【自然语言处理】【知识图谱】知识图谱表示学习(一):TransE、TransH、TransR、CTransR、TransD
【自然语言处理】【知识图谱】知识图谱表示学习(二):TranSparse、PTransE、TransA、KG2E、TransG
【自然语言处理】【知识图谱】知识图谱表示学习(三):SE、SME、LFM、RESCAL、HOLE
【自然语言处理】【知识图谱】知识图谱表示学习(四):【RotatE】基于复数空间关系旋转的知识图谱嵌入
【自然语言处理】【知识图谱】知识图谱表示学习(五):【PairRE】基于成对关系向量的知识图谱嵌入
一、符号
- 使用G = ( E , R , T ) G=(E,R,T)G=(E,R,T)来表示完整的知识图谱,其中E = { e 1 , e 2 , … , e ∣ E ∣ } E=\{e_1,e_2,\dots,e_{|E|}\}E={e1,e2,…,e∣E∣}表示实体集合,R = { r 1 , r 2 , … , r ∣ R ∣ } R=\{r_1,r_2,\dots,r_{|R|}\}R={r1,r2,…,r∣R∣}表示关系集合,T TT表示三元组集合,∣ E ∣ |E|∣E∣和∣ R ∣ |R|∣R∣表示实体和关系的数量。
- 知识图谱以三元组⟨ h , r , t ⟩ \langle h,r,t\rangle⟨h,r,t⟩的形式表示,其中h ∈ E h\in Eh∈E表示头实体,t ∈ E t\in Et∈E表示尾实体,r ∈ R r\in Rr∈R表示h hh和t tt间的关系。
二、SE
SE(Structured Embedding) \text{SE(Structured Embedding)}SE(Structured Embedding)会将每个实体投影至d dd维向量空间。具体来说,SE \text{SE}SE会为每个关系设计两个矩阵M r , 1 , M r , 2 ∈ R d × d \textbf{M}_{r,1},\textbf{M}_{r,2}\in\mathbb{R}^{d\times d}Mr,1,Mr,2∈Rd×d,然后使用者两个矩阵将头实体和尾实体投影至相同的语义空间并计算相似度。SE \text{SE}SE的评分函数定义为
E ( h , r , t ) = ∥ M r , 1 h − M r , 2 t ∥ 1 \mathcal{E}(h,r,t)=\parallel \textbf{M}_{r,1}\textbf{h}-\textbf{M}_{r,2}\textbf{t}\parallel_1E(h,r,t)=∥Mr,1h−Mr,2t∥1
其中,h \textbf{h}h和t \textbf{t}t都会被投影至相应的关系空间中。
不同于TransE \text{TransE}TransE这样基于翻译的模型,SE \text{SE}SE会将实体建模为嵌入向量,关系建模为投影矩阵。
三、SME
不同于SE \text{SE}SE,SEM(Semantic Matching Energy) \text{SEM(Semantic Matching Energy)}SEM(Semantic Matching Energy)会将实体和关系都看作是低维向量。对于任一三元组⟨ h , r , t ⟩ \langle h,r,t\rangle⟨h,r,t⟩,h \textbf{h}h和r \textbf{r}r会被一个投影函数g gg合并为新嵌入向量I h , r \textbf{I}_{h,r}Ih,r,t \textbf{t}t和r \textbf{r}r也同样会被合并I t , r \textbf{I}_{t,r}It,r。然后,通过一个point-wise乘积将两个嵌入向量I h , r \textbf{I}_{h,r}Ih,r和I t , r \textbf{I}_{t,r}It,r进行合并,得到整个三元组的评分。SME \textbf{SME}SME提出了两个不同的合并投影函数g gg:
线性形式
E ( h , r , t ) = ( M 1 h + M 2 r + b 1 ) ⊤ ( M 3 t + M 4 r + b 2 ) \mathcal{E}(h,r,t)=(\textbf{M}_1\textbf{h}+\textbf{M}_2\textbf{r}+\textbf{b}_1)^\top(\textbf{M}_3\textbf{t}+\textbf{M}_4\textbf{r}+\textbf{b}_2)E(h,r,t)=(M1h+M2r+b1)⊤(M3t+M4r+b2)
