Druid
是一个高性能的实时分析型数据库
核心设计结合了数据仓库,时间序列数据库和搜索系统的思想
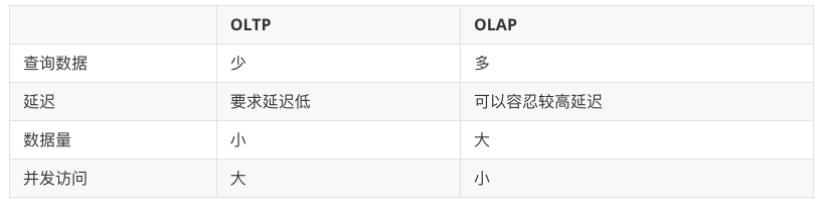
OLAP 和 OLTP
OLAP 的全称是 On-Line Analytical Processing
OLTP 的全称是 On-Line Transaction Processing
OLTP 对应常见的关系型数据库
· MySQL
· 实时 OLAP 和离线 OLAP
· Hive + Hadoop,SparkSQL + HDFS,Kylin 等就是离线 OLAP
· 监控告警系统这种对实时性要求比较高的系统就是实时 OLAP
· Druid 就属于实时 OLAP
Druid 的核心特性
· 列式存储。列式存储的优势在于查询的时候可以只返回指定的列的数据,其次同一列数据往往具有很多共性,这带来另一个好处就是存储的时候压缩效果比较好。
· 可扩展的分布式架构
· 并行计算
· 数据摄入支持实时和批量。这里的实时的意思是输入摄入即可查
· 运维友好
· 云原生架构,高容错性
· 支持索引,便于快速查询。
· 基于时间的分区
· 自动聚合
OLAP 系统的共同特性
· 实时摄取可查询。换句话说就是数据查询无延迟,这个在一些对实时性要求比较高的场景下,比如监控告警,还是很重要的。
· 自动实时聚合。
· 高效的索引结构便于查询。
开源技术的补充
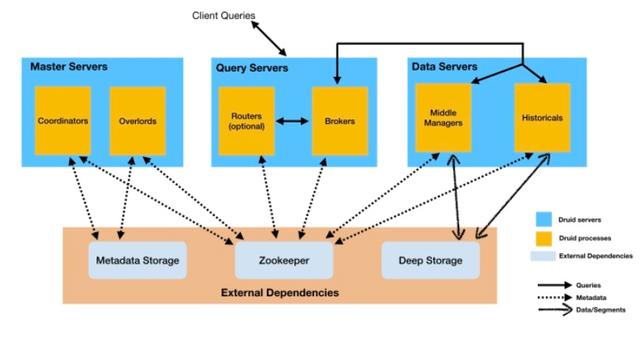
Druid 的架构
6 个不同的组件
· 流程图说明
· 实时查询:
· MiddleManager
· 这里 MiddleManager 主要负责查询正在进行摄入的数据查询,MiddleManager 再将请求分发到具体的 peon,也就是 task 的运行实体上
· 离线查询
· Historical
· 历史数据的查询是通过 Historical 查询的,然后数据返回到 Broker 进行汇总。这里需要注意的时候数据查询并不会落到 Deep Storage 上去,也就是查询的数据一定是 cache 到本地磁盘的
· Queries: Routers 将请求路由到 Broker,Broker 向 MiddleManager 和 Historical 进行数据查询
· Data/Segment:得两个功能说明---实时到离线得过程
· MiddleManager 的 task 在结束的时候会将数据写入到 Deep Storage,这个过程一般称作 Segment Handoff
· 然后 Historical 定期的去下载 Deep Storage 中的 segment 数据到本地。
· Metadata
· Druid 的元数据主要存储到两个部分
· 一个是 Metadata Storage,这个一般是 MySQL 等关系型数据库
· 另一个是 Zookeeper。下图是 Druid 在 Zookeeper 中的 znode。zk 的作用主要是用来给各个组件进行解耦。
·
·
· Coordinator
· Coordinator 就是协调器
· 主要负责 segment 的分发等
· 只保存 30 天的数据,这个规则就是由 Coordinator 来定时执行的。
· Overlord
· 处理数据摄入的 task,将 task 提交到 MiddleManager
· 使用 Tranquility 做数据摄入的时候,每个 segment 都会生成一个对应的 task
· Broker
· 处理外部请求,并对结果进行汇总
· Router
· 相当于多个 Broker 前面的路由,不是必须的。
· Historical
· Historical 可以理解为将 segment 存储到本地,相当于 cache。
· 相比于 Deep Storage 的,Historical 将 segment 直接存储到本地磁盘,只有 segment 存储到本地才能被查询。其实这个地方是有点异于直观感受的。正常我们可能会认为查询先查本地,如果本地没有数据才去查 Deep Storage,但是实际上如果本地没有相应的 segment,则查询是无法查询的。 Historical 处理那些 segment 是由 Coordinator 指定的,但是 Historical 并不会和 Coordinator 直接交互,而是通过 Zookeeper 来解耦。
· MiddleManager
· MiddleManager 可以认为是一个任务调度进程,主要用来处理 Overload 提交过来的 task。每个 task 会以一个 JVM 进程启动。
数据存储
· Druid 的数据存储单位是 segment
· segment 按时间粒度(可以通过参数 segmentGranularity 指定)划分
· 存储到
· Deep Storage
· Historical
· segment可以是有多个备份的,实现并行查询,不是为了高可用
