函数式编程
函数式编程语言操纵代码片段就像操作数据一样容易。 虽然 Java 不是函数式语言,但 Java 8 Lambda 表达式和方法引用 (Method References) 允许你以函数式编程。
终于聊到函数式编程了,笔者之前写过一点Haskell,里面的编程思想对我来说简直就是洗脑般的冲击,第一次知道编程可以这么玩。现在我们来了解一下Java的函数式。
引用原文作者的一句话:
OO(object oriented,面向对象)是抽象数据,FP(functional programming,函数式编程)是抽象行为。
仔细想一想面向对象中最重要的类的概念。类是不是就是封装了一系列属性和方法的集合(不是java里面的集合容器的意思)。属性和方法映射到现实生活中就是某个东西的属性和行为,比如动物类 嘴和说话就对应了属性和行为。
至于函数式为什么是抽象了行为暂时我还想不太清楚,希望读完本章我能有个明确的感受?如果有那一天我领悟了,在回来写清楚。
新旧对比
对比Java8的传统方法引用和Lambda表达式:
// functional/Strategize.java
interface Strategy {
String approach(String msg);
}
class Soft implements Strategy {
public String approach(String msg) {
return msg.toLowerCase() + "?";
}
}
class Unrelated {
static String twice(String msg) {
return msg + " " + msg;
}
}
public class Strategize {
Strategy strategy;
String msg;
Strategize(String msg) {
strategy = new Soft(); // [1]
this.msg = msg;
}
void communicate() {
System.out.println(strategy.approach(msg));
}
void changeStrategy(Strategy strategy) {
this.strategy = strategy;
}
public static void main(String[] args) {
Strategy[] strategies = {
new Strategy() { // [2]
public String approach(String msg) {
return msg.toUpperCase() + "!";
}
},
msg -> msg.substring(0, 5), // [3]
Unrelated::twice // [4]
};
Strategize s = new Strategize("Hello there");
s.communicate();
for(Strategy newStrategy : strategies) {
s.changeStrategy(newStrategy); // [5]
s.communicate(); // [6]
}
}
}
输出:
hello there?
HELLO THERE!
Hello
Hello there Hello there
我们直接从main里面分析:
第一个Hello there是下面这段代码执行的结果:
Strategize s = new Strategize("Hello there");
s.communicate();
初始化 Strategize并传入Hello there字符串,然后在Strategize构造函数里面初始化了soft对象并赋值this.msg属性。之后就调用communicate方法。
如下:
void communicate() {
System.out.println(strategy.approach(msg));
}
strategy是上面提到Soft类的实例,msg就是被赋值的属性。之后再Soft类里面就可以很明显看到全部转成了小写加了?号之后返回了。
这很简单,
关键是这段代码:
Strategy[] strategies = {
new Strategy() { // [2]
public String approach(String msg) {
return msg.toUpperCase() + "!";
}
},
msg -> msg.substring(0, 5), // [3]
Unrelated::twice // [4]
};
代码里面往Strategy数组里面以此添加了几个元素:第一元素是用内部类的方式,第二个是lambda表达式,第三个是Java8的方法引用。
可以看到第一个元素使用内部类代码冗余还是比较多的,第二和第三个就很简洁。lambda表达式甚至连类都没没有声明。我找了半天也没有哪里写第二个元素是Strategy类型,难道虚拟机内部帮你转换成了一个Strategy类型的内部类?
之后通过如下代码调用:
for(Strategy newStrategy : strategies) {
s.changeStrategy(newStrategy); // [5]
s.communicate(); // [6]
}
Lambda表达式
Lambda 表达式产生函数,而不是类。 虽然在 JVM(Java Virtual Machine,Java 虚拟机)上,一切都是类,但是幕后有各种操作执行让 Lambda 看起来像函数 —— 作为程序员,你可以高兴地假装它们“就是函数”。
看来虚拟机层面还是直接转成了类的表达形式!