其中,M 1 h + M 2 r + b 1 \textbf{M}_1\textbf{h}+\textbf{M}_2\textbf{r}+\textbf{b}_1M1h+M2r+b1就是I h , r \textbf{I}_{h,r}Ih,r,M 3 t + M 4 r + b 2 \textbf{M}_3\textbf{t}+\textbf{M}_4\textbf{r}+\textbf{b}_2M3t+M4r+b2是I t , r \textbf{I}_{t,r}It,r。双线性形式
E ( h , r , t ) = ( ( M 1 h ⊙ M 2 r ) + b 1 ) ⊤ ( ( M 3 t ⊙ M 4 r ) + b 2 ) \mathcal{E}(h,r,t)=((\textbf{M}_1\textbf{h}\odot\textbf{M}_2\textbf{r})+\textbf{b}_1)^\top((\textbf{M}_3\textbf{t}\odot\textbf{M}_4\textbf{r})+\textbf{b}_2)E(h,r,t)=((M1h⊙M2r)+b1)⊤((M3t⊙M4r)+b2)
其中,( M 1 h ⊙ M 2 r ) + b 1 (\textbf{M}_1\textbf{h}\odot\textbf{M}_2\textbf{r})+\textbf{b}_1(M1h⊙M2r)+b1是I h , r \textbf{I}_{h,r}Ih,r,( M 3 t ⊙ M 4 r ) + b 2 (\textbf{M}_3\textbf{t}\odot\textbf{M}_4\textbf{r})+\textbf{b}_2(M3t⊙M4r)+b2是I t , r \textbf{I}_{t,r}It,r。
其中,⊙ \odot⊙是element-wise(Hadamard)积;M 1 , M 2 , M 3 , M 4 \textbf{M}_1,\textbf{M}_2,\textbf{M}_3,\textbf{M}_4M1,M2,M3,M4是投影函数的权重矩阵,b 1 , b 2 \textbf{b}_1,\textbf{b}_2b1,b2是偏置。
四、LFM
LFM(Latent Factor Model) \text{LFM(Latent Factor Model)}LFM(Latent Factor Model)是用于建模大型多关系数据集的。LFM \textbf{LFM}LFM是双线性结构,其将实体建模为嵌入向量、关系建模为矩阵。该方法在不同关系间共享相同的隐因子,从而极大的降低计算复杂度。LFM \text{LFM}LFM的评分函数为
E ( h , r , t ) = h ⊤ M r t \mathcal{E}(h,r,t)=\textbf{h}^\top\textbf{M}_r\textbf{t}E(h,r,t)=h⊤Mrt
其中,M r \textbf{M}_rMr是关系r rr的矩阵表示。
五、RESCAL
RESCAL \text{RESCAL}RESCAL是一种基于矩阵分解的知识图谱表示学习。RESCAL \text{RESCAL}RESCAL为了表示知识图谱中的所有三元组,提出了三维张量的方式X ⃗ ∈ R d × d × k \vec{\textbf{X}}\in\mathbb{R}^{d\times d\times k}X∈Rd×d×k,其中d dd是实体的维度,k kk是关系的维度。在三维张量X ⃗ \vec{\textbf{X}}X中,前两个mode分别表示头、尾实体,第三个mode表示关系。X ⃗ \vec{\textbf{X}}X中的每个分量都代表对应的三元组是否存在。例如,若三元组⟨ i t h e n t i t y , m t h r e l a t i o n , j t h e n t i t y ⟩ \langle ith \;entity,mth\;relation,jth\;entity\rangle⟨ithentity,mthrelation,jthentity⟩在训练集中存在则X ⃗ i j m = 1 \vec{\textbf{X}}_{ijm}=1Xijm=1,否则X ⃗ i j m = 0 \vec{\textbf{X}}_{ijm}=0Xijm=0。