· 高可用是通过Deep Storage保证
·
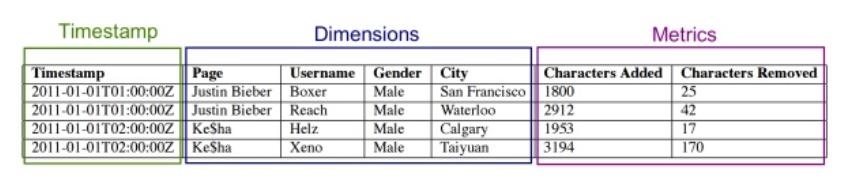
·
· 比如上面图中的 Page 维度:Justin Bieber 被编码成 0,Ke$ha 被编码成 1。对于 Username 维度:Boxer -> 0,Reach -> 1,Helz -> 0,Xeno -> 1。
· 然后 Page 这列数据就会被存储为 [0,0,1,1]。
· 最后是位图,用来表示对于某个维度的某个值,有哪些列包含了这个值,比如:
· Justin Bieber: [1,1,0,0]
· Boxer: [1,0,0,0]
· 那么 filter 查询 Page='Justin Bieber' and Username='Boxer',直接将 1100 和 1000 做位运算 and 即可。group 也是类似。
· 也是一种倒排,常规的倒排后面的 list 中直接包含的是 Document ID,这里直接表示成位图,其实是异曲同工。
· 三个部分
· Timestamp:时间戳信息
· Dimension:维度信息
· Metrics: 一般是数值型
· Druid 会自动对数据进行 Rollup,也就是聚合。如果时间粒度是一小时,那么在这一个小时内维度相同的数据会被合并为一条,Timestamp 都变成整点,metrics 会根据聚合函数进行聚合,比如 sum, max, min 等,注意是没有平均 avg 的。Timestamp 和 Metrics 直接压缩存储即可
· Druid 的一大亮点就是支持多维度实时聚合查询,简单来说就是 filter 和 group。而实现这个特性的关键技术主要两点:bitmap + 倒排。
· Druid 会将维度值编码映射成数字 ID,类似数据仓库中的维度表,主要是为了存储节省空间
数据摄入
Druid 的数据摄入
· 实时流模式
· 批模式
· 就是典型的 Lambda 架构
· 通过实时处理保证实时性
· 过批处理保证数据完整性和准确性
· druid 中的数据摄入官方支持了多种方式
·
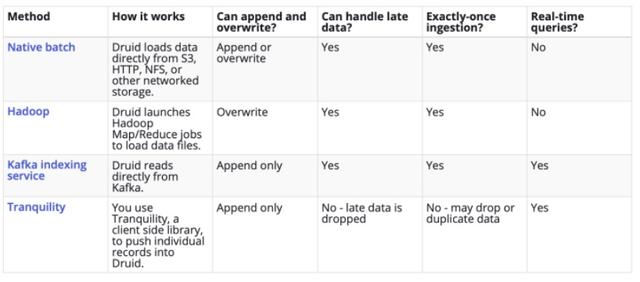
·
· Can handle late data
· Druid 的底层存储使用了 segment 结构
· 时间粒度是 1 个小时,那么 12:00 ~ 13:00 的数据就会存储到一个 segment 里面
· 就是这个 segment 的数据什么时候 ready
· 在流处理中一种常规的做法是 watermark,简单来说就设置一个可以接受的时间延迟,比如 5 分钟,那么 12:00 ~ 13:00 会一直接受数据直到 13:05
· 然后之后这个 segment 就会被 handoff 掉
· 这个过程就叫做 "handle late data"
· Native batch 和 Hadoop 都对应了 Lambda 架构中的批处理
· Tranquility 则对应了 Lambda 架构中实时处理,是一种 push 的方式
· Kafka Indexing Service,这种方式通过 pull 的方式来摄取数据
· 这一种服务其实就可以完成数据摄取并满足所有需求
· Kafka Indexing Service 的最大问题就是和 Kafka 强耦合。
查询
Druid 最开始的时候是不支持 SQL 查询的,原生查询是通过查询 Broker 提供的 http server 来实现的
curl -X POST ':/druid/v2/?pretty' -H 'Content-Type:application/json' -H 'Accept:application/json' -d @
json 查询
{ "queryType": "timeseries", "dataSource": "sample_datasource", "intervals": [ "2012-01-01T00:00:00.000/2012-01-03T00:00:00.000" ], "granularity": "day", "aggregations": [ { "type": "longSum", "name": "sample_name1", "fieldName": "sample_fieldName1" }, { "type": "doubleSum", "name": "sample_name2", "fieldName": "sample_fieldName2" } ], "context": { "grandTotal": true } }
查询类型
· 聚合查询(Aggregation Queries)
· : 可以简单理解为性能更好的 select。
