KAFKA的元数据与zookeeper
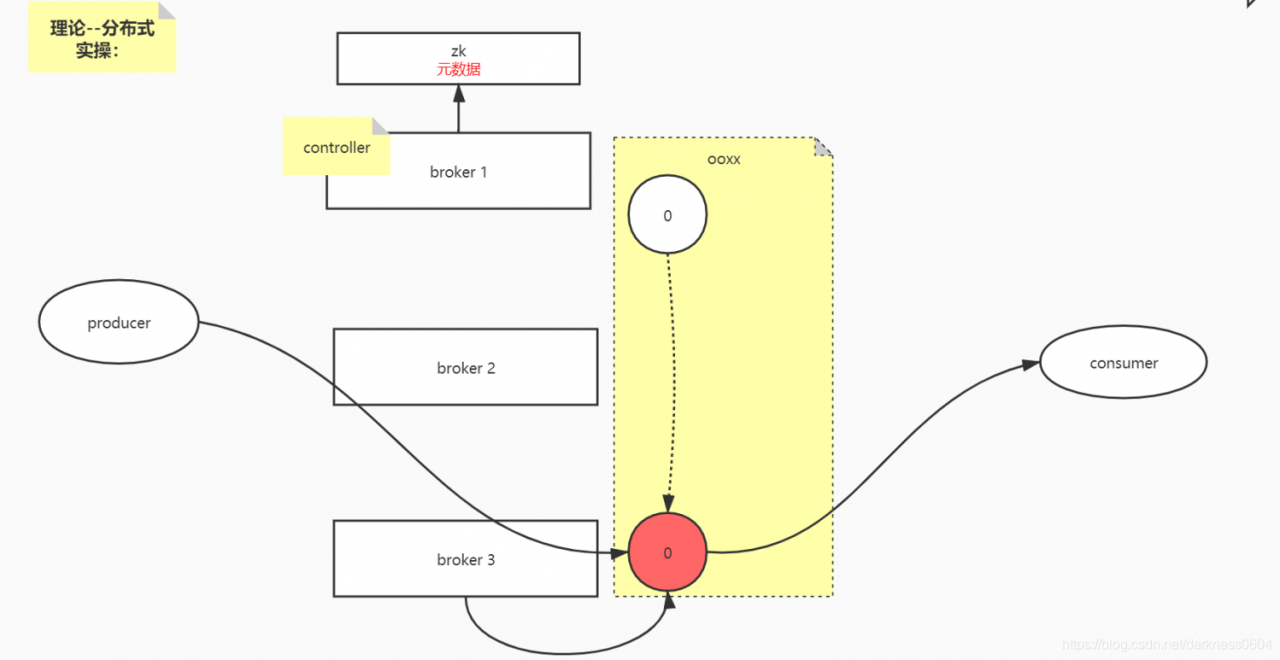
kafka的元数据是交给zookeeper来管理的。
假设我们有topic :ooxx, 副本数为2,主副本在id为3的broker上,另一个副本在id为1的上面。 此时,只有主副本有读写能力,从副本只能备着。
前面我们说过,kafka集群会选出一个broker作为controller,这个选举是借助zookeeper来完成的,zookeeper本质是通过让它们抢占一个临时节点,谁抢到谁就是controller。
如图下: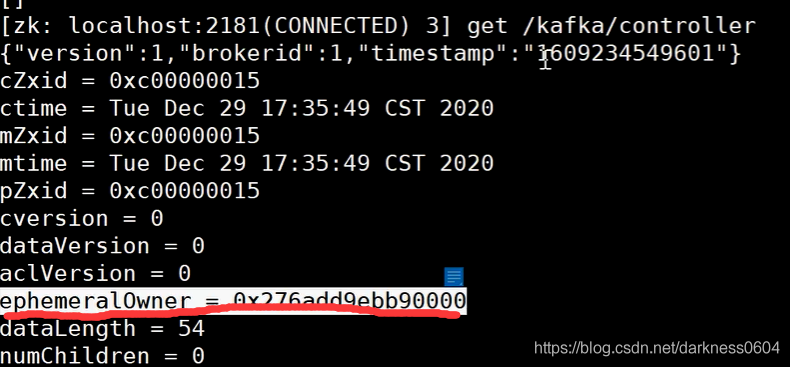
通过zookeeper的kafka路径中查看controller的信息,可以看到目前的controller是id为1的broker,且是一个临时节点。
继续看,zookeeper的kafka路径中还有关于broker节点各自的信息: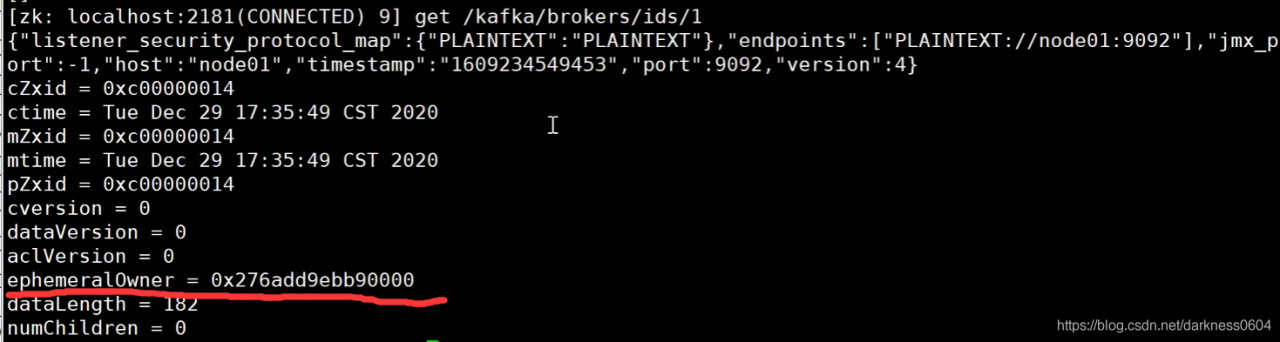
