目录
目标网站: Scrape | Movie
目标信息:获取所有电影的信息
1.效果图:
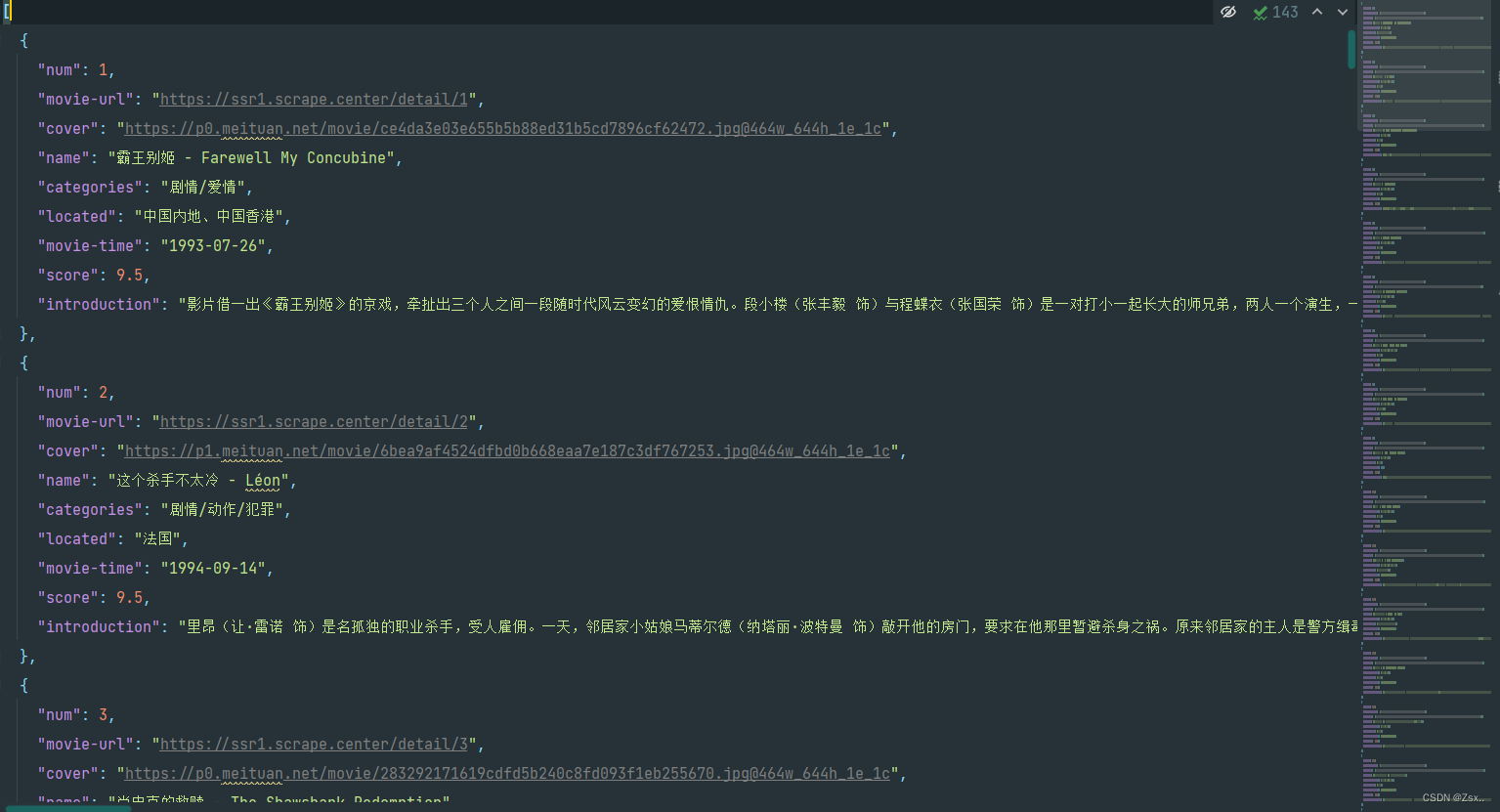
2.baseInfo.py
将基础的用法写入baseInfo中,方便随时调用
# -*- coding:utf-8 -*-
# @Author:Zsx..
# @Date:2022/11/20 17:28
# @Function:
import logging
import random
import requests
user_agent_list = [
'Mozilla/5.0(compatible;MSIE9.0;WindowsNT6.1;Trident/5.0)',
'Mozilla/4.0(compatible;MSIE8.0;WindowsNT6.0;Trident/4.0)',
'Mozilla/4.0(compatible;MSIE7.0;WindowsNT6.0)',
'Opera/9.80(WindowsNT6.1;U;en)Presto/2.8.131Version/11.11',
'Mozilla/5.0(WindowsNT6.1;rv:2.0.1)Gecko/20100101Firefox/4.0.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.4.3.4000 Chrome/30.0.1599.101 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'
]
headers = {
"User-Agent": random.choice(user_agent_list),
"Connection": "close"
}
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s : %(message)s')
def spiderPage(url):
logging.info("scraping %s...", url)
try:
response = requests.get(url, headers=headers, timeout=15)
if response.status_code == 200:
return response.text
logging.error("get invalid statue code %s while scraping %s", response.status_code, url)
except requests.RequestException as e:
logging.error("error occurred while scraping %s", url, exc_info=True)
3.demo1.py
# -*- coding:utf-8 -*-
# @Author:Zsx
# @Date:2022/11/20 17:07
# @Function:
import json
import logging
import queue
import re
import threading
from urllib.parse import urljoin
import baseInfo
# 设置日志的基本输出格式
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s : %(message)s')
BASE_URL = "https://ssr1.scrape.center/"
PAGE_URLS = []
ITEMS_URLS = []
ITEMS = []
# 获取总页面数和url
def getTotalPage():
response = baseInfo.spiderPage(BASE_URL)
pattern = re.compile(r'<li\sclass="number.*?">.*?<a\shref="(.*?)">.*?</li>', re.S | re.M)
result = re.findall(pattern, response)
return result
# 获取所有电影的url
def getTotalItemsUrls(url):
response = baseInfo.spiderPage(url)
pattern = re.compile(r'<a\sdata-v-7f856186=""\shref="(.*?)"\s.*?>', re.S | re.M)
result = re.findall(pattern, response)
ITEMS_URLS.extend(result)
# 获取每部电影的信息
def getItemDetailedMessage(url):
response = baseInfo.spiderPage(url)
item_num = int(url.rsplit("/", 1)[1])
item_image_pattern = re.compile(r'<img\s+data-v-63864230="".*?src="(.*?)".*?class="cover">', re.S | re.M)
item_image = re.search(item_image_pattern, response).group(1)
item_name_pattern = re.compile(r'<h2 data-v-63864230="" class="m-b-sm">(.*?)</h2>')
item_name = re.search(item_name_pattern, response).group(1)
item_categories_pattern = re.compile(r'<button data-v-7f856186="" type="button".*?<span>(.*?)</span>',
re.S | re.M)