· : TopN 相当于 GroupBy 加 Ordering,相同的查询我们正常也可以通过 GroupBy 查询来实现,但是 TopN 的性能更好。TopN 的底层实现也是比较直观的,将并行查询的每个查询的结果的 TopK 结果返回给 Broker,由 Broker 进行聚合汇总。注意这里返回的结果是 K 条记录,而不是 N 条记录,K 默认值为 max(1000, threshold) 决定(threshold 由用户指定,就相当于 TopN 中的 N)。
· : GroupBy
· 元数据查询(Metadata Queries)
· Druid 的元数据一般是存储到 MySQL 中,包含一些 dataSource,segment 的元信息
·
·
· 元数据查询
· : 用来查询查询指定模式的数据第一次出现和最近一次出现的时间。
· :返回 segment 的元信息,包括维度信息等
· :返回 dataSource 的元信息。
· 搜索查询(Search Queries)
· Search
· 范围查询 (Scan):scan 的结果是以流模式返回的,也就是 client 真正读取的时候才会占用内存。
· Select: 官方已经不建议使用 Select 查询。这里就不在介绍了。
· Druid 的底层存储由于是使用时间来做分片的,所以查询的时候一定需要带上时间区间
· Druid 的 Rollup 不支持 average,也就是平均值,那么如果我查询的时候要查询平均值应该怎么做呢?
· postaggregate,druid 在查询的时候可以定义聚合操作,是查询的时候直接计算的。同时 druid 还提供了针对聚合后的值的聚合操作,叫做 postaggregate
· 作者:尼不要逗了 链接:https://zhuanlan.zhihu.com/p/79719233 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 { "queryType": "timeseries", "dataSource": "sample_datasource", "granularity": "day", "descending": "true", "filter": { "type": "and", "fields": [ { "type": "selector", "dimension": "sample_dimension1", "value": "sample_value1" }, { "type": "or", "fields": [ { "type": "selector", "dimension": "sample_dimension2", "value": "sample_value2" }, { "type": "selector", "dimension": "sample_dimension3", "value": "sample_value3" } ] } ] }, "aggregations": [ { "type": "longSum", "name": "sample_name1", "fieldName": "sample_fieldName1" }, { "type": "doubleSum", "name": "sample_name2", "fieldName": "sample_fieldName2" } ], "postAggregations": [ { "type": "arithmetic", "name": "sample_divide", "fn": "/", "fields": [ { "type": "fieldAccess", "name": "postAgg__sample_name1", "fieldName": "sample_name1" }, { "type": "fieldAccess", "name": "postAgg__sample_name2", "fieldName": "sample_name2" } ] } ], "intervals": [ "2012-01-01T00:00:00.000/2012-01-03T00:00:00.000" ] }
· Druid SQL 值得一提的是提供了非常多的 function,包括数值计算,字符串操作,时间操作等
· 其中一个字符串操作函数叫做 REGEXP_EXTRACT(expr, pattern, [index]) 对 expr 做正则匹配,并提取特定的字段。使用这个函数可以做非常多的事情。但是 function 有的时候对于 SQL 的执行计划优化并不是非常友好,不知道这里 Druid 团队是如何权衡的。
· 明细查询
· 由于 Druid 会对存储的数据做 Rollup,正常情况下是不能存储明细的。但是如果是你一定需要明细的话,有个办法就是将所有所有的列,包括 metric,都设置成 dimension,同时将聚合粒度设置到可以接受的粒度,比如秒。
· 高基数
· 这里的高基数指的是 Druid 的 Dimension 的值可能会有非常多的值,这样引入一个问题就是存储的时候会消耗比较大的空间,同时对于 CPU 的占用也会有一定程度的影响。