为了捕获所有三元组的内在结构,提出一个称为RESCAL \text{RESCAL}RESCAL的张量分量模型。设X ⃗ = { X 1 , … , X k } \vec{\textbf{X}}=\{\textbf{X}_1,\dots,\textbf{X}_k\}X={X1,…,Xk},那么对于每个slice X n \textbf{X}_nXn,其r rr秩分解为
X n ≈ AR n A ⊤ \textbf{X}_n\approx\textbf{AR}_n\textbf{A}^\topXn≈ARnA⊤
其中,A ∈ R d × r \textbf{A}\in\mathbb{R}^{d\times r}A∈Rd×r是r rr维的实体表示,R n \textbf{R}_nRn则是第n nn个关系r rr个隐组件的交互。该分解的形式与LFM \text{LFM}LFM非常类似,但是RESCAL \text{RESCAL}RESCAL不但能优化正三元组,也能同时优化不存在的三元组,即X ⃗ i j m = 0 \vec{\textbf{X}}_{ijm}=0Xijm=0。
基于这个张量分量的假设,RESCAL \text{RESCAL}RESCAL的损失函数定义为
L = 1 2 ( ∑ n ∥ X n − AR n A ⊤ ∥ F ) + 1 2 λ ( ∥ A ∥ F 2 + ∑ n ∥ R n ∥ F 2 ) \mathcal{L}=\frac{1}{2}\Big(\sum_n\parallel\textbf{X}_n-\textbf{AR}_n\textbf{A}^\top\parallel_F\Big)+\frac{1}{2}\lambda\Big(\parallel\textbf{A}\parallel_F^2+\sum_n\parallel\textbf{R}_n\parallel_F^2\Big)L=21(n∑∥Xn−ARnA⊤∥F)+21λ(∥A∥F2+n∑∥Rn∥F2)
其中,第2项是正则化项,λ \lambdaλ是超参数
六、HOLE
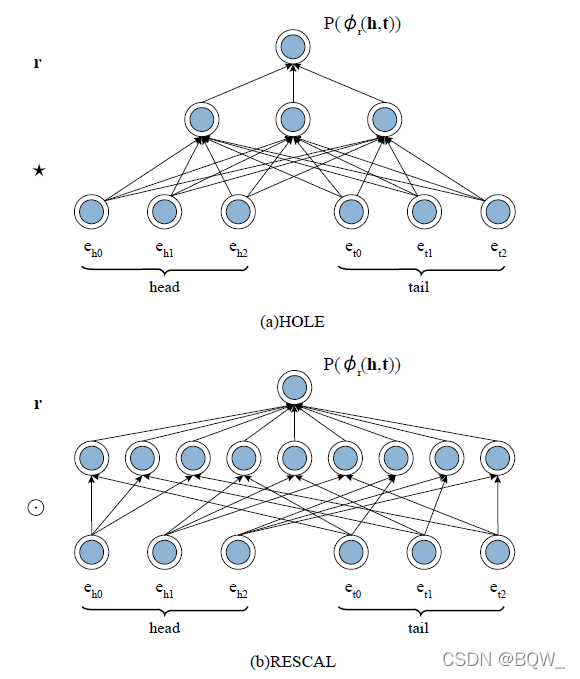
RESCAL \text{RESCAL}RESCAL虽然在多关系数据集上表现的很好,但是计算复杂度太高。为了提高RESCAL \text{RESCAL}RESCAL的效率,提出了其增强版本HOLE(Holographic Embeddings) \text{HOLE(Holographic Embeddings)}HOLE(Holographic Embeddings)。
HOLE \text{HOLE}HOLE利用了一种称为“循环关联”(circular correlation)的操作来生成组合表示,其类似于联合存储中的holographic模型。循环关联操作★ : R d × R d → R d \bigstar:\mathbb{R}^d\times\mathbb{R}^d\rightarrow\mathbb{R}^d★:Rd×Rd→Rd介于实体h hh和t tt之间
h ★ t k = ∑ i = 0 d − 1 h i t ( k + i ) m o d d \textbf{h}\bigstar\textbf{t}_k=\sum_{i=0}^{d-1}h_it_{(k+i)mod\;d}h★tk=i=0∑d−1hit(k+i)modd
上图展示了这个操作的简单例子。
三元组⟨ h , r , t ⟩ \langle h,r,t\rangle⟨h,r,t⟩的概率定义为
P ( ϕ r ( h , t ) = 1 ) = Sigmoid ( r ⊤ ( h ★ t ) ) P(\phi_r(h,t)=1)=\text{Sigmoid}(\textbf{r}^\top(\textbf{h}\bigstar\textbf{t}))P(ϕr(h,t)=1)=Sigmoid(r⊤(h★t))
“循环关联”操作能够带来许多优点:(1) 不同于乘或者卷积的操作,循环关联是不具有交换性的(例如h ★ t ≠ t ★ h \textbf{h}\bigstar\textbf{t}\neq\textbf{t}\bigstar\textbf{h}h★t=t★h),其能够建模知识图谱中的非对称关系;(2) 循环关联的计算复杂度低。此外,“循环关联“操作还能够利用快速傅里叶变换进行进一步的加速。
引用文献
[1]. Zhiyuan Liu, Yankai Lin and Maosong SUn. Representation Learning for Natural Language Processing.