1.1 Spark Shuffle 原理
Spark Shuffle 一般用于将上游 Stage 中的数据按 Key 分区,保证来自不同 Mapper (表示上游 Stage 的 Task)的相同的 Key 进入相同的 Reducer (表示下游 Stage 的 Task)。一般用于 group by 或者 Join 操作。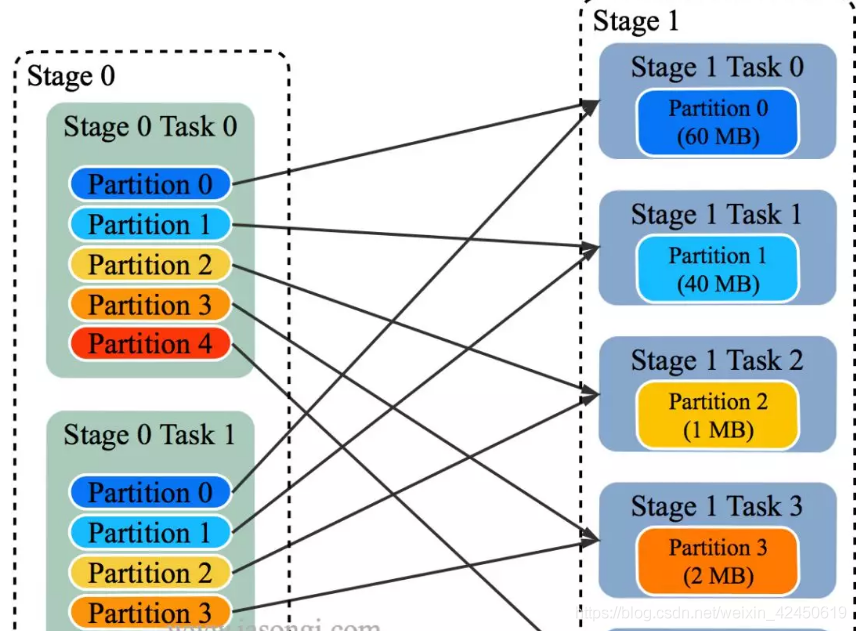
如上图所示,该 Shuffle 总共有 2 个 Mapper 与 5 个 Reducer。每个 Mapper 会按相同的规则(由 Partitioner 定义)将自己的数据分为五份。每个 Reducer 从这两个 Mapper 中拉取属于自己的那一份数据。
1.2 原有 Shuffle 的问题
使用 Spark SQL 时,可通过 spark.sql.shuffle.partitions 指定 Shuffle 时 Partition 个数,也即 Reducer 个数
该参数决定了一个 Spark SQL Job 中包含的所有 Shuffle 的 Partition 个数。如下图所示,当该参数值为 3 时,所有 Shuffle 中 Reducer 个数都为 3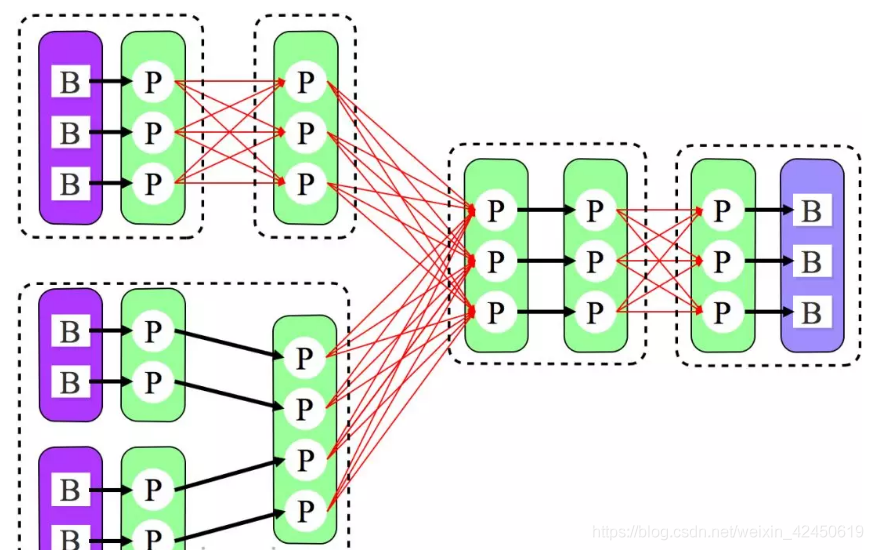
这种方法有如下问题
Partition 个数不宜设置过大
Reducer(代指 Spark Shuffle 过程中执行 Shuffle Read 的 Task) 个数过多,每个 Reducer 处理的数据量过小。大量小 Task 造成不必要的 Task 调度开销与可能的资源调度开销(如果开启了 Dynamic Allocation)
Reducer 个数过大,如果 Reducer 直接写 HDFS 会生成大量小文件,从而造成大量 addBlock RPC,Name node 可能成为瓶颈,并影响其它使用 HDFS 的应用
过多 Reducer 写小文件,会造成后面读取这些小文件时产生大量 getBlock RPC,对 Name node 产生冲击
Partition 个数不宜设置过小
每个 Reducer 处理的数据量太大,Spill 到磁盘开销增大
Reducer GC 时间增长
Reducer 如果写 HDFS,每个 Reducer 写入数据量较大,无法充分发挥并行处理优势
很难保证所有 Shuffle 都最优
