爬虫思路:
在网站首页通过开发者选项选中视频详情页的链接,进入后需要再次进行网页解析并获取视频链接,将最终的视频链接网页进行二进制转码,下载到本地进行永久化保存
遇到的问题:
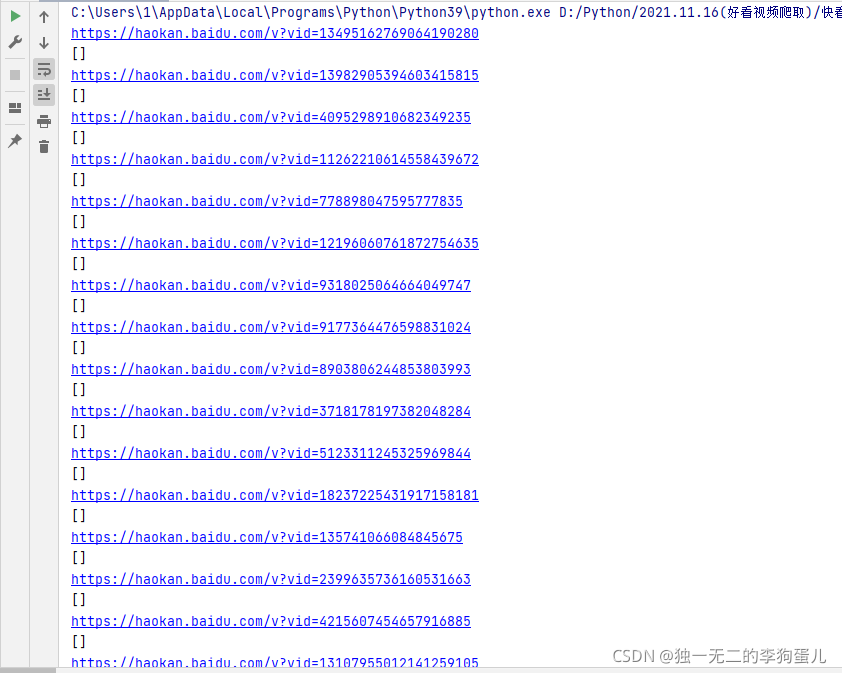
在进入视频详情页后,通过Xpath获取视频链接的时候一直返回的是空列表,无论是通过在headers中添加Cookie还是Referer,又或者是在requests.get()中添加代理IP等等,都无法解决解决。
问题原因:
通过Xpath获取视频的视频链接是虚假的,在源码中无法找到
解决方法:
Network中通过请求数据找到真实的视频网页链接
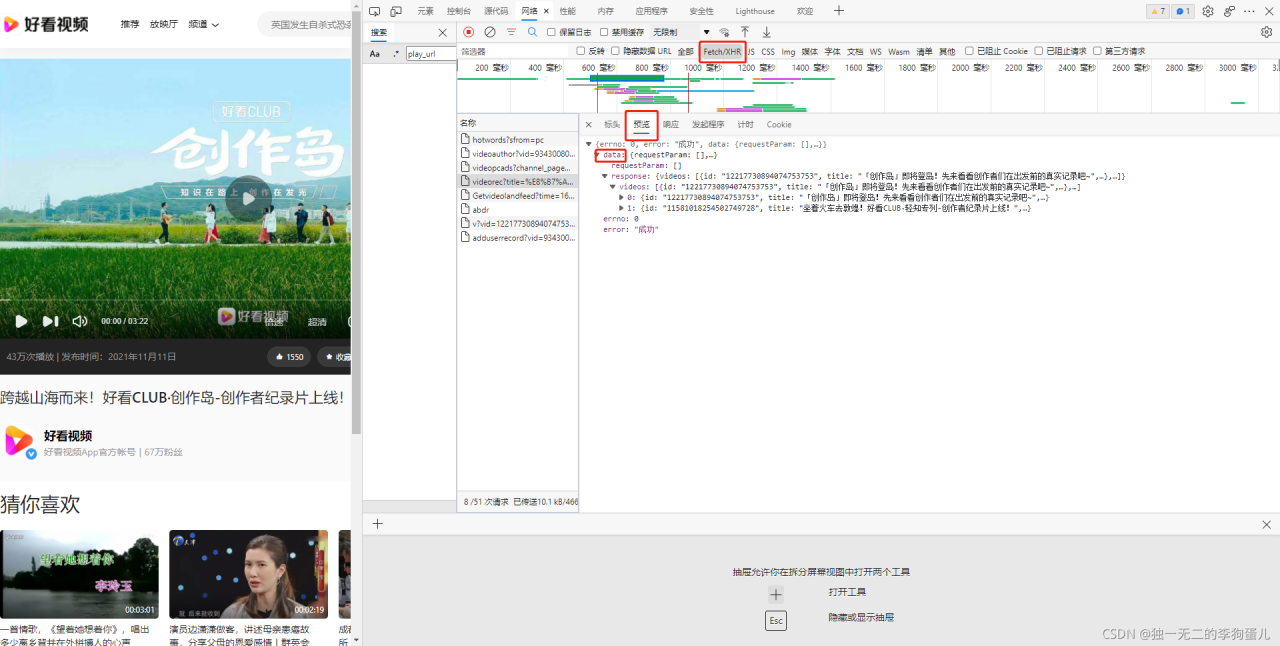
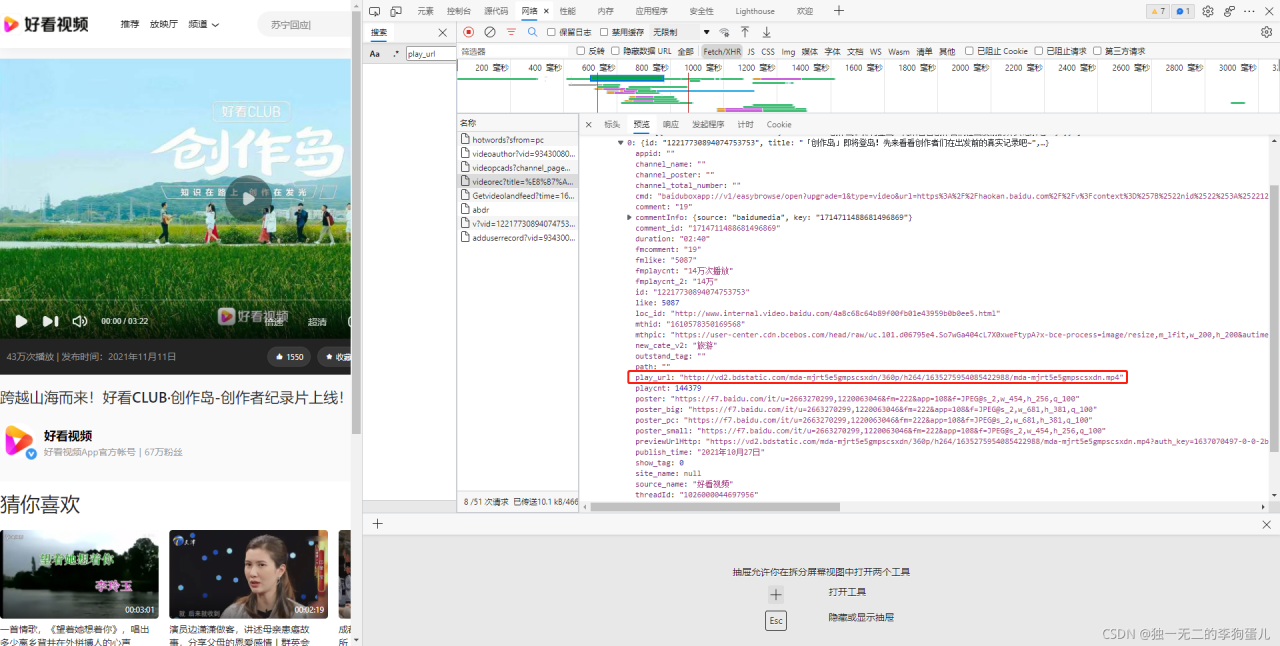
此处为真正的视频链接
如何获取?
找到了真正的视频链接,通过标头的请求URL可以获取