也就是一个真实节点在zookeeper中使用一个临时节点表示.
为什么controller和broker都是使用临时节点来表示? 这是因为,当节点出现宕机时,需要允许集群做出响应,通过临时节点的回调进行对应集群协调处理。
不过,再看一下kafka中的topic的信息,发现会有一个state的状态信息: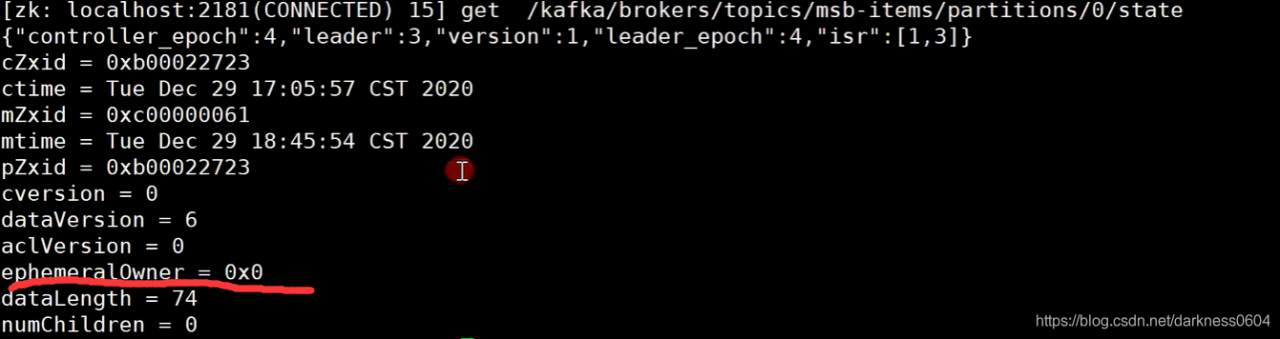
它记录了一个topic的分区的信息,这个topic在创建时设定了2个副本,leader在id为3的broker上面,所有副本分别在1,3的broker上面。
并且,这个节点不是临时节点! 这就是在zookeeper中存储的关于kafka的元数据信息,且这部分信息,在随着某节点宕机后,其他节点也依然可以获取到。
KAFKA的消息存放机制/数据发送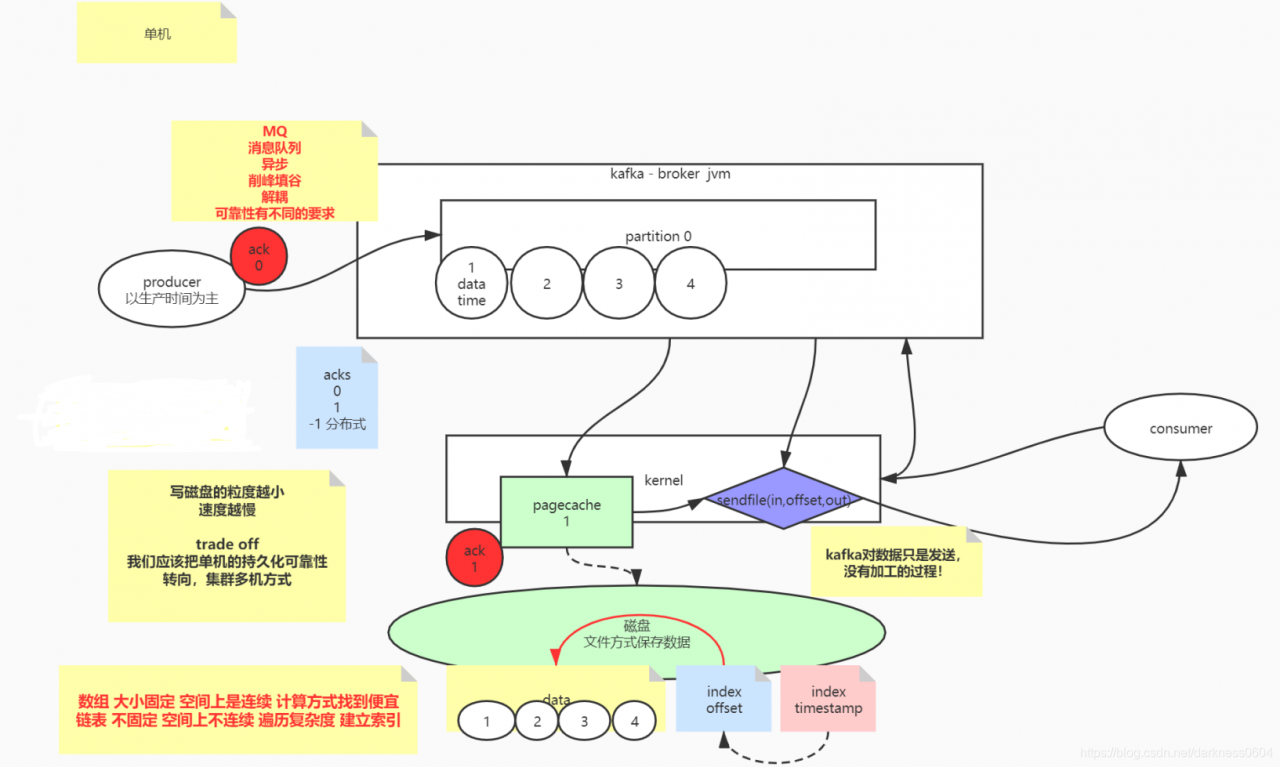
持久化
讨论问题先从简单开始,kafka作为一个消息队列,以一个topic的一个分区派说,kafka的broker会保证生产者发来的消息是有顺序的摆放的,先到来的消息一定放在前面(符合队列的特征:FIFO)。
且kafka的数据最开始先放在内存,但为了数据的可靠性,一定最终需要写入到磁盘进行持久化。 当然,在写入真实的物理磁盘之前,其实程序与物理磁盘之间还有一个东西,叫做内核中的pagecache,实际上程序会先把数据写入到pagecache中,然后根据不同业务需要,会设置不同的写入级别(写入粒度越小,数据会越安全,丢失的粒度越小,但也会越频繁,导致整体的性能速度越慢),这一点,不光是在kafka,而是在任何涉及到写日志的应用都一样。 这里就需要我们进行抉择取舍,实际上,最好不要过高追求磁盘的高可靠性,因为单机情况下,还存在单机故障问题,应该依赖分布式下的副本,来完成高可用性。
磁盘在寻址上,顺序永远比随机要的多,而因为kafka的顺序写消息的特征,是满足顺序写入的特征的,可以达到比较高效的一条条追加写入
索引
offset index
当大量消息被写入后,此时多个消费组来消费时,就涉及到如何找到不同对应offset位置上的消息?
