参考资料:极客时间 【ZooKeeper 实战与源码剖析】等
zxid、myid、epoch
zxid :
表示事务ID, 为了保证事务的顺序一致性,Zookeeper 采用了递增的事务ID号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了 zxid,当提议通过并提交后,会修改 zxid 的后32位进行依次递增。同时也会用来做 Leader 选举时的凭证。
myid :
表示当前 Zookeeper 的一个自身标志,一般用来集群初始化的时候,因为没有提交过事务,所以 zxid 都是 0 ,为了能够选出一个 Leader,这个时候就会选择 myid 最大的节点作为 Leader。
epoch :
表示每个 Leader 任期期间的带代号。每完成一次选举 epoch 就会 +1 ,所以一般来说集群中节点的 epoch 都是一样的,而对于选举之后添加进来的节点, epoch 会不同。
ZAB简介
ZAB 全称 Zookeeper Atomic Broadcast,是特别为 Zookeeper 设计的支持崩溃恢复的原子广播协议。用于 Zookeeper 集群中的 Leader 崩溃时,进行崩溃恢复,以及维持集群各副本数据的一致性。
ZAB协议实现过程
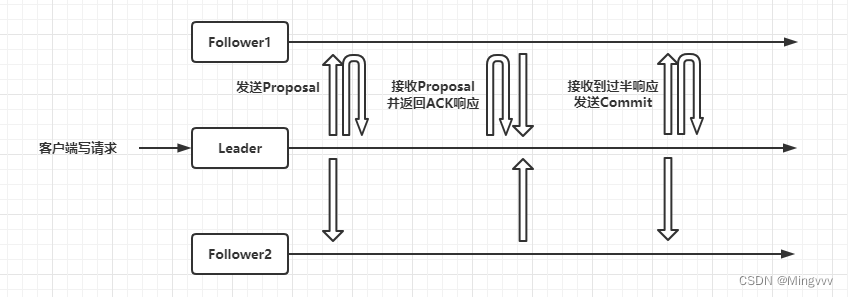
Leader 发送 Proposal 给集群中的所有节点(包括自己)
节点在接收到 Leader 发送的 Proposal 之后,将其落到磁盘上,并发送一个 ACK 给 Leader
在实现过程中的落盘这个步骤,Follower 会向 FollowerZooKeeperServer.pendingTxns 入列 zxid(递增的事务ID号码)
Leader 在接收到大多数节点的 ACK 之后,发送 Commit 给集群中的所有节点
1、Follower 在收到 Leader 的 Commit 请求之后,会从 FollowerZooKeeperServer.pendingTxns 出列 zxid,如果这个出列的 zxid 与 Commit 请求的 zxid 不一致,表明当前 Follower 有漏提交的事务,当前 Follower 就会关闭自己
2、如果 Leader 接收到的 ACK 不到半数,Leader 就会一直处于阻塞状态,后续客户端的写请求都将无法提交。如果长时间不能收到半数以上的ACK,很可能 Leader 已经与半数以上Follower 失去连接,此时集群会进入崩溃恢复模式,重新开始选举,在选举期间整个 Zookeeper 集群不对外提供服务。
3、当事务提交成功后,就表明当前 zxid 是完全可信的,因为第二条可以知道,当前事务提交成功,代表之前的是物业提交成功了,否则提交的时候zxid对应不上,Follower节点就会自动关闭。同时说明集群中存有 zxid 最大的节点在当前集群中的数据是最完成的。
Leader Election 算法
vote(投票信息)
vote 是 Zookeeper 选举过程中的一个重要数据,一个 vote 由 myid 和 zxid 组成。
例如其他节点传递过来的投票信息为 (voteEpoch,voteId,voteZxid),当前节点自身的投票信息为 (myEpoch,myId,MyZxid) ,如果以下条件中有一个成立时,就认为前者比后者的新:
- voteEpoch > myEpoch
- voteEpoch == myEpoch && voteZxid > myZxid
