爬取结果
mongodb数据库: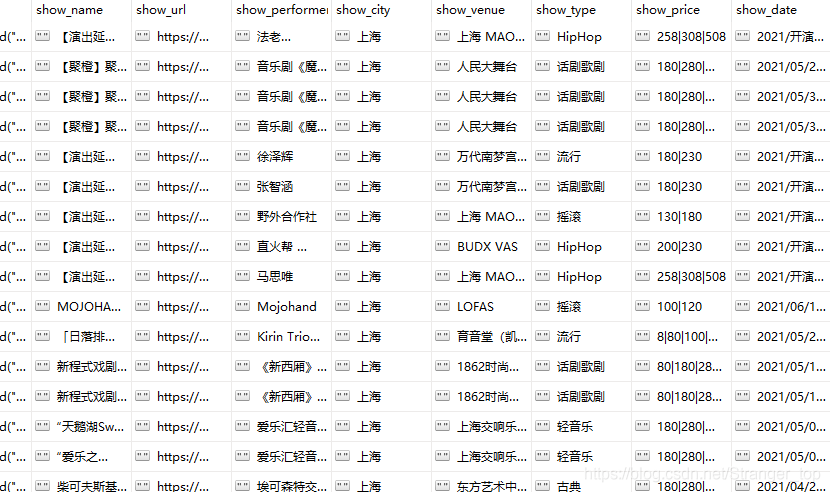
spider文件
分析秀动网站页面的布局,准备爬取我们需要的信息。
没有粘贴代码,简单讲解一下爬取上海所有的演出信息。
parse方法里面定义
页面演出信息的列表:
datas = response.xpath("/html/body/div[4]/ul/li")
循环遍历这个列表,可以取到我们需要的剧目名称和详情页的url
item['show_name'] = data.xpath('a/@title').extract()[0]
url = data.xpath('a/@href').extract()[0]
然后采用回调函数指向下一个函数,主要对详情页处理
meta参数传递字典
yield scrapy.Request(url, callback=self.parse_details, meta=({'item': item}))
parse_details方法
拿到上个函数传递的字典
item = response.meta['item']
接着就是写xpath提取页面的数据…
这里就不一一说了,就说一下价格的简单清洗。
网页上面的价格:
我需要存储为:180|260|380这样的格式,在按照升序排列。
直接上代码:
# //li/span/text() 表示提取全部li标签下面span标签下的文本信息
price = response.xpath('//*[@id="shoppingForm"]/ul//li/span/text()').extract() # extract()方法返回的是一个列表
price = sorted(price, key=int) # 将列表按照升序排列
price = "|".join(price) # 将列表数据提取出来组成字符串并按照|分隔开
item['show_price'] = price
存入MongoDB:
def open_spider(self, spider):
self.db = MongoClient('localhost', 27017).showstart_db
self.collection = self.db.showstart_collection
def process_item(self, item, spider):
self.collection.insert_one(dict(item))
def close_spider(self, spider):
self.collection.close()
版权声明:本文为Stranger_top原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。