item_categories = "/".join(re.findall(item_categories_pattern, response))
item_located_pattern = re.compile(r'<div data-v-7f856186="" class="m-v-sm info">.*?<span.*?>(.*?)</span>',
re.S | re.M)
item_located = re.search(item_located_pattern, response).group(1)
item_movie_time_pattern = re.compile(r'<span data-v-7f856186="">(\d{4}-\d{2}-\d{2}).*?</span>')
item_movie_time = re.search(item_movie_time_pattern, response).group(1) if re.search(item_movie_time_pattern,
response) else []
item_score_pattern = re.compile(r'el-col-sm-4"><p.*?>\s+(.*?)</p>', re.S | re.M)
item_score = float(re.search(item_score_pattern, response).group(1))
item_introduction_pattern = re.compile(r'剧情简介</h3>.*?>\s+(.*?)\s+</p>', re.S | re.M)
item_introduction = re.search(item_introduction_pattern, response).group(1)
item = {
"num": item_num,
"movie-url": url,
"cover": item_image,
"name": item_name,
"categories": item_categories,
"located": item_located,
"movie-time": item_movie_time,
"score": item_score,
"introduction": item_introduction
}
return item
# 保存所有电影的信息
def saveItemsMessage():
while not q.empty():
result = getItemDetailedMessage(q.get())
ITEMS.append(result)
if __name__ == '__main__':
page_end_urls = getTotalPage()
# 拼接url
for end_url in page_end_urls:
PAGE_URLS.append(urljoin(BASE_URL, end_url))
logging.info("已获取所有页面网址")
logging.info("开启线程抓取所有电影网址")
threadLists = []
for page_url in PAGE_URLS:
t = threading.Thread(target=getTotalItemsUrls, args=(page_url,))
threadLists.append(t)
t.start()
logging.info("检查线程是否全部运行完毕")
for t in threadLists:
t.join()
threadLists.clear()
logging.info("已抓取所有电影网址")
print(ITEMS_URLS)
logging.info("开启线程抓取所有电影信息")
q = queue.Queue()
for _url in ITEMS_URLS:
q.put(urljoin(BASE_URL, _url))
for i in range(1, 20):
t = threading.Thread(target=saveItemsMessage)
threadLists.append(t)
t.start()
logging.info("检查线程是否全部运行完毕")
for t in threadLists:
t.join()
threadLists.clear()
logging.info("已抓取所有电影信息")
ITEMS.sort(key=lambda x: x["num"])
with open("demo1.json", "a+", encoding="utf-8") as file:
file.write(json.dumps(ITEMS, indent=2, ensure_ascii=False))
print("spider finished")
4.python中正则常用
(1)re.match函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match() 就 返回 none。
(2)re.search方法
re.search 扫描整个字符串并返回第一个成功的匹配。
(3)re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
(4)re.compile 函数
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
(5)findall
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
注意: match 和 search 是匹配一次 findall 匹配所有。
5.python中正则的flags
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
版权声明:本文为m0_59501411原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。