Java基础知识
廖雪峰Java教程笔记。廖雪峰Java教程链接。
java简介
java介于编译型语言和解释型语言之间。Java将代码编译成一种“字节码”,类似于抽象的CPU指令,针对不同平台编写虚拟机,不同平台的虚拟机负责加载字节码执行,这样,对Java开发者而言,就实现了 “一次编写,到处执行” 的效果。
对于虚拟机,需要对每个平台分别开发。
名词解释
- JDK:Java Development Kit
- JRE:Java Runtime Environment
简单来说,JRE就是运行Java字节码的虚拟机。但是,如果只有Java源码,要编译成Java字节码,就需要JDK,因为JDK除了包含JRE,还提供了编译器、调试器等开发工具。
两者关系如下:
- JSR规范:Java Specification Request
- JCP组织:Java Community Process
为了保证Java语言的规范性,SUN公司搞了一个JSR规范,凡是想给Java平台加一个功能,比如说访问数据库的功能,大家要先创建一个JSR规范,定义好接口,这样,各个数据库厂商都按照规范写出Java驱动程序,开发者就不用担心自己写的数据库代码在MySQL上能跑,却不能跑在PostgreSQL上。
所以JSR是一系列的规范,从JVM的内存模型到Web程序接口,全部都标准化了。而负责审核JSR的组织就是JCP。
一个JSR规范发布时,为了让大家有个参考,还要同时发布一个“参考实现”,以及一个“兼容性测试套件”:
- RI:Reference Implementation
- TCK:Technology Compatibility Kit
运行Java程序
Java源码本质上是一个文本文件,先用javac把Hello.java编译成字节码文件Hello.class,然后,用java命令执行这个字节码文件:
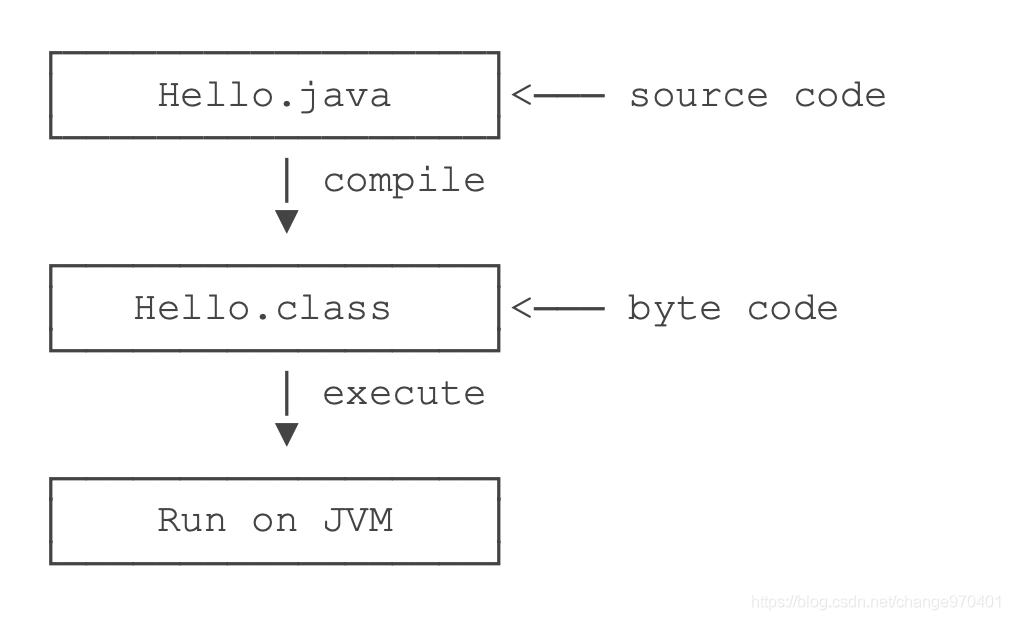
可执行文件javac是编译器,可执行文件java是虚拟机。
Java基本数据类型
Java基本数据类型占用的字节数: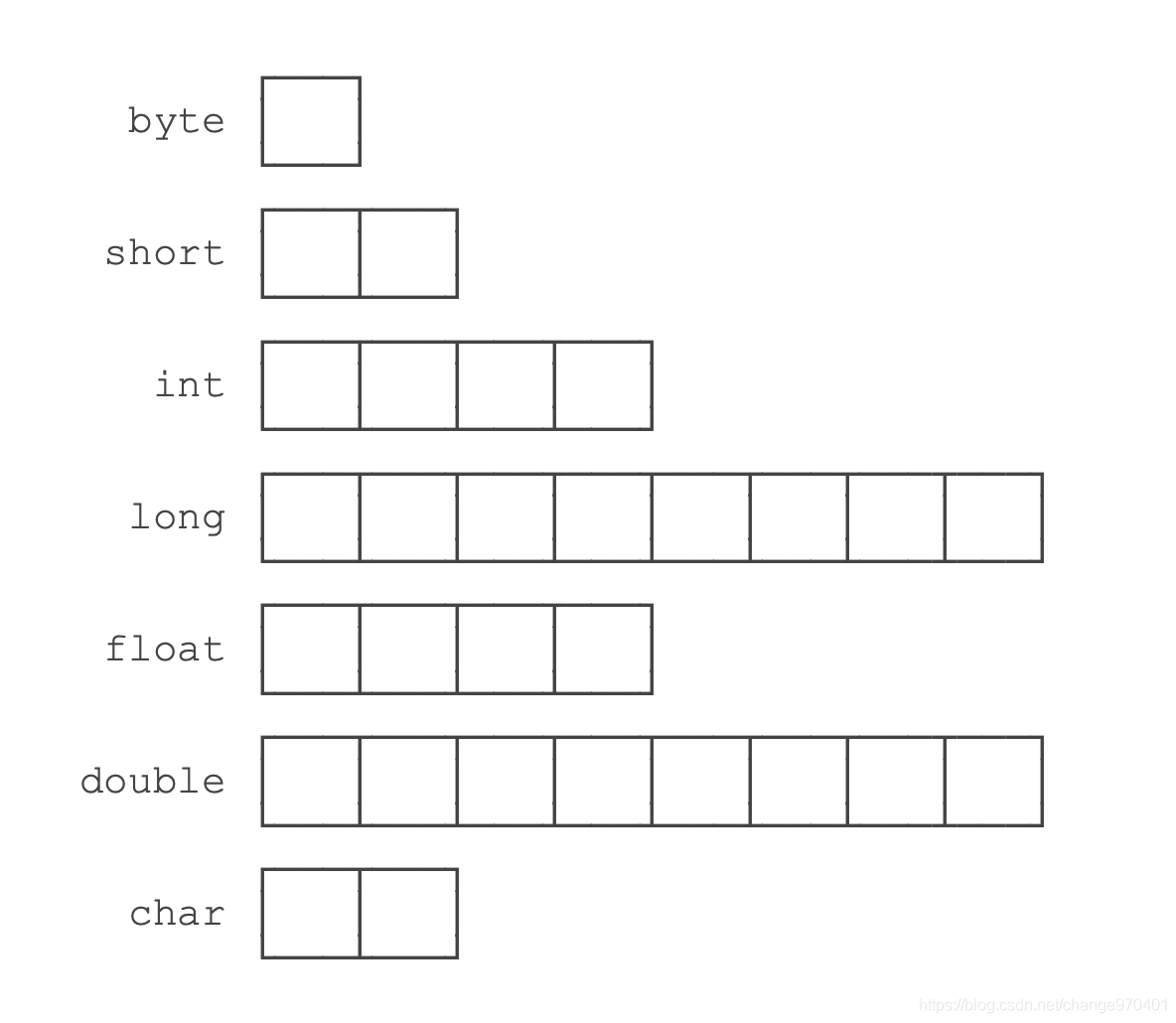
byte恰好是一个字节,long和double需要8个字节。
模块
廖雪峰模块教程链接
从Java 9开始,原有的Java标准库已由一个单一巨大的rt.jar拆分成了几十个模块,这些模块以.jmod扩展名标识。模块之间的依赖关系已经被写入到模块内的module-info.class中了。
模块可以用来打包JRE。
包装类型
廖雪峰链接
Java对每种基本类型都提供了对应的引用类型。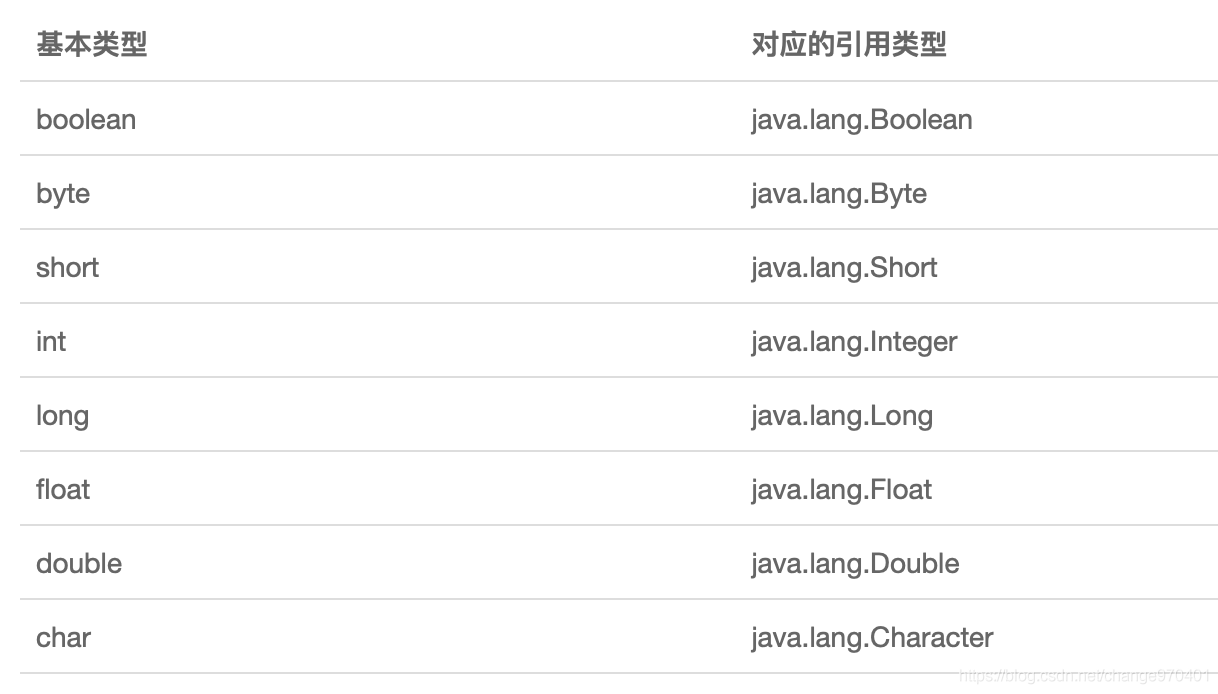
记录类
用record关键字定义记录类,方便定义不变类。
具体内容
异常处理
Java异常
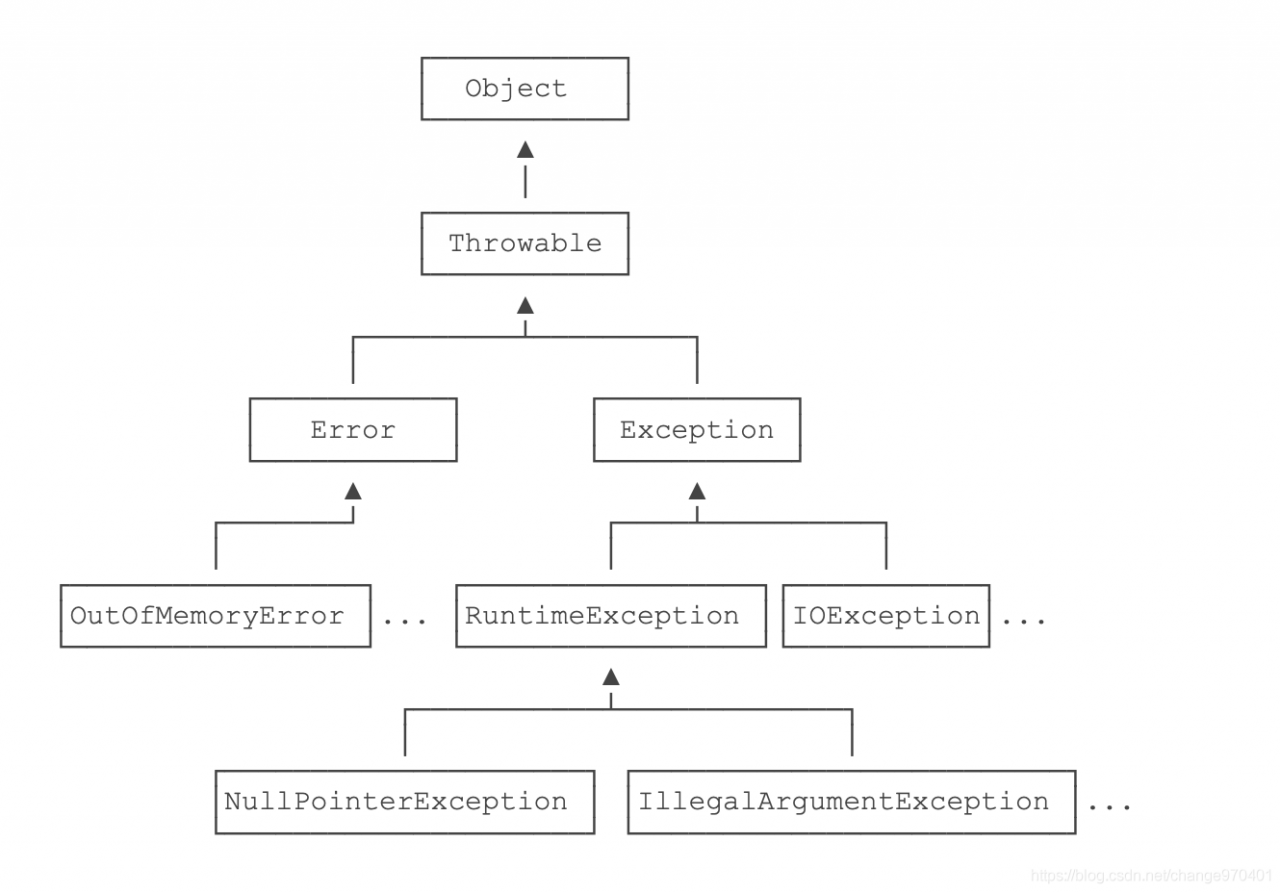
Java规定:
- 必须捕获的异常,包括Exception及其子类,但不包括RuntimeException及其子类,这种类型的异常称为Checked Exception。
- 不需要捕获的异常,包括Error及其子类,RuntimeException及其子类。
调用printStackTrace可以打印异常的传播栈,对于调试非常有用。
Java标准库中常用的异常类型有:
使用Commons Logging
和Java标准库提供的日志不同,Commons Logging是一个第三方日志库,它是由Apache创建的日志模块。
