sparkSQL操作hiveSQL
sparkSQL操作hiveSQL并不是sparkSQL on hive。
- sparkSQL操作hiveSQL底层运行的依然是MR程序
- sparkSQL on hive是把hive当做数据源,spark作为计算引擎。
核心:开启hive依赖
enableHiveSupport()
sparkSQL操作hiveSQL来操作本地文件
此示例,并比要求本地有hive和MySQL,只是单纯的演示sparkSQL如何操作hiveSQL
代码如下
import org.apache.spark.sql.SparkSession
object OPhiveSQL {
def main(args: Array[String]): Unit = {
//1、构建SparkSession对象
val spark: SparkSession = SparkSession.builder()
.appName("HiveSupport")
.master("local[2]")
.enableHiveSupport() //开启对hive的支持
.getOrCreate()
//2、直接使用sparkSession去操作hivesql语句
//2.1 创建一张hive表
spark.sql("create table people(id string,name string,age int) row format delimited fields terminated by ','")
//2.2 加载数据到hive表中
spark.sql("load data local inpath './data/person.txt' into table people ")
//2.3 查询
spark.sql("select * from people").show()
spark.stop()
}
}
本地运行,在没有mySQL和HDFS的情况下,会创建两个文件来分别存储hive表的元数据和真实数据,如下图

输出
sparkSQL操作hiveSQL来操作HDFS上的hive
想通过IDEA操作HDFS上的hive表 需要把hive/conf下的配置文件Hive-site.xml放到本地的resources文件夹中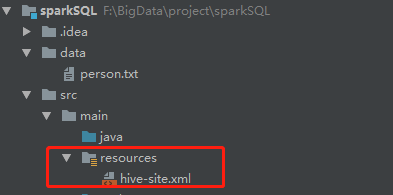
代码
//和上面一样 master("local[2]")只是决定程序在哪运行
import org.apache.spark.sql.SparkSession
object OPhiveSQL {
def main(args: Array[String]): Unit = {
//1、构建SparkSession对象
val spark: SparkSession = SparkSession.builder()
.appName("HiveSupport")
.master("local[2]")
.enableHiveSupport() //开启对hive的支持
.getOrCreate()
//2、直接使用sparkSession去操作hivesql语句
//2.1 创建一张hive表
spark.sql("create table people(id string,name string,age int) row format delimited fields terminated by ','")
//2.2 加载数据到hive表中
spark.sql("load data local inpath './data/person.txt' into table people ")
//2.3 查询
spark.sql("select * from people").show()
spark.stop()
}
执行前HDFS上的hive表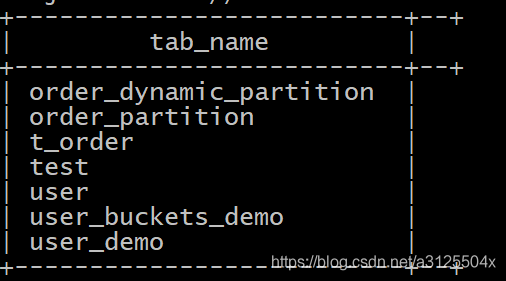
执行后HDFS上的hive表和数据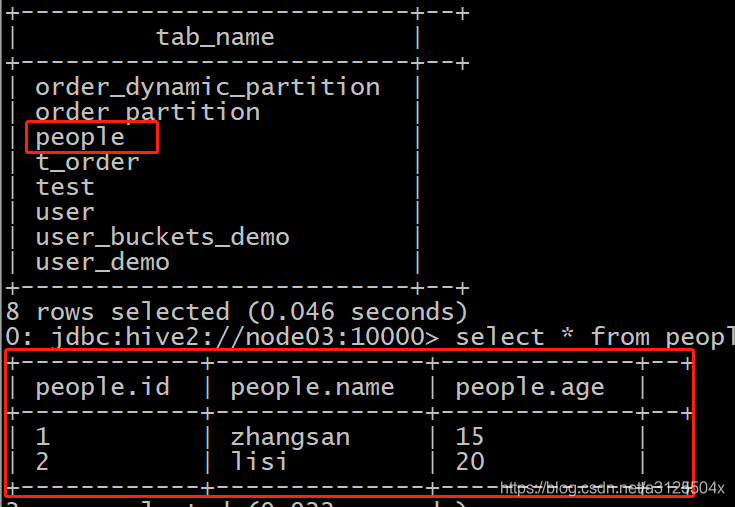
pom依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.3.3</version>
</dependency>
注意,操作HDFS上的hive还需要以下依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
版权声明:本文为a3125504x原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。