因为每条消息的长度是不同的,kafka会为磁盘上的消息数据建立数据的偏移量offset索引段信息,此时就可以通过offset根据索引找到对应数据。
timestamp index
除此之外,kafka还支持通过时间戳来索引数据,本质是维护了一个时间戳的索引,然后映射到offset index中对应的偏移位置上。
数据发送(Zero Copy零拷贝)
kafka对应生产者发送的数据是不会进行二次加工的,原封不动的进行存储,也因此,当外界的消费端想要拉取数据的时候,kafka可以直接通过系统调用sendfile,直接将pagecache中的对应数据(如果pagecache不存在,从磁盘拉取)发送给消费端即可,而不需要再让数据进入用户态的程序,此即为零拷贝!
pagecache缓存下对于多消费组的增益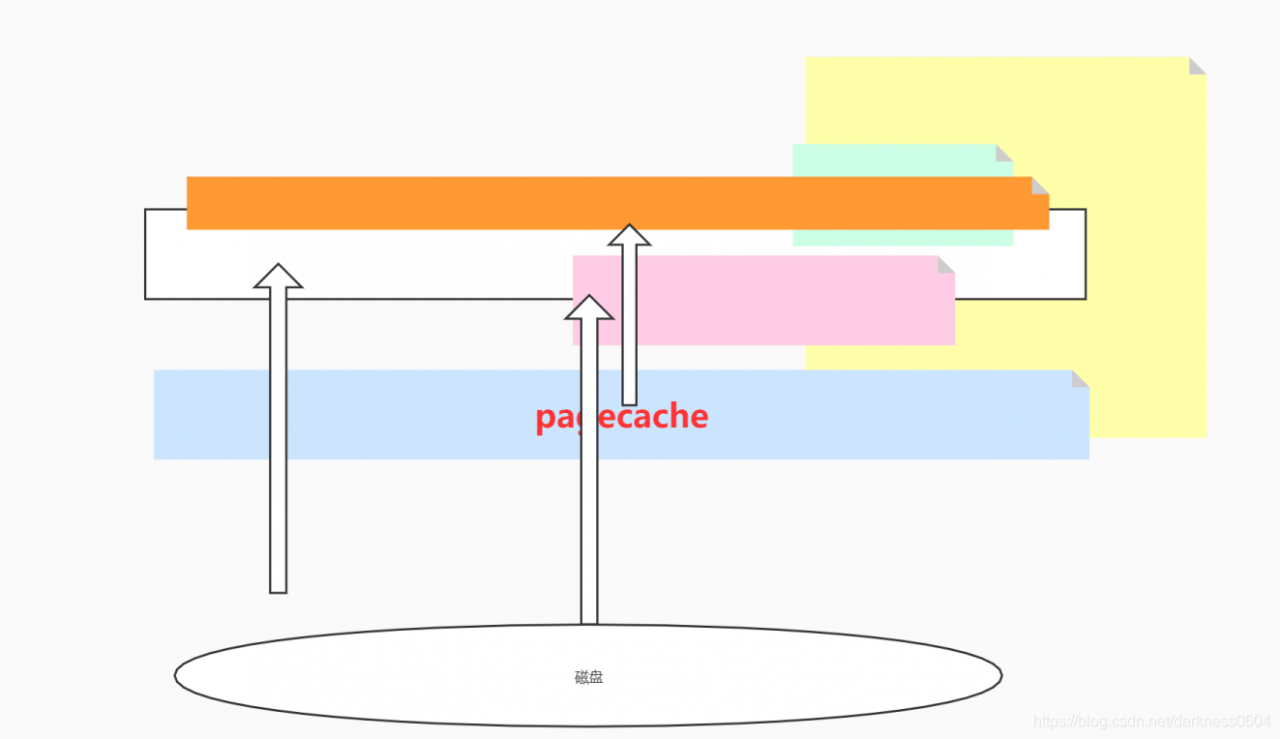
通常来讲,多个消费组对一个分区的消息都是线性读取的,这就会发挥pagecache缓存的优势:上一个consumer进行拉取数据的时候,就可以将磁盘中的数据缓存到pagecache中了,后续的消费组直接从内存的pagecache中拿数据即可,而无需再发生IO操作,可以极大加速拉取速度。
KAFKA的集群一致性同步

这里要先解释几个名词:
ISR:当前所有副本中,依然保持同步活跃的所在节点集合
OSR:那些超过同步阈值时间的不可用副本所在节点的集合
AR:即为所有副本的所在节点的集合
KAFKA的发送消息确认级别
先来说一下关于kafka的发送消息的确认级别,一共有三种级别,ACK为0,1,-1
ACK为0时,当生产者投递出消息后,即为操作完成。