Commons Logging的特色是,它可以挂接不同的日志系统,并通过配置文件指定挂接的日志系统。默认情况下,Commons Loggin自动搜索并使用Log4j(Log4j是另一个流行的日志系统),如果没有找到Log4j,再使用JDK Logging。
使用Commons Logging只需要和两个类打交道,并且只有两步:
第一步,通过LogFactory获取Log类的实例; 第二步,使用Log实例的方法打日志。
使用log4j
Commons Logging作为“日志接口”来使用,而真正“日志实现”可以使用log4j。
反射
反射是为了解决在运行期间,对某个实例一无所知的情况下,如何调用其方法。
JVM为每个加载的class及interface创建了对应的Class实例来保存class及interface的所有信息;
获取一个class对应的Class实例后,就可以获取该class的所有信息;
通过Class实例获取class信息的方法称为反射(Reflection);
JVM总是动态加载class,可以在运行期根据条件来控制加载class。
动态代理
不编写实现类,在运行期间直接创建某个interface的实例,可以用动态代理来实现。
动态代理是通过Proxy创建代理对象,然后将接口方法“代理”给InvocationHandler完成的。
泛型
泛型就是定义一种模板,例如ArrayList<T>,然后在代码中为用到的类创建对应的ArrayList<类型>
擦拭法
Java语言的泛型实现采用的是擦拭法,也就是说编译器完成工作,虚拟机对此一无所知。编译器内部永远把<T>视为Object类型,但在需要转型的时候,编译器会根据T的类型自动实现安全的强制转型。
Java泛型的局限:
- <T>不能是基本类型,因为实际的类型是Object,Object类型无法持有基本类型。
- 无法获取带泛型的Class。
- 无法判断带泛型的类型。
- 不能实例化T类型。
extends & super
对比extends和super通配符
我们再回顾一下extends通配符。作为方法参数,extends类型和super类型的区别在于:
extends允许调用读方法T get()获取T的引用,但不允许调用写方法set(T)传入T的引用(传入null除外);
super允许调用写方法set(T)传入T的引用,但不允许调用读方法T get()获取T的引用(获取Object除外)。
一个是允许读不允许写,另一个是允许写不允许读。
集合
Java集合的设计有几个特点:一是实现了接口和实现类分离,例如,有序表的接口为List,具体的实现类有ArrayList,LinkedList等;二是支持泛型,可以限制在一个集合中只放入相同类型的元素;最后,Java访问集合总是通过统一的方式——迭代器实现的,它的好处在于无需知道集合内部的元素是按什么方式存储的。
由于Java的集合设计非常久远,中间经历过大规模改进,我们要注意到有一小部分集合类是遗留类,不应该继续使用:
- Hashtable:一种线程安全的Map实现;
- Vector:一种线程安全的List实现;
- Stack:基于Vector实现的LIFO的栈。 还有一小部分接口是遗留接口,也不应该继续使用:
- Enumeration:已被Iterator取代。
使用List
遍历List
遍历LinkedList不推荐用for循环+get(int),推荐使用iterator。
List<String> list = List.of("apple", "pear", "banana");
for(Iterator<String> it = list.iterator(); it.hasNext();){