看如下代码:
// functional/LambdaExpressions.java
interface Description {
String brief();
}
interface Body {
String detailed(String head);
}
interface Multi {
String twoArg(String head, Double d);
}
public class LambdaExpressions {
static Body bod = h -> h + " No Parens!"; // [1]
static Body bod2 = (h) -> h + " More details"; // [2]
static Description desc = () -> "Short info"; // [3]
static Multi mult = (h, n) -> h + n; // [4]
static Description moreLines = () -> { // [5]
System.out.println("moreLines()");
return "from moreLines()";
};
public static void main(String[] args) {
System.out.println(bod.detailed("Oh!"));
System.out.println(bod2.detailed("Hi!"));
System.out.println(desc.brief());
System.out.println(mult.twoArg("Pi! ", 3.14159));
System.out.println(moreLines.brief());
}
}
输出结果:
Oh! No Parens!
Hi! More details
Short info
Pi! 3.14159
moreLines()
from moreLines()
先看看Lambda表达式的构成:
static Body bod = h -> h + " No Parens!"; // [1]
static Body bod2 = (h) -> h + " More details"; // [2]
static Description desc = () -> "Short info"; // [3]
static Multi mult = (h, n) -> h + n; // [4]
static Description moreLines = () -> { // [5]
System.out.println("moreLines()");
return "from moreLines()";
};
上面基本可以看出Lambda表示分为 参数,->,方法体。只有一个参数的时候可以省去括号,方法体只有一行的之后可以省去括号。一行的时候表达式的值直接就是表达式的返回值,这时候使用return关键字是非法的。
递归
递归就是无限套娃,概念就是解释了。直接看代码(递归是我的死穴~~~):
// functional/IntCall.java
interface IntCall {
int call(int arg);
}
阶乘:
// functional/RecursiveFactorial.java
public class RecursiveFactorial {
static IntCall fact;
public static void main(String[] args) {
fact = n -> n == 0 ? 1 : n * fact.call(n - 1);
for(int i = 0; i <= 10; i++)
System.out.println(fact.call(i));
}
}
输出结果:
1
1
2
6
24
120
720
5040
40320
362880
3628800
这段代码还是很好理解的关键在这:
fact = n -> n == 0 ? 1 : n * fact.call(n - 1);
传入n,n等于0返回1,不然就递归调用fact.call(n-1)最后赋值给fact;
下面看一个Fibnacci的例子,顺便把递归弄清楚:
// functional/RecursiveFibonacci.java
public class RecursiveFibonacci {
IntCall fib;
RecursiveFibonacci() {
fib = n -> n == 0 ? 0 :
n == 1 ? 1 :
fib.call(n - 1) + fib.call(n - 2);
}
int fibonacci(int n) { return fib.call(n); }
public static void main(String[] args) {
RecursiveFibonacci rf = new RecursiveFibonacci();
for(int i = 0; i <= 10; i++)
System.out.println(rf.fibonacci(i));
}
}
笔者自己调试看了很久才明白每次递归都是进入一个栈帧的概念。如上面的Lambda表达式有两个递归 假设左边为fa1右边为fa2。假设我们求5的斐波那契数列值,然后调用栈如下: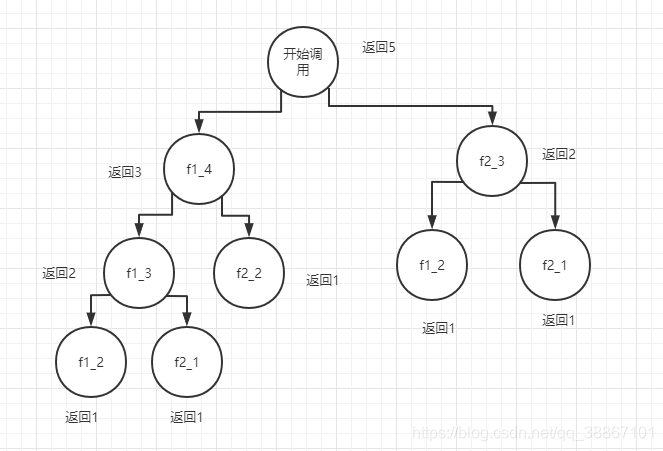
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NmmSI1YZ-1611284342399)(D:\笔记\image\image-20210108171020770.png)]
f1_2表示左边的调用就是上面说的fa1,2表示参数是2;从开始调用开始传入5,左边调减1右边减2。然后开始递归每次都是一个完整的栈帧,方法内的所有代码都要执行,大家看左边的示意图就能明白。突然发现自己词穷,希望大家看图能够明白,再结合debug可以明白。注意底部返回1,返回1是当递归运行到停止条件之后再返回的,也就是对应图上最底部。然后返回的值为调用方法的返回值。一步步向上最终得到所有值。
回到Lambda表达式其实就是简写。
方法引用
代码如下:
// functional/MethodReferences.java
import java.util.*;
interface Callable { // [1]
void call(String s);
}
class Describe {
void show(String msg) { // [2]
System.out.println(msg);
}
}
public class MethodReferences {
static void hello(String name) { // [3]
System.out.println("Hello, " + name);
}
static class Description {
String about;
Description(String desc) { about = desc; }
void help(String msg) { // [4]
System.out.println(about + " " + msg);
}
}
static class Helper {
static void assist(String msg) { // [5]
System.out.println(msg);
}
}
public static void main(String[] args) {
Describe d = new Describe();
Callable c = d::show; // [6]
c.call("call()"); // [7]
c = MethodReferences::hello; // [8]
c.call("Bob");
c = new Description("valuable")::help; // [9]
c.call("information");
c = Helper::assist; // [10]
c.call("Help!");
}
}
输出:
call()
Hello, Bob
valuable information
Help!
