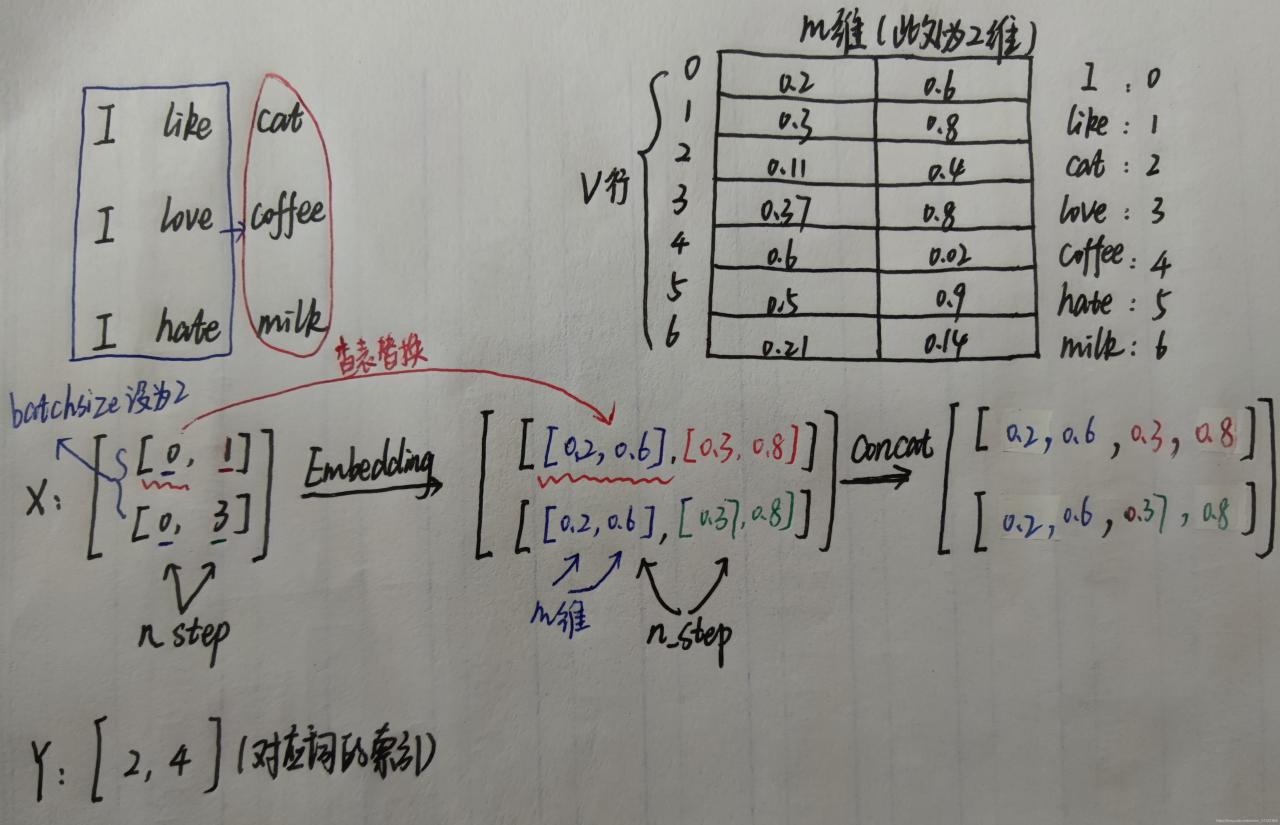
3.2.4 分类训练
#训练
for epoch in range(5000):
for batch_x, batch_y in loader:
pred = model(batch_x)
loss = criterion(pred, batch_y)
if (epoch + 1) % 1000 == 0:
print(epoch + 1, loss.item())
optim.zero_grad()
loss.backward()
optim.step()
3.2.5 测试
#model(input_data):输出对应7类(词表长度)的概率值 .max为取最大的那个值和索引
pred = model(input_data).max(1, keepdim=True)[1]
print([idx2word[idx.item()] for idx in pred.squeeze()])
四、特点
优点:使用NNLM模型生成的词向量是可以自定义维度的,维度并不会因为新扩展词而发生改变,而且这里生成的词向量能够很好的根据特征距离度量词与词之间的相似性。
缺点:计算复杂度过大,参数较多(word2vec是一种改进)。
版权声明:本文为weixin_51531865原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。