String s = it.next();
}
使用Map
编写equals()和hashCode()
要正确使用HashMap,作为key的类必须正确覆写equals()和hashCode()方法;
一个类如果覆写了equals(),就必须覆写hashCode(),并且覆写规则是:
如果equals()返回true,则hashCode()返回值必须相等;
如果equals()返回false,则hashCode()返回值尽量不要相等。
实现hashCode()方法可以通过Objects.hashCode()辅助方法实现。
- equals():引用类型使用Objects.equals()比较,基本类型用==
- hashCode():借助Objects.hash()
编写equals()和hashCode()遵循的原则是:
equals()用到的用于比较的每一个字段,都必须在hashCode()中用于计算;equals()中没有使用到的字段,绝不可放在hashCode()中计算。
使用enumMap()
因为HashMap是一种通过对key计算hashCode(),通过空间换时间的方式,直接定位到value所在的内部数组的索引,效率很高。
如果作为key的对象是enum类型,那么,还可以使用Java集合库提供的一种EnumMap,它在内部以一个非常紧凑的数组存储value,并且根据enum类型的key直接定位到内部数组的索引,并不需要计算hashCode(),不但效率最高,而且没有额外的空间浪费。
使用TreeMap
HashMap是一种空间换时间的映射表,它的实现原理决定了内部的key是无序的,即遍历HashMap的Key时,其顺序是不可预测的。
还有一种Map,它会在内部对Key进行排序,这种Map就是SortedMap。SortedMap只是接口,实现类时TreeMap。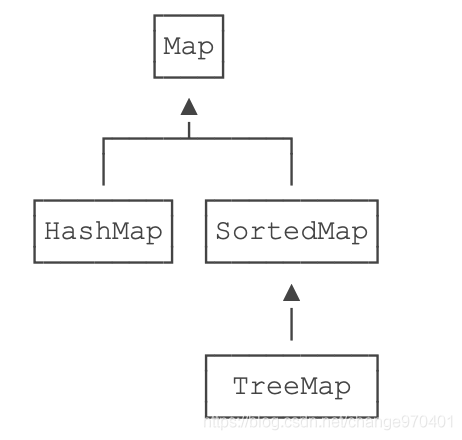
使用TreeMap时,放入的Key必须实现Comparable接口。String、Integer这些类已经实现了Comparable接口,因此可以直接作为Key使用。作为Value的对象则没有任何要求。
如果作为Key的class没有实现Comparable接口,那么,必须在创建TreeMap时同时指定一个自定义排序算法:
Map<Person, Integer> map = new TreeMap<>(new Comparator<Person>(){
public int compare(Person p1, Person p2){
return p1.name.compareTo(p2.name);
}
})
Person类不用覆写equals和hashCode,因为TreeMap不使用它们。
使用Queue

LinkedList即实现了List接口,又实现了Queue接口
PriorityQueue
放入PriorityQueue的元素,必须实现Comparable接口,PriorityQueue会根据元素的排序顺序决定出队的优先级。
Deque
Deque是一个接口,它的实现类有ArrayDeque和LinkedList。
Stack
在Java中,我们用Deque可以实现Stack的功能:
- 把元素压栈:push(E)/addFirst(E);
- 把栈顶的元素“弹出”:pop(E)/removeFirst();
- 取栈顶元素但不弹出:peek(E)/peekFirst()。
