环境:python3.6 + selenium 3.11 + chromedriver.exe
我们在解析网页的时候,总是会遇到大量的tag,如何精确定位到这些tag,也是有很多的方法。
今天在用 find_element_by_class_name获取一个节点对象时,报了个错 Compound class names not permitted.
需要解析的页面结构:
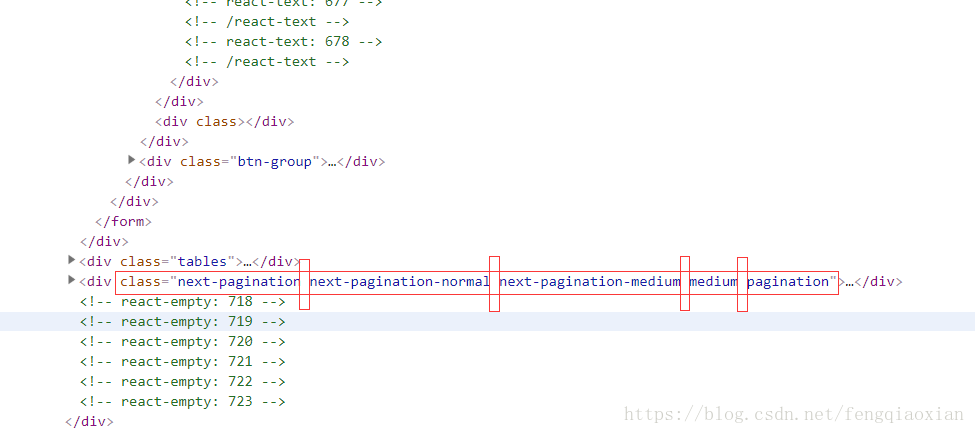
原始代码:
selected_div = driver.find_element_by_class_name('next-pagination next-pagination-normal next-pagination-medium medium pagination')
运行后报错了:

修改后的代码:
selected_div = driver.find_element_by_css_selector("[class='next-pagination next-pagination-normal next-pagination-medium medium pagination']")
或者:
selected_div = driver.find_element_by_css_selector(".next-pagination.next-pagination-normal.next-pagination-medium.medium.pagination")这两段代码都可以正常获取到所需对象。
总结:
在获取包含多个class名称的tag对象时,建议使用:
find_element_by_css_selector(".xx.xxx.xxxxx")
或者
find_element_by_css_selector("[class='xxxxxxxxxx']")
版权声明:本文为fengqiaoxian原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。