ACK为1时(默认值),当生产者投递出消息后,主副本所在broker对消息进行持久化到pagecache后,回复成功后,即为操作完成。
ACK为-1时,最严苛,这个为分布式的确认级别,当生产者投递出消息后,该消息所属的分区的所有可用副本(ISR)都同步完成时,即为操作成功,在这种级别下,意味着所有的可用的broker的消息进度是一致的。
KAFKA的分布式同步策略取舍
KAFKA既然存在分布式副本,就意味着这里一定要涉及到分布式下的集群数据(主从副本数据)一致性同步的话题。
说到一致性的解决方案,我们可以想到:强一致性(可能破坏服务可用性),以及最终一致性(过半通过,比较常见的,例如典型的zookeeper)。 但kafka对于一致性的解决方案,要更加灵活一些,它只同步给那些集群中还活着的节点(ISR)。
这里我们基于kafka中的某一个topic含有多个副本分区的情况进行讨论,因为此时会涉及到同步的问题:
在kafka中的一个topic含有多个副本分区的情况下,其他的从副本分区其实就相当于主副本分区的consumer。
此时的副本同步需要结合ack级别来进行分别讨论:
1、当确认级别ack设置为-1的时候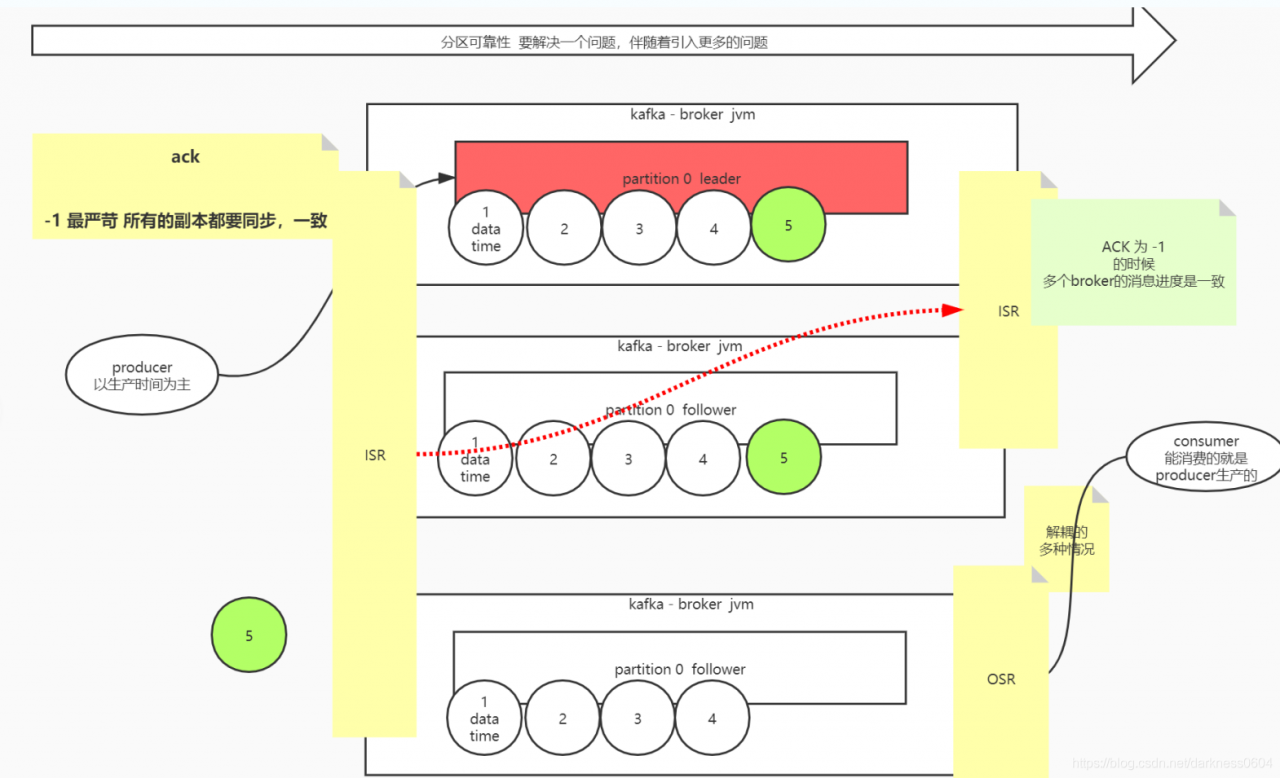
主副本接受到数据后,会进行同步其他副本:
当所谓进行对副本同步的时候,就是这些副本需要在限定阈值时间内(10秒)完成从主副本中对消息数据的拉取(像consumer一样),如果没有在限定时间内拉取完成,那么就会被从ISR中移除,视为一个OSR的副本节点。 然后根据设置的最小同步成功的副本个数,判断本次消息投放操作是否成功,就是看ISR的数量是否达标最小同步成功的副本个数。