当我们把Deque作为Stack使用时,注意只调用push()/pop()/peek()方法,不要调用addFirst()/removeFirst()/peekFirst()方法,这样代码更加清晰。
IO
InputStream/OutputStream
IO流以byte(字节)为最小单位,因此也称为字节流。
Reader/Writer
如果需要读写的是字符,并且字符不全是单字节表示的ASCII字符,使用char来读写更加方便,这种称为字符流。
Java提供了Reader和Writer两种字符流,传输的最小单位是char。
Reader和Writer本质上是一个能自动编解码的InputStream和OutputStream。
同步和异步
同步IO是指,读写IO时代码必须等待数据返回后才继续执行后续代码,它的优点是代码编写简单,缺点是CPU执行效率低。
而异步IO是指,读写IO时仅发出请求,然后立刻执行后续代码,它的优点是CPU执行效率高,缺点是代码编写复杂。
Java标准库的包java.io提供了同步IO,而java.nio则是异步IO。上面我们讨论的InputStream、OutputStream、Reader和Writer都是同步IO的抽象类,对应的具体实现类,以文件为例,有FileInputStream、FileOutputStream、FileReader和FileWriter。
Filter
Java的IO标准库使用Filter模式为InputStream和OutputStream增加功能:
可以把一个InputStream和任意个FilterInputStream组合;
可以把一个OutputStream和任意个FilterOutputStream组合。
Filter模式可以在运行期动态增加功能(又称Decorator模式)。
单元测试
本节介绍Java最常用的测试框架JUnit。单元测试是对Java的方法进行测试。
使用JUnit
JUnit是一个开源的Java语言的单元测试框架,专门针对Java设计,使用最广泛。JUnit是事实上的单元测试的标准框架,任何Java开发者都应当学习并使用JUnit编写单元测试。
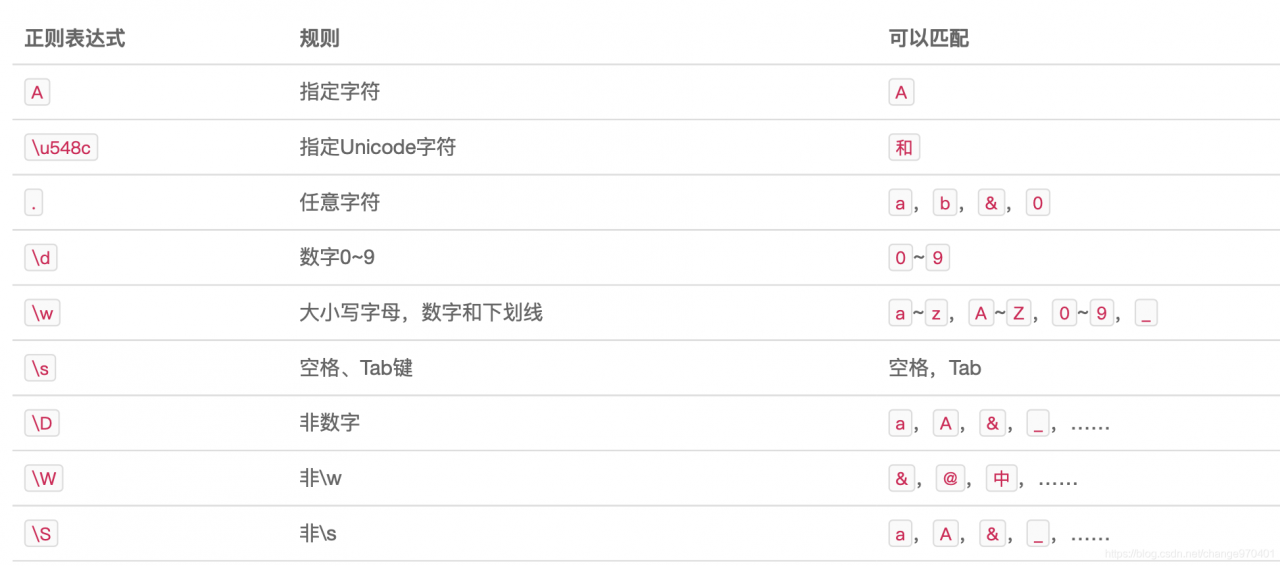
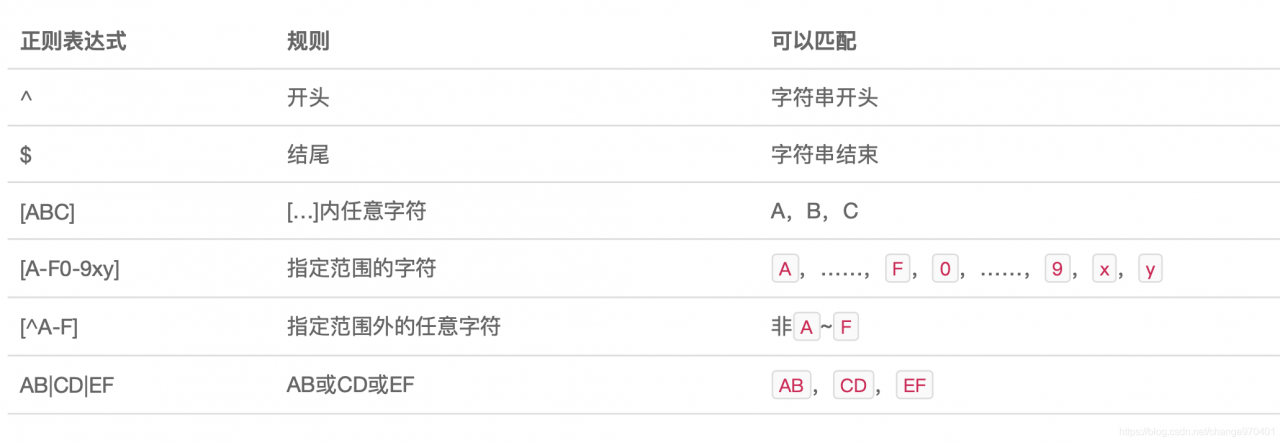
正则表达式
Java标准库的java.util.regex包内置了正则表达式引擎,在Java程序中使用正则表达式非常简单。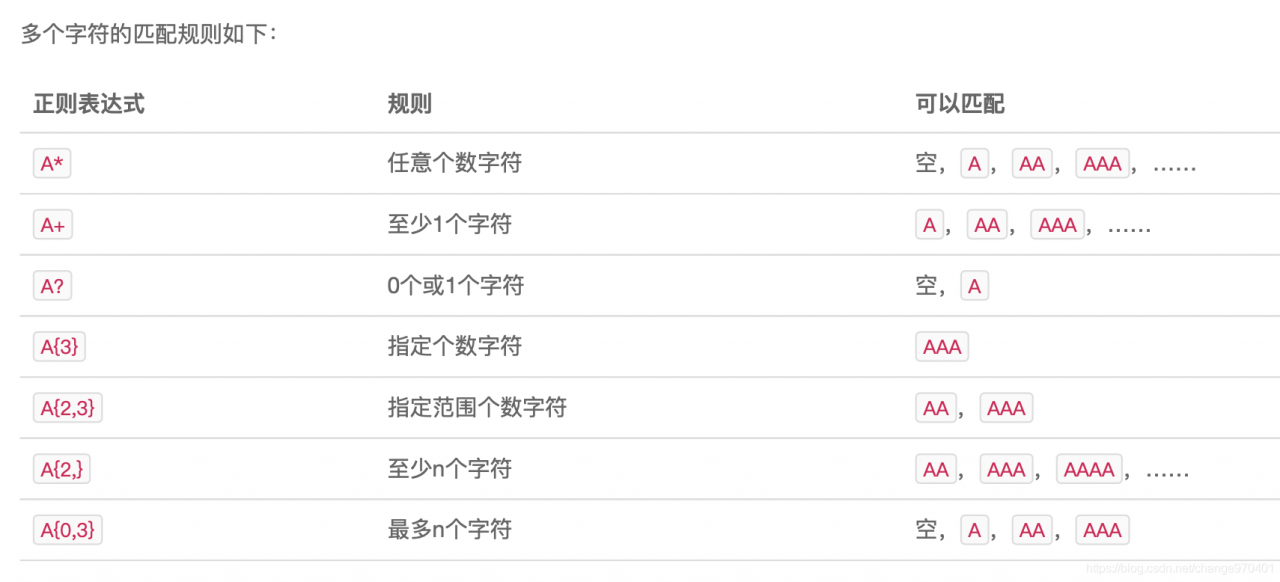
Pattern
我们在前面的代码中用到的正则表达式代码是String.matches()方法,而我们在分组提取的代码中用的是java.util.regex包里面的Pattern类和Matcher类。实际上这两种代码本质上是一样的,因为String.matches()方法内部调用的就是Pattern和Matcher类的方法。
但是反复使用String.matches()对同一个正则表达式进行多次匹配效率较低,因为每次都会创建出一样的Pattern对象。完全可以先创建出一个Pattern对象,然后反复使用,就可以实现编译一次,多次匹配:
Pattern pattern = Pattern.compile("(\\d{3,4})\\-(\\d{7,8})");
pattern.matcher("010-12345678").matches(); // true
pattern.matcher("021-123456").matches(); // true
非贪婪匹配
正则匹配默认贪婪匹配,若要实现非贪婪匹配需要在某一规则后加?.