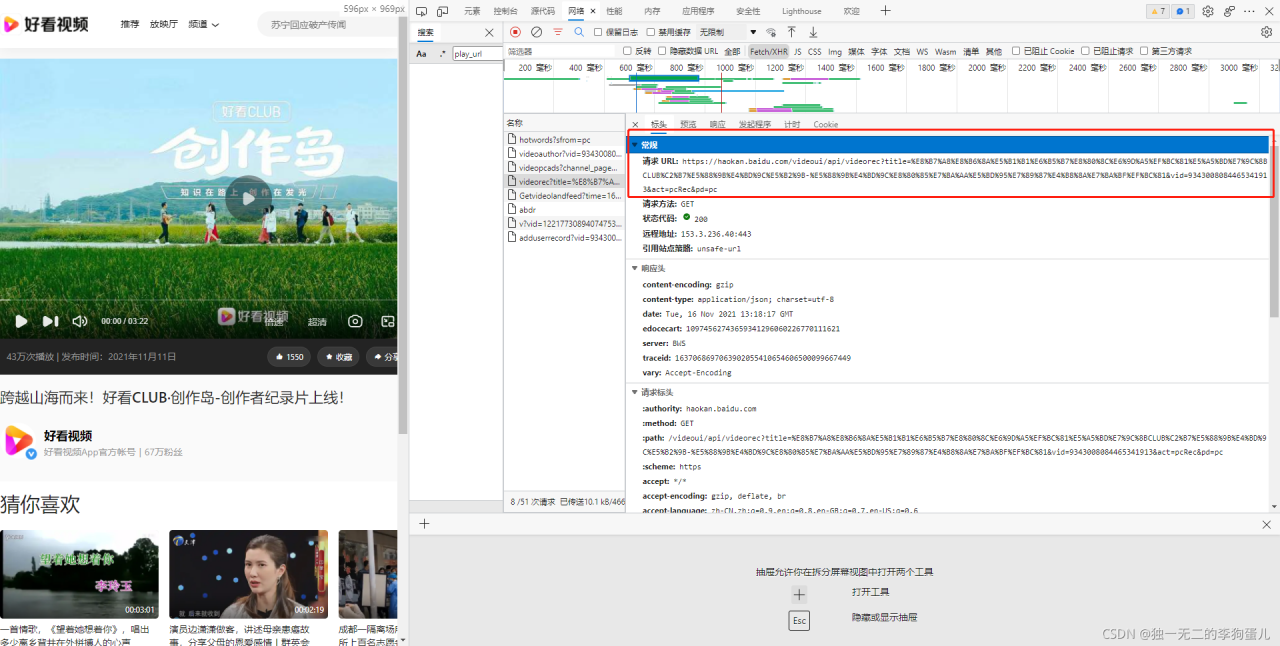
解决结果:
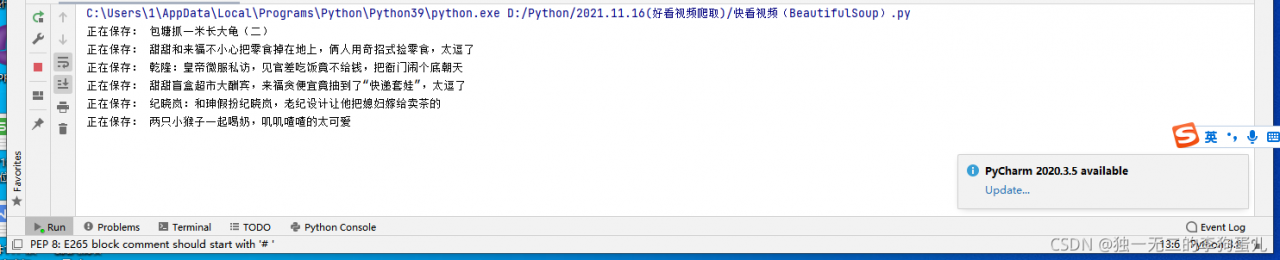
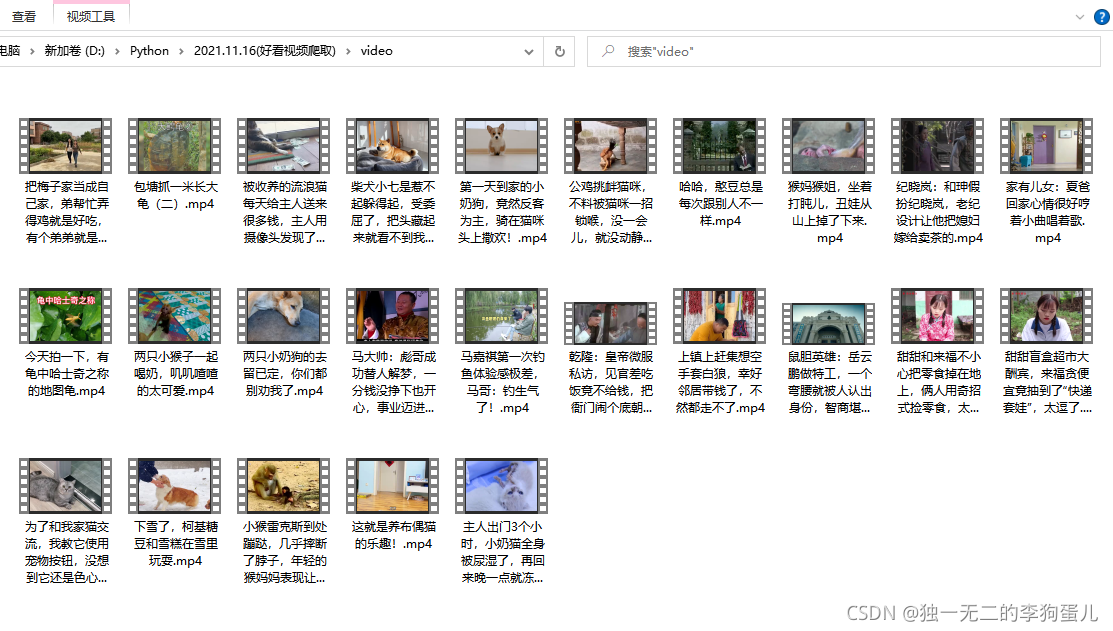
源码:
import os
import requests
#视频网站主页的链接(详情页的需要请求URL)
url = 'https://haokan.baidu.com/videoui/api/videorec?tab=gaoxiao&act=pcFeed&pd=pc&num=20&shuaxin_id=1612592171486'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
json_data = response.json()
#print(json_data)
videos = json_data['data']['response']['videos']
for index in videos:
#print(index)
title = index['title']
play_url = index['play_url']
video_content = requests.get(url=play_url, headers=headers).content
path = 'video\\'
if not os.path.exists(path):
os.mkdir(path)
with open(path + title + '.mp4', mode='wb') as f:
f.write(video_content)
print('正在保存:', title)
版权声明:本文为weixin_53328988原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。