例如最小同步数是1,一共有3个副本,其中只有主副本是成功的,另外两个副本都同步失败,变成了OSR,此时这个投放消息的操作也算是成功的,这就是与过半一致性的不同。 这种机制可以支持在集群发送节点故障的情况下,依然保证服务的可用性。
2、当确认级别ack设置为1的时候(默认级别)
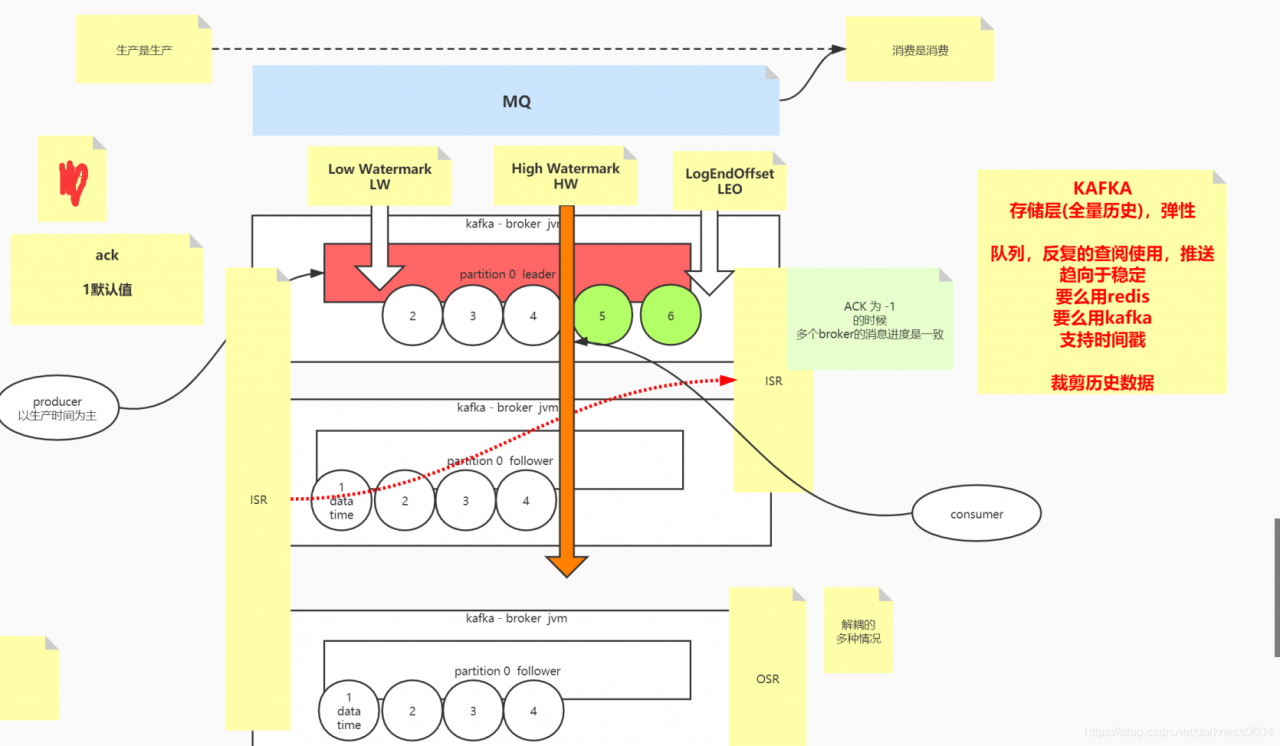
当前情况下,只要主副本完成了接受消息的动作,那么就代表本次发送消息成功。此时将不能完全保证每个broker中的分区副本的消息进度都是相同的。
这里需要先介绍kafka中的几个名词:
1、Log End Offset(LEO),代表当前broker中该分区的消息最后的偏移量位置
2、High WaterMark(HW),高水位线,代表所有broker中该分区消息偏移量一致的最后的位置。
3、Low WaterMark(LW),低水位线,代表所有broker中该分区可以进行消费的位置,kafka典型是用来做mq,但也有场景是用来做为一个具有弹性的存储层服务使用(一般数据都趋向于稳定,用于反复查阅,此时可以用redis或者kafka,且kafka对消息有时间戳索引的功能),但人们往往对于早期放入的历史消息数据不再感兴趣,这些消息会逐渐被淘汰,低水位线之前的消息就是被淘汰的不再可以被访问的历史消息数据,这些历史消息数据将会被删除。
生产是生产,消费是消费,互相之间是互不影响的,且消息的副本同步不会阻塞后续消息的堆积,因此一个broker中的消息偏移量是一直向后追加的,一直到最后的LEO的位置就是当前broker存放的最后一条消息的位置。
KAFKA对外界的consumer来说就是一个黑盒的APP,当consumer来进行消费时,只能读取到该分区HW偏移量之前的消息。