多线程
进程vs线程
进程和线程是包含关系,但是多任务既可以由多进程实现,也可以由单进程内的多线程实现,还可以混合多进程+多线程。
和多线程相比,多进程的缺点是:
- 创建进程的开销比创建线程大,尤其是在Windows系统上;
- 进程间的通信比线程间的慢,因为线程之间的通信就是读写同一个变量,速度很快。
而多进程的优点是:
多进程稳定性比多线程高,因为在多进程的情况下,一个进程崩溃不会影响其他进程,而在多线程的情况下,任何一个线程崩溃会直接导致整个进程崩溃。
JVM
Java语言内置了多线程支持:一个Java程序实际上是一个JVM进程,JVM进程用一个线程来执行main()方法,在main()方法内部,又可以启动多个线程。此外,JVM还有负责垃圾回收的其他工作线程等。
在Java程序中,一个线程对象只能调用一次start()方法启动新线程,并在新线程中执行run()方法。一旦run()方法执行结束,线程就结束了。因此,Java线程的状态有以下几种:
- New:新创建的线程,尚未执行;
- Runnable:运行中的线程,正在执行run()方法的Java代码;
- Blocked:运行中的线程,因为某些操作被阻塞而挂起;
- Waiting:运行中的线程,因为某些操作在等待中;
- Timed Waiting:运行中的线程,因为执行sleep()方法正在计时等待;
- Terminated:线程已终止,因为run()方法执行完毕。
当线程启动后,它可以在Runnable、Blocked、Waiting和Timed Waiting这几个状态之间切换,直到最后变成Terminated状态,线程终止。
线程终止的原因有:
- 线程正常终止:run()方法执行到return语句返回;
- 线程意外终止:run()方法因为未捕获的异常导致线程终止;
- 对某个线程的Thread实例调用stop()方法强制终止(强烈不推荐使用)。
一个线程还可以等待另一个线程直到其运行结束。例如,main线程在启动t线程后,可以通过t.join()等待t线程结束后再继续运行。
线程中断
1.线程可以通过调用t.interrupt()从而通知t线程中断;
2.另一个常用的中断线程的方法是设置标志位,通常会通过一个running标识位来标识线程是否应该继续运行,在外部线程中,通过把HelloThread.running置为false,就可以让线程结束。
注意到HelloThread的标识位boolean running是一个线程间共享的变量。线程间共享变量需要用volatile关键字标记,确保每个线程都能读取到更新后的变量值。
为什么要对线程间共享的变量用关键字volatile声明?这涉及到Java的内存模型。在Java虚拟机中,变量的值保存在主内存中,但是,当线程访问变量时,它会先获取一个副本,并保存在自己的工作内存中。如果线程修改了变量的值,虚拟机会在某个时刻把修改后的值回写到主内存,但是,这个时间是不确定的。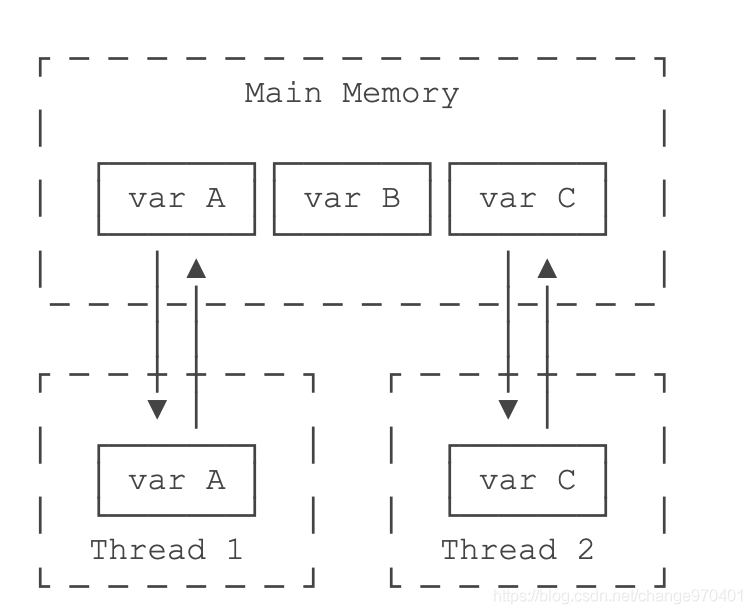
这会导致如果一个线程更新了某个变量,另一个线程读取的值可能还是更新前的。例如,主内存的变量a = true,线程1执行a = false时,它在此刻仅仅是把变量a的副本变成了false,主内存的变量a还是true,在JVM把修改后的a回写到主内存之前,其他线程读取到的a的值仍然是true,这就造成了多线程之间共享的变量不一致。
因此,volatile关键字的目的是告诉虚拟机:
- 每次访问变量时,总是获取主内存的最新值;
- 每次修改变量后,立刻回写到主内存。
线程同步
Java程序使用synchronized关键字对一个对象进行加锁:
synchronized(lock){
n = n + 1;
}
synchronized保证了代码块在任意时刻最多只有一个线程能执行。
public class Main {
public static void main(String[] args) throws Exception {
var add = new AddThread();
var dec = new DecThread();
add.start();
dec.start();
add.join();
dec.join();
System.out.println(Counter.count);
}
}
class Counter {
public static final Object lock = new Object();
public static int count = 0;
}
class AddThread extends Thread {
public void run() {
for (int i=0; i<10000; i++) {
synchronized(Counter.lock) {
Counter.count += 1;
}
}
}
}
class DecThread extends Thread {
public void run() {
for (int i=0; i<10000; i++) {
synchronized(Counter.lock) {
Counter.count -= 1;
}
}
}
}
总结如何使用synchronized:
- 找出修改共享变量的代码块;
- 选择一个共享实例作为锁;
- 使用sychorized(lockObject){…}
在使用synchronized时,不必担心抛出异常。因为无论是否有异常,都会在synchronized结束出正确释放锁。
死锁
Java的线程锁是可重入的锁。JVM允许同一个线程重复获取同一个锁,这种能被同一个线程反复获取的锁,就叫做可重入锁。
死锁产生的条件是多线程各自持有不同的锁,并互相试图获取对方已持有的锁,导致无限等待;
避免死锁的方法是多线程获取锁的顺序要一致。
线程同步
wait和notify用于多线程协调运行:
- 在synchronized内部可以调用wait()使线程进入等待状态;
- 必须在已获得的锁对象上调用wait()方法;
- 在synchronized内部可以调用notify()或notifyAll()唤醒其他等待线程;
- 必须在已获得的锁对象上调用notify()或notifyAll()方法;
- 已唤醒的线程还需要重新获得锁后才能继续执行。
使用ReentrantLock
从Java 5开始,引入了一个高级的处理并发的java.util.concurrent包,它提供了大量更高级的并发功能,能大大简化多线程程序的编写。
我们知道Java语言直接提供了synchronized关键字用于加锁,但这种锁一是很重,二是获取时必须一直等待,没有额外的尝试机制。
java.util.concurrent.locks包提供的ReentrantLock用于替代synchronized加锁。
ReentrantLock可以替代synchronized进行同步;
ReentrantLock获取锁更安全;
必须先获取到锁,再进入try {…}代码块,最后使用finally保证释放锁;
可以使用tryLock()尝试获取锁。
使用Condition
Condition可以替代wait和notify。
使用Condition时,引用的Condition对象必须从Lock实例的newCondition()返回,这样才能获得一个绑定了Lock实例的Condition实例。