- voteEpoch == myEpoch && voteZxid == myZxid && voteId > myId
这是在短时间内选出 Leader 的重要一步,因为最新的 zxid 保证了选出来的 Leader 中的数据是当前集群中最新的。
算法过程(不考虑选举之后中途添加节点的情况)
- 当集群初始化或者集群中大多数节点连接不上 Leader 时,会触发 Leader 的重新选举。
- 例如 Zookeeper 中的节点一开始向所有节点发送 vote(voteId,voteZxid),voteId 就是 myId,voteZxid 是当前节点上最新的 zxid (事务ID)。
- 其他节点在接收到节点一的 vote 信息之后,会和自身的 vote(myId,myZxid) 做对比,如果节点一的 vote 比自身的新,就更新自身的 vote 信息 ,myId = voteId,myZxid=voteZxid,即表示当前节点支持节点一的投票,并把 vote(voteId,voteZxid) 信息发送给所有的 Zookeeper 节点。否则的话该节点保持沉默,不做任何处理。
顺利选举
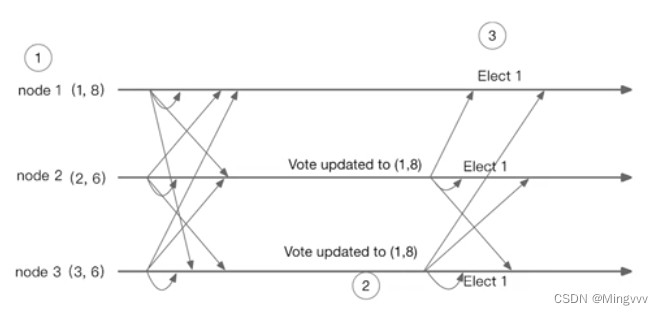
- 在时间点①时大家都开始了投票选举动作,即投出自己。
- 在时间点②时 node2 和 node3 完成了选举过程。因为 node2 和 node3 接收到来自 node1 的投票信息后,发现比自己的新,所以将自己的投票信息修改为**(1,8)**并发送了出去,因为本身已经收到了 node1 的投票,而又接受到自身发送的对 node1 的投票,在三个节点的集群中,满足多数原则,所以 node2 和 node3 确认 node1 为 Leader。
- 在时间节点③ node1 接收到了来自 node2 和 node3 对自身的投票,所以确认自身为 Leader。
选举过程中出现延迟
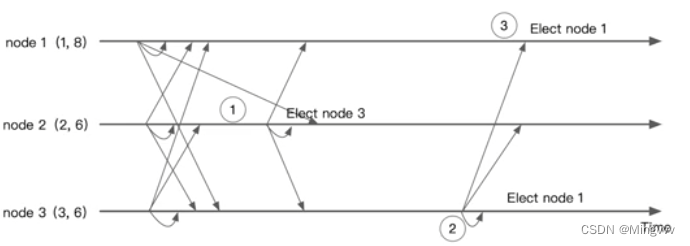
如上,在时间节点①, node2 只接受到了自身的投票和来自 node3 的投票,并未接受到来自 node1 的 vote 信息,所以 node2 理所当然的认为 node3 应该作为 Leader 。此时 node2 可能就会向 node3 发送请求,然而 node3 直到自己不是 Leader 所以对于 node2 的请求将不做响应,node2 将在 timeout 后重试,在 timeout 过程中 node2 是不能提供任何服务的。
针对这种情况, Zookeeper引入了等待时间(finalizeWait )的概念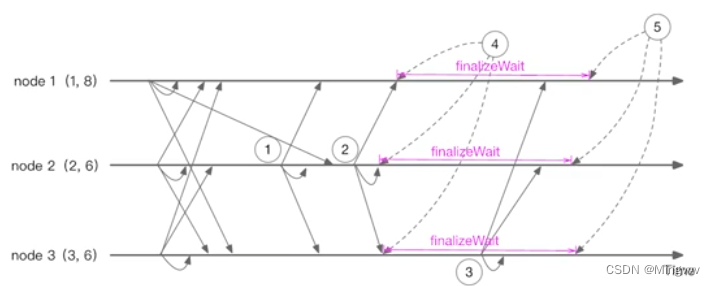
在时间节点① ,node2 只接受到了自身的投票和来自 node3 的投票,但是此时他不会直接选举 node3 为 Leader,而是因为 finalizeWait 机制的原因等待一段时间,当接收到 node1 的 vote 信息时,会重新选择 node1 为 Leader。
但是如果在等待时间之内仍未接受到来自 node1 的 vote ,节点而还是会将 node3 认为是 leader 并向其发送请求,直到 node2 找到新的 Leader。这应该只是 Zookeeper 对于网络延迟的一个简单容错,finalizeWait 的时间长度为 200ms ,因为一般选举过程会在 200ms 内完成。