不同的 Shuffle 对应的数据量不一样,因此最优的 Partition 个数也不一样。使用统一的 Partition 个数很难保证所有 Shuffle 都最优
定时任务不同时段数据量不一样,相同的 Partition 数设置无法保证所有时间段执行时都最优
1.3 自动设置 Shuffle Partition 原理
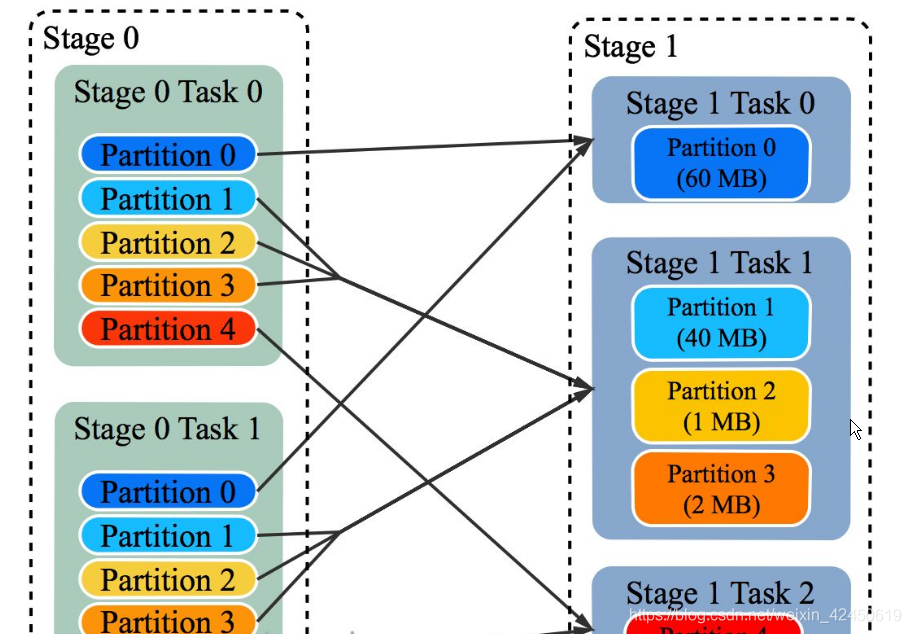
如 Spark Shuffle 原理 一节图中所示,Stage 1 的 5 个 Partition 数据量分别为 60MB,40MB,1MB,2MB,50MB。其中 1MB 与 2MB 的 Partition 明显过小(实际场景中,部分小 Partition 只有几十 KB 及至几十字节)
开启 Adaptive Execution 后
Spark 在 Stage 0 的 Shuffle Write 结束后,根据各 Mapper 输出,统计得到各 Partition 的数据量,即 60MB,40MB,1MB,2MB,50MB
通过 ExchangeCoordinator 计算出合适的 post-shuffle Partition 个数(即 Reducer)个数(本例中 Reducer 个数设置为 3)
启动相应个数的 Reducer 任务
每个 Reducer 读取一个或多个 Shuffle Write Partition 数据(如下图所示,Reducer 0 读取 Partition 0,Reducer 1 读取 Partition 1、2、3,Reducer 2 读取 Partition 4)
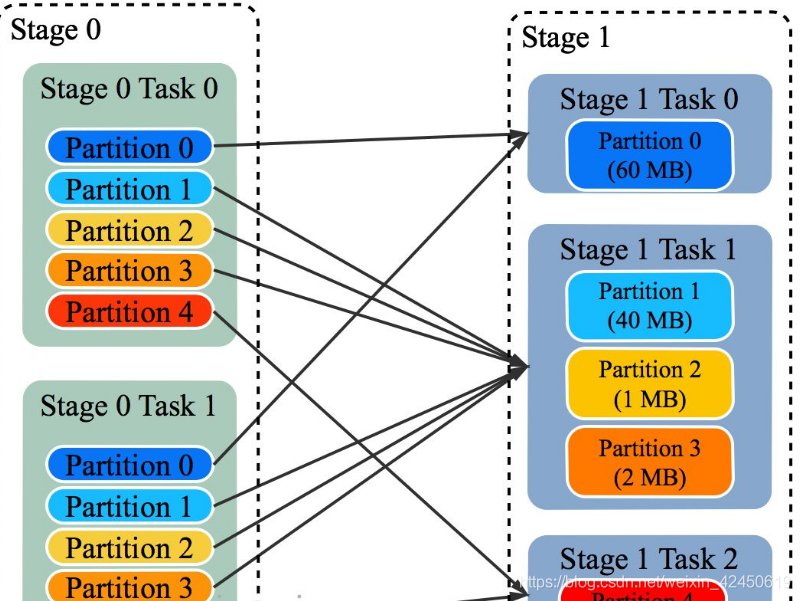
三个 Reducer 这样分配是因为
targetPostShuffleInputSize 默认为 64MB,每个 Reducer 读取数据量不超过 64MB
如果 Partition 0 与 Partition 2 结合,Partition 1 与 Partition 3 结合,虽然也都不超过 64 MB。但读完 Partition 0 再读 Partition 2,对于同一个 Mapper 而言,如果每个 Partition 数据比较少,跳着读多个 Partition 相当于随机读,在 HDD 上性能不高
目前的做法是只结合相临的 Partition,从而保证顺序读,提高磁盘 IO 性能
该方案只会合并多个小的 Partition,不会将大的 Partition 拆分,因为拆分过程需要引入一轮新的 Shuffle