Condition提供的await()、signal()、signalAll()原理和synchronized锁对象的wait()、notify()、notifyAll()是一致的,并且其行为也是一样的:
- await()会释放当前锁,进入等待状态;
- signal()会唤醒某个等待线程;
- signalAll()会唤醒所有等待线程;
- 唤醒线程从await()返回后需要重新获得锁。
使用ReadWriteLock
允许多个线程同时读,但只要有一个线程在写,其他线程就必须等待: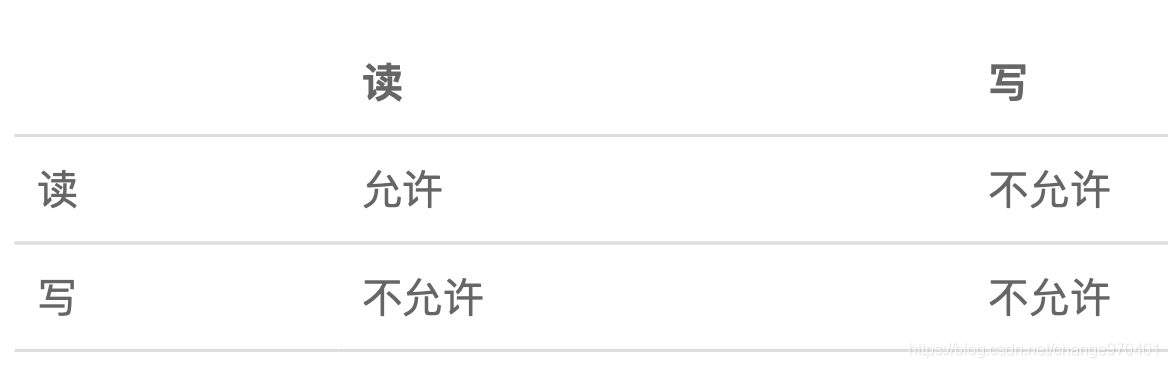
使用ReadWriteLock时,适用条件是同一个数据,有大量线程读取,但仅有少数线程修改。
例如,一个论坛的帖子,回复可以看做写入操作,它是不频繁的,但是,浏览可以看做读取操作,是非常频繁的,这种情况就可以使用ReadWriteLock。
使用StampedLock
如果我们深入分析ReadWriteLock,会发现它有个潜在的问题:如果有线程正在读,写线程需要等待读线程释放锁后才能获取写锁,即读的过程中不允许写,这是一种悲观的读锁。
要进一步提升并发执行效率,Java 8引入了新的读写锁:StampedLock。
StampedLock和ReadWriteLock相比,改进之处在于:读的过程中也允许获取写锁后写入!这样一来,我们读的数据就可能不一致,所以,需要一点额外的代码来判断读的过程中是否有写入,这种读锁是一种乐观锁。
乐观锁的意思就是乐观地估计读的过程中大概率不会有写入,因此被称为乐观锁。反过来,悲观锁则是读的过程中拒绝有写入,也就是写入必须等待。显然乐观锁的并发效率更高,但一旦有小概率的写入导致读取的数据不一致,需要能检测出来,再读一遍就行。
public class Point {
private final StampedLock stampedLock = new StampedLock();
private double x;
private double y;
public void move(double deltaX, double deltaY) {
long stamp = stampedLock.writeLock(); // 获取写锁
try {
x += deltaX;
y += deltaY;
} finally {
stampedLock.unlockWrite(stamp); // 释放写锁
}
}
public double distanceFromOrigin() {
long stamp = stampedLock.tryOptimisticRead(); // 获得一个乐观读锁
// 注意下面两行代码不是原子操作
// 假设x,y = (100,200)
double currentX = x;
// 此处已读取到x=100,但x,y可能被写线程修改为(300,400)
double currentY = y;
// 此处已读取到y,如果没有写入,读取是正确的(100,200)
// 如果有写入,读取是错误的(100,400)
if (!stampedLock.validate(stamp)) { // 检查乐观读锁后是否有其他写锁发生
stamp = stampedLock.readLock(); // 获取一个悲观读锁
try {
currentX = x;
currentY = y;
} finally {
stampedLock.unlockRead(stamp); // 释放悲观读锁
}
}
return Math.sqrt(currentX * currentX + currentY * currentY);
}
}
和ReadWriteLock相比,写入的加锁是完全一样的,不同的是读取。注意到首先我们通过tryOptimisticRead()获取一个乐观读锁,并返回版本号。接着进行读取,读取完成后,我们通过validate()去验证版本号,如果在读取过程中没有写入,版本号不变,验证成功,我们就可以放心地继续后续操作。如果在读取过程中有写入,版本号会发生变化,验证将失败。在失败的时候,我们再通过获取悲观读锁再次读取。由于写入的概率不高,程序在绝大部分情况下可以通过乐观读锁获取数据,极少数情况下使用悲观读锁获取数据。
可见,StampedLock把读锁细分为乐观读和悲观读,能进一步提升并发效率。但这也是有代价的:一是代码更加复杂,二是StampedLock是不可重入锁,不能在一个线程中反复获取同一个锁。
StampedLock还提供了更复杂的将悲观读锁升级为写锁的功能,它主要使用在if-then-update的场景:即先读,如果读的数据满足条件,就返回,如果读的数据不满足条件,再尝试写。
使用Concurrent集合
针对List、Map、Set、Deque等,java.util.concurrent包也提供了对应的并发集合类。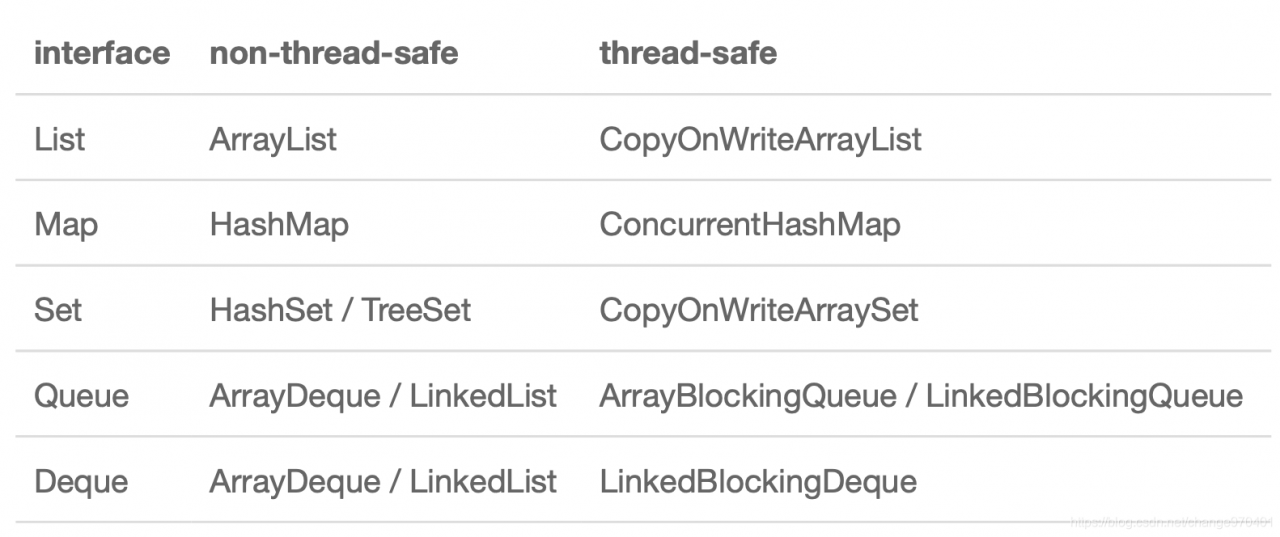
使用Atomic
Java的java.util.concurrent包除了提供底层锁、并发集合外,还提供了一组原子操作的封装类,它们位于java.util.concurrent.atomic包。
Atomic类是通过无锁(lock-free)的方式实现的线程安全(thread-safe)访问。它的主要原理是利用了CAS:Compare and Set。
使用线程池
Java语言虽然内置了多线程支持。启动一个新线程非常方便,但是,创建线程需要操作系统资源(线程资源、栈空间等),频繁创建和销毁大量线程需要消耗大量时间。
如果可以复用一组线程: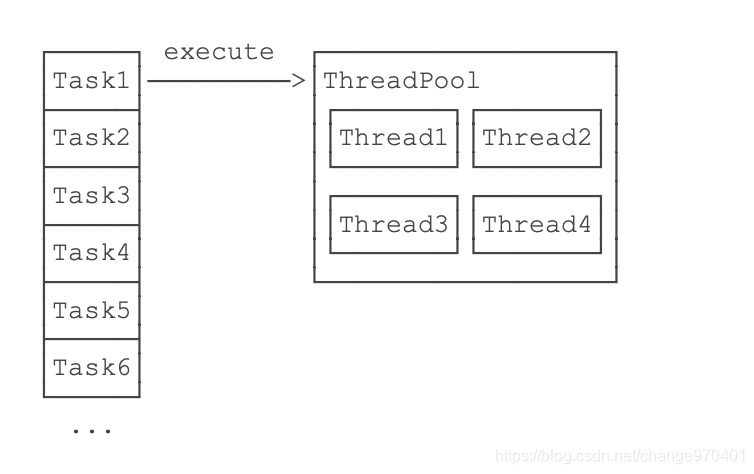
那么我们可以把很多的小任务让一组线程来执行,而不是一个任务对应一个新线程。这种能接收大量小任务并进行分发处理的就是线程池。
线程池内部维护了若干个线程,没有任务的时候,这些线程都处于等待状态,如果有新任务,就分配一个空闲线程执行。如果所有线程都处于忙绿状态,新任务要么放入队列等待,要么增加一个新线程进行处理。
Java标准库提供了ExecutorService接口表示线程池。
因为ExecutorService只是接口,Java标准库提供的几个常用实现类有:
- FixedThreadPool:线程数固定的线程池;
- CachedThreadPool:线程数根据任务动态调整的线程池
- SingleThreadExecutor:仅单线程执行的线程池。
使用ForkJoin
Java 7开始引入了一种新的Fork/Join线程池,它可以执行一种特殊的任务:把一个大任务拆成多个小任务并行执行。
这就是Fork/Join任务的原理:判断一个任务是否足够小,如果是,直接计算,否则,就分拆成几个小任务分别计算。这个过程可以反复“裂变”成一系列小任务。
Maven
Maven介绍
Maven就是是专门为Java项目打造的管理和构建工具,它的主要功能有:
- 提供了一套标准化的项目结构;
- 提供了一套标准化的构建流程(编译,测试,打包,发布……);
- 提供了一套依赖管理机制。
Maven项目结构
一个使用Maven管理的普通的Java项目,它的目录结构默认如下:
项目的根目录a-maven-project是项目名,它有一个项目描述文件pom.xml,存放Java源码的目录是src/main/java,存放资源文件的目录是src/main/resources,存放测试源码的目录是src/test/java,存放测试资源的目录是src/test/resources,最后,所有编译、打包生成的文件都放在target目录里。这些就是一个Maven项目的标准目录结构。
groupId类似于Java的包名,通常是公司或组织名称,artifactId类似于Java的类名,通常是项目名称,再加上version,一个Maven工程就是由groupId,artifactId和version作为唯一标识。
模块化管理
Maven支持模块化管理,可以把一个大项目拆成几个模块:
可以通过继承在parent的pom.xml统一定义重复配置;
可以通过编译多个模块。
JDBC编程
Java为关系数据库定义了一套标准的访问接口:JDBC(Java Database Connectivity)。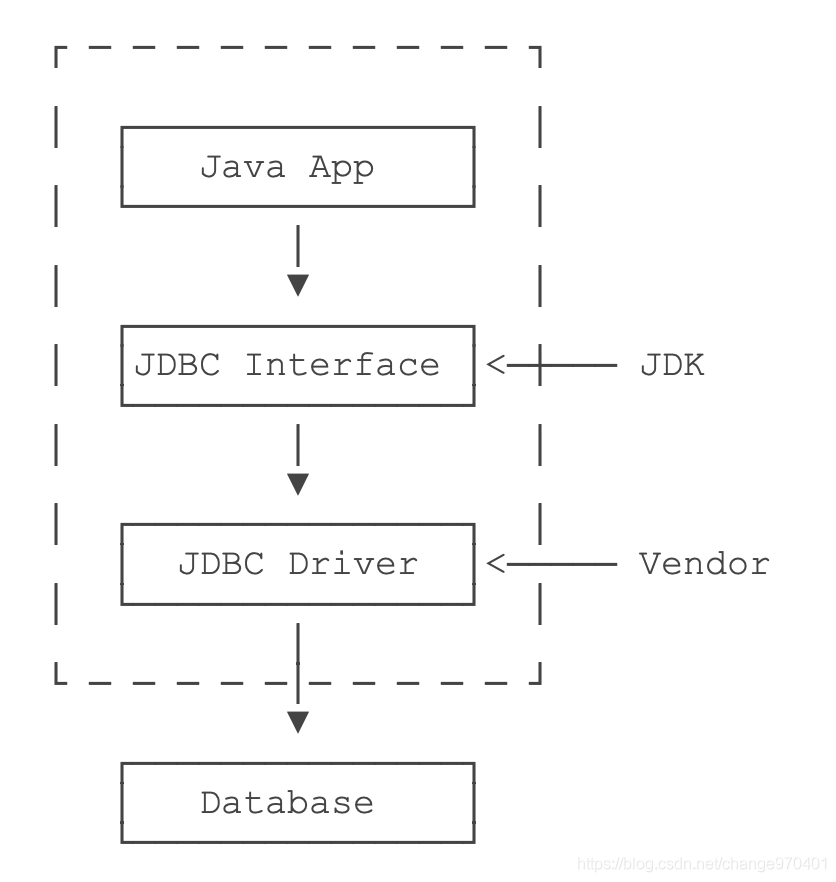
实际上,一个MySQL的JDBC的驱动就是一个jar包,它本身也是纯Java编写的。我们自己编写的代码只需要引用Java标准库提供的java.sql包下面的相关接口,由此再间接地通过MySQL驱动的jar包通过网络访问MySQL服务器,所有复杂的网络通讯都被封装到JDBC驱动中,因此,Java程序本身只需要引入一个MySQL驱动的jar包就可以正常访问MySQL服务器: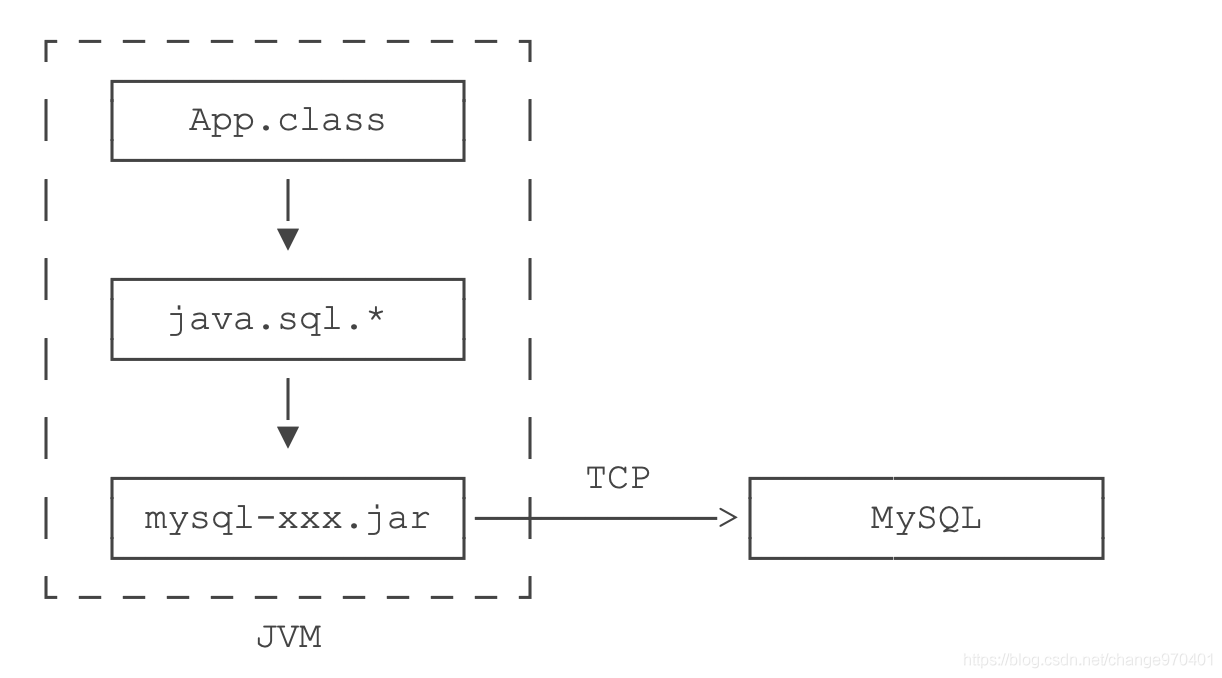
JDBC事务
数据库事务(Transaction)是由若干个SQL语句构成的一个操作序列,有点类似于Java的synchronized同步。数据库系统保证在一个事务中的所有SQL要么全部执行成功,要么全部不执行,即数据库事务具有ACID特性:
- Atomicity:原子性
- Consistency:一致性
- Isolation:隔离性
- Durability:持久性
数据库事务可以并发执行,而数据库系统从效率考虑,对事务定义了不同的隔离级别。SQL标准定义了4种隔离级别,分别对应可能出现的数据不一致的情况:
函数式编程
函数式编程的一个特点就是,允许把函数本身作为参数传入另一个函数,还允许返回一个函数。Java平台从Java8开始,支持函数式编程。
函数式编程(Functional Programming)是把函数作为基本运算单元,函数可以作为变量,可以接收函数,还可以返回函数。历史上研究函数式编程的理论是Lambda演算,所以我们经常把支持函数式编程的编码风格称为Lambda表达式。
Lambda表达式
在Java程序中,我们经常遇到一大堆单方法接口,即一个接口只定义了一个方法:
- Comparator
- Runnable
- Callable
以Comparator为例,我们想要调用Arrays.sort()时,可以传入一个Comparator实例,以匿名类方式编写如下:
String[] array = Arrays.sort(array, new Comparator<String>() { public int compare(String s1, String s2){
return s1.compareTo(s2);
}
});
上述写法非常繁琐。从Java 8开始,我们可以用Lambda表达式替换单方法接口。改写上述代码如下:
//Lambda
import java.util.Arrays;
public class Main{
public static void main(String[] args){
String[] array = new String[]{"apple","orange","banana"};
Arrays.sort(array, (s1, s2)->{
return s1.comparaTe(s2);
});
}
}
观察Lambda表达式的写法,它只需要写出方法定义:
(s1, s2)->{
return s1.compareTo(s2);
}
其中,参数是(s1, s2),参数类型可以省略,因为编译器可以自动推断出String类型。-> { … }表示方法体,所有代码写在内部即可。Lambda表达式没有class定义,因此写法非常简洁。
如果只有一行return xxx的代码,完全可以用更简单的写法:
Arrays.sort(array, (s1, s2)->s1.compareTo(s2));
返回值的类型也是由编译器自动推断的,这里推断出的返回值是int,因此,只要返回int,编译器就不会报错。
FunctionalInterface
我们把只定义了单方法的接口称之为FunctionalInterface,用注解@FunctionalInterface标记。例如,Callable接口:
@FunctionalInterface
public interface Callable<V>{
V call() throws Exception;
}
除了Lambda表达式,还可以直接传入方法引用。如:
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
String[] array = new String[] { "Apple", "Orange", "Banana", "Lemon" };
Arrays.sort(array, Main::cmp);
System.out.println(String.join(", ", array));
}
static int cmp(String s1, String s2) {
return s1.compareTo(s2);
}
}
上述代码在Arrays.sort()中直接传入了静态方法cmp的引用,用Main::cmp表示。
因此,所谓方法引用,是指如果某个方法签名和接口恰好一致,就可以直接传入方法引用。
因为Comparator接口定义的方法是int compare(String, String),和静态方法int cmp(String, String)相比,除了方法名外,方法参数一致,返回类型相同,因此,我们说两者的方法签名一致,可以直接把方法名作为Lambda表达式传入:
Arrays.sort(array, Main::cmp);
注意:在这里,方法签名只看参数类型和返回类型,不看方法名称,也不看类的继承关系。
小结
FunctionalInterface允许传入:
接口的实现类(传统写法,代码较繁琐);
Lambda表达式(只需列出参数名,由编译器推断类型);
符合方法签名的静态方法;
符合方法签名的实例方法(实例类型被看做第一个参数类型);
符合方法签名的构造方法(实例类型被看做返回类型)。
FunctionalInterface不强制继承关系,不需要方法名称相同,只要求方法参数(类型和数量)与方法返回类型相同,即认为方法签名相同。
使用Stream
Java从8开始,不但引入了Lambda表达式,还引入了一个全新的流式API:Stream API。它位于java.util.stream包中。
划重点:这个Stream不同于java.io的InputStream和OutputStream,它代表的是任意Java对象的序列。两者对比如下:
