什么是ElasticSearch
Elaticsearch,简称为es,是一个开源的基于Lucene的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;其本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。它通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
ElasticSearch安装与启动
下载 ElasticSearch压缩包
ElasticSearch的官方地址: https://www.elastic.co/products/elasticsearch直接解压至某个目录
安装JDK,并设置JAVA_HOME环境变量
进入解压目录的bin文件夹,启动ElasticSearch
通过浏览器访问ElasticSearch服务器,看到如下返回的json信息,代表服务启动成功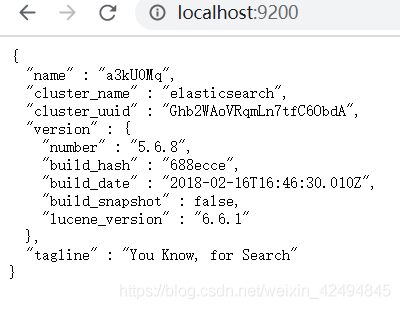
ElasticSearch概述
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。
索引 index
一个索引包含一堆有相似结构的文档数据。一个index包含多个document,一个index就代表一类类似的或者相同的document。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。
类型 type
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区。通常,会为具有一组共同字段的文档定义一个类型。
字段Field
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识,一个document里有多个field,每个field就是一个数据字段。
映射 mapping
mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,这些都是映射里面可以设置的,其它就是处理es里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。
文档 document
一个文档是一个可被索引的基础信息单元。文档以JSON(Javascript Object Notation)格式来表示。
在一个index/type里面,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type。
接近实时 NRT
Elasticsearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒以内)
在使用es自带的标准分词器时,会将中文的每一个字单独划分出来,这无疑不是我们想要的,我们想要的是词语,这时候就需要用到第三方的分词器
IK 分词器和ElasticSearch集成使用
IK分词器简介
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本。最初,它是以开源项目Lucene为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer3.0则发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。
IK分词器3.0的特性如下:
1)采用了特有的“正向迭代最细粒度切分算法“,具有60万字/秒的高速处理能力。
2)采用了多子处理器分析模式,支持:英文字母(IP地址、Email、URL)、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇(姓名、地名处理)等分词处理。
3)对中英联合支持不是很好,在这方面的处理比较麻烦.需再做一次查询,同时是支持个人词条的优化的词典存储,更小的内存占用。
4)支持用户词典扩展定义。
5)针对Lucene全文检索优化的查询分析器IKQueryParser;采用歧义分析算法优化查询关键字的搜索排列组合,能极大的提高Lucene检索的命中率。
IK分词器的安装
- 下载IK分词器,下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
- 解压,将解压后的elasticsearch文件夹拷贝到elasticsearch\plugins3下,并重命名文件夹为analysis-ik
- 重新启动ElasticSearch,即可加载IK分词器
使用elasticsearch提供的Restful接口直接访问
创建索引index和映射mapping
创建索引库名为index_name
创建type名为article
字段名Field有id,title,content
请求方式:put
请求url:
http://localhost:9200/index_name
请求体:
{
"mappings": {
"article": {
"properties": {
"id": {
"type": "long",
"store": true,
"index":"not_analyzed"
},
"title": {
"type": "text",
"store": true,
"index":"analyzed",
"analyzer":"ik_max_word"
},
"content": {
"type": "text",
"store": true,
"index":"analyzed",
"analyzer":"ik_max_word"
}
}
}
}
}
删除索引index
删除名为index_name的索引库
请求方式:delete
请求url:
http://localhost:9200/index_name
请求体:无
创建文档document
在索引库index_name下的article类型下创建文档,文档id为1
请求方式:post
请求url:
http://localhost:9200/index_name/article/1
请求体:
{
"id":1,
"title":"新增的文档名",
"content":"新增的文档内容。"
}
修改文档document
直接覆盖原有文档
请求方式:post
请求url:
http://localhost:9200/index_name/article/1
请求体:
{
"id":1,
"title":"修改的文档名",
"content":"修改的文档内容。"
}
删除文档document
删除索引库index_name下的article类型下id为1的文档
请求方式:delete
请求url:
http://localhost:9200/index_name/article/1
请求体:无
查询文档-根据id查询
查询索引库index_name下的article类型下id为1的文档
请求方式:get
请求url:
http://localhost:9200/index_name/article/1
请求体:无
查询文档-querystring查询
首先es会将“搜索的内容”进行分词,得到一个词语列表,然后查询索引库index_name下的article类型下文档内容中含有的词语列表中的词语的文档
请求方式:post
请求url:
http://localhost:9200/index_name/article/_search
请求体:
{
"query": {
"query_string": {
"default_field": "content",
"query": "搜索的内容"
}
}
}
查询文档-term查询
查询索引库index_name下的article类型下文档标题含有"文章"的文档
请求方式:post
请求url:
http://localhost:9200/index_name/article/_search
请求体:
{
"query": {
"term": {
"title": "文章"
}
}
}
今天分享的关于ElasticSearch的内容就到这里了,希望大家能够有所收获,欢迎关注。