这是为什么呢? 这是因为此时的部分消息可能只有主副本的broker是有的,而其他副本分区的broker还未完成同步,此时如果允许consumer访问最新的LEO的位置,将会导致问题:
举例一个场景: 假设如图上,主副本broker的消息已经追加到了6的位置,此时LEO就是6,而集群中所有broker副本的HW在4的位置上,此时如果consumer可以进行消费HW以后的消息,例如消费了5,6。 此时假设主副本的broker发生了宕机,则会发送主从切换,consumer将会直接将7写入到新的主副本broker上面,但这个broker之前还没有将5,6同步过来。。。 这就造成了麻烦。。
思考为什么默认ack是1呢?
这是kafka做出的权衡,在吞吐量和一致性上面做出的取舍,-1会导致集群吞吐的降低,而1一致性可能会暂时屏蔽部分数据,但保证了整体服务的高吞吐。
由KAFKA总结的分布式中间件下的通用权衡决策思路
1、不要过分强调单机下磁盘的数据可靠性,更好的方式是把可靠性策略转向异地多机副本的同步思路。
2、当使用磁盘进行持久化的时候,需要在pagecache的持久级别上做出取舍。
3、当使用多机集群分布式副本的时候,需要在强一致性、最终一致性(过半)、或者其他(例如KAFKA的ISR)做出取舍。
运用的实际场景
1、redis主要作为缓存服务,宁可使用HA,也不要刻意去追求AOF的可靠性
2、kafka,可以追求ack为-1下的分布式副本同步,而不是追求单机磁盘的可靠性
3、在HA场景下,如果有实例异常退出,是否需要立即尝试重启? 因为异常即使重启也不一定会恢复正常,而可能导致无限的重启,进而会诱发蝴蝶效应,导致整个系统崩盘。