| java.io | java.util.stream |
|---|---|
| 存储 顺序读写的byte或char | 顺序输出的任意Java对象实例 |
| 用途 序列化至文件或网络 | 内存计算/业务逻辑 |
有同学会问:一个顺序输出的Java对象序列,不就是一个List容器吗?
**再次划重点:**这个Stream和List也不一样,List存储的每个元素都是已经存储在内存中的某个Java对象,而Stream输出的元素可能并没有预先存储在内存中,而是实时计算出来的。
换句话说,List的用途是操作一组已存在的Java对象,而Stream实现的是惰性计算,两者对比如下:
| java.util.List | java.util.stream |
|---|---|
| 元素 已分配并存储在内存 | 可能未分配,实时计算 |
| 用途 操作一组已存在的Java对象 | 惰性计算 |
Stream<BigInteger> naturals = createNaturalStream(); // 不计算
Stream<BigInteger> s2 = naturals.map(BigInteger::multiply); // 不计算
Stream<BigInteger> s3 = s2.limit(100); // 不计算
s3.forEach(System.out::println); // 计算
设计模式
GoF把23个常用模式分为创建型模式、结构型模式和行为型模式三类。
创建型模式
创建型模式关注点是如何创建对象,其核心思想是要把对象的创建和使用相分离,这样使得两者能相对独立地变换。
创建型模式包括:
- 工厂方法:Factory Method
- 抽象工厂:Abstract Factory
- 建造者:Builder
- 原型:Prototype
- 单例:Singleton
结构型模式
结构型模式主要涉及如何组合各种对象以便获得更好、更灵活的结构。虽然面向对象的继承机制提供了最基本的子类扩展父类的功能,但结构型模式不仅仅简单地使用继承,而且更多地通过组合与运行期的动态组合来实现更灵活的功能。
结构型模式有:
- 适配器
- 桥接
- 组合
- 装饰器
- 外观
- 享元
- 代理
行为型模式
行为型模式主要涉及算法和对象间的职责分配。通过使用对象组合,行为型模式可以描述一组对象应该如何协作来完成一个整体任务。
行为型模式有:
- 责任链
- 命令
- 解释器
- 迭代器
- 中介
- 备忘录
- 观察者
- 状态
- 策略
- 模板方法
- 访问者
Spring
Spring是一个支持快速开发Java EE应用程序的框架。它提供了一系列底层容器和基础设施,并可以和大量常用的开源框架无缝集成,可以说是开发Java EE应用程序的必备。
IoC容器
容器是一种为某种特定组件的运行提供必要支持的一个软件环境。
Spring的核心就是提供了一个IoC容器,它可以管理所有轻量级的JavaBean组件,提供的底层服务包括组件的生命周期管理、配置和组装服务、AOP支持,以及建立在AOP基础上的声明式事务服务等。
IoC原理
IoC全称Inversion of Control,直译为控制反转。即从应用程序转移到了IoC容器,所有组件不再由应用程序自己创建和配置,而是由IoC容器负责,这样,应用程序只需要直接使用已经创建好并且配置好的组件。为了能让组件在IoC容器中被“装配”出来,需要某种“注入”机制,例如,BookService自己并不会创建DataSource,而是等待外部通过setDataSource()方法来注入一个DataSource:
public class BookService {
private DataSource dataSource;
public void setDataSource(DataSource dataSource) {
this.dataSource = dataSource;
}
}
不直接new一个DataSource,而是注入一个DataSource,这个小小的改动虽然简单,却带来了一系列好处:
- BookService不再关心如何创建DataSource,因此,不必编写读取数据库配置之类的代码;
- DataSource实例被注入到BookService,同样也可以注入到UserService,因此,共享一个组件非常简单;
- 测试BookService更容易,因为注入的是DataSource,可以使用内存数据库,而不是真实的MySQL配置。
因此,Ioc又称为依赖注入(DI:Dependency Injection),它解决了一个最主要的问题:将组件的创建+配置与组件的使用相分离,并且,由IoC容器负责管理组件的生命周期。
因为IoC容器要负责实例化所有的组件,因此,有必要告诉容器如何创建组件,以及各组件的依赖关系。一种最简单的配置是通过XML文件来实现,例如:
<beans>
<bean id="dataSource" class="HikariDataSource" />
<bean id="bookService" class="BookService">
<property name="dataSource" ref="dataSource" />
</bean>
<bean id="userService" class="UserService">
<property name="dataSource" ref="dataSource" />
</bean>
</beans>
上述XML配置文件指示IoC容器创建3个JavaBean组件,并把id为dataSource的组件通过属性dataSource(即调用setDataSource()方法)注入到另外两个组件中。
在Spring的IoC容器中,我们把所有组件统称为JavaBean,即配置一个组件就是配置一个Bean。
依赖注入方式
我们从上面的代码可以看到,依赖注入可以通过set()方法实现。但依赖注入也可以通过构造方法实现。
很多Java类都具有带参数的构造方法,如果我们把BookService改造为通过构造方法注入,那么实现代码如下:
public class BookService {
private DataSource dataSource;
public BookService(DataSource dataSource) {
this.dataSource = dataSource;
}
}
Spring的IoC容器同时支持属性注入和构造方法注入,并允许混合使用。
BeanFactory和ApplicationContext的区别在于,BeanFactory的实现是按需创建,即第一次获取Bean时才创建这个Bean,而ApplicationContext会一次性创建所有的Bean。实际上,ApplicationContext接口是从BeanFactory接口继承而来的,并且,ApplicationContext提供了一些额外的功能,包括国际化支持、事件和通知机制等。通常情况下,我们总是使用ApplicationContext,很少会考虑使用BeanFactory。
使用AOP
AOP是Aspect Oriented Programming,即面向切面编程。
它与OOP不同,AOP把系统分解为不同的关注点,或者称之为切面(Aspect)。