基于上面的原因,默认 Partition 个数(本例中为 5)可以大一点,然后由 ExchangeCoordinator 合并。如果设置的 Partition 个数太小,Adaptive Execution 在此场景下无法发挥作用
由上图可见,Reducer 1 从每个 Mapper 读取 Partition 1、2、3 都有三根线,是因为原来的 Shuffle 设计中,每个 Reducer 每次通过 Fetch 请求从一个特定 Mapper 读数据时,只能读一个 Partition 的数据。也即在上图中,Reducer 1 读取 Mapper 0 的数据,需要 3 轮 Fetch 请求。对于 Mapper 而言,需要读三次磁盘,相当于随机 IO。
为了解决这个问题,Spark 新增接口,一次 Shuffle Read 可以读多个 Partition 的数据。如下图所示,Task 1 通过一轮请求即可同时读取 Task 0 内 Partition 0、1 和 2 的数据,减少了网络请求数量。同时 Mapper 0 一次性读取并返回三个 Partition 的数据,相当于顺序 IO,从而提升了性能。
由于 Adaptive Execution 的自动设置 Reducer 是由 ExchangeCoordinator 根据 Shuffle Write 统计信息决定的,因此即使在同一个 Job 中不同 Shuffle 的 Reducer 个数都可以不一样,从而使得每次 Shuffle 都尽可能最优。
上文 原有 Shuffle 的问题 一节中的例子,在启用 Adaptive Execution 后,三次 Shuffle 的 Reducer 个数从原来的全部为 3 变为 2、4、3。
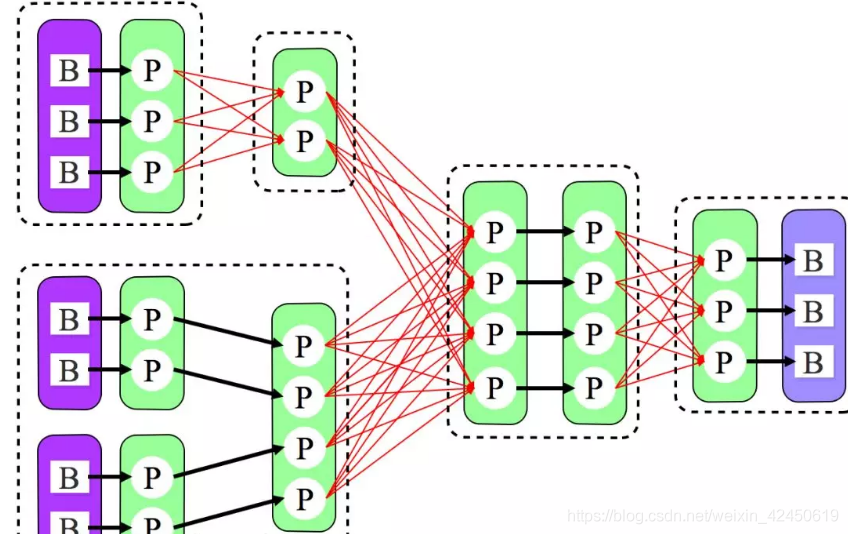
1.4 使用与优化方法
可通过 spark.sql.adaptive.enabled=true 启用 Adaptive Execution 从而启用自动设置 Shuffle Reducer 这一特性
通过 spark.sql.adaptive.shuffle.targetPostShuffleInputSize 可设置每个 Reducer 读取的目标数据量,其单位是字节,默认值为 64 MB。上文例子中,如果将该值设置为 50 MB,最终效果仍然如上文所示,而不会将 Partition 0 的 60MB 拆分。具体原因上文已说明