首先我来看如下代码
Describe d = new Describe();
Callable c = d::show; // [6]
c.call("call()"); // [7]
输出:
call()
初始化一个类将类内的方法引用直接赋值给接口Callable的变量c然后通过接口唯一的方法call()调用赋值过去的方法,在这里就是show()方法。
再看如下代码:
c = MethodReferences::hello; // [8]
c.call("Bob");
c = new Description("valuable")::help; // [9]
c.call("information");
c = Helper::assist; // [10]
c.call("Help!");
[8]部分Hello方法是静态方法,直接通过::的方式将引用给Callable变量c,[9]help方法就是类内部的普通方法,实质上是[6]的简化版本,也称为绑定方法引用,[10]和[8]就是类似的了。
通过上面的代码可以发现,单一方法的接口像是一个容器一样可以往里面放不同的方法引用,然后通过单一方法接口的方法可以调用赋值的方法。
Runable接口
// functional/RunnableMethodReference.java
// 方法引用与 Runnable 接口的结合使用
class Go {
static void go() {
System.out.println("Go::go()");
}
}
public class RunnableMethodReference {
public static void main(String[] args) {
new Thread(new Runnable() {
public void run() {
System.out.println("Anonymous");
}
}).start();
new Thread(
() -> System.out.println("lambda")
).start();
new Thread(Go::go).start();
}
}
输出:
Anonymous
lambda
Go::go()
三种实现Runable接口,第一个是内部类需要显式的实现run方法,第二种是lambda表达式这个时候甚至都没有显式的去实例化类(实际背后肯定还是类的机制),第三种是方法用的方式,这个前提是你有一个类方法,上面的go方法是静态的就不需要新建Go类的对象。
未绑定的方法引用
这里指的是非静态的方法应用
// functional/UnboundMethodReference.java
// 没有方法引用的对象
class X {
String f() { return "X::f()"; }
}
interface MakeString {
String make();
}
interface TransformX {
String transform(X x);
}
public class UnboundMethodReference {
public static void main(String[] args) {
// MakeString ms = X::f; // [1]
TransformX sp = X::f;
X x = new X();
System.out.println(sp.transform(x)); // [2]
System.out.println(x.f()); // 同等效果
}
}
[1]直接这样使用就会报错 “invalid method reference”,因为f方法不是静态方法,在java里面必须通过对象来调用。TransformX sp = X::f这里没有新建X的对象,但是看下面:
X x = new X();
System.out.println(sp.transform(x)); // [2]
紧着在后面,我们就新建了一个X的对象,然后通过sp.transform(x)将x对象传过去,此时transform方法的第一个参数就是要填对象,实际就是this对象只有通过他你才能来调方法。
如果你的方法有更多个参数,就以第一个参数接受this的模式来处理。
// functional/MultiUnbound.java
// 未绑定的方法与多参数的结合运用
class This {
void two(int i, double d) {}
void three(int i, double d, String s) {}
void four(int i, double d, String s, char c) {}
}
interface TwoArgs {
void call2(This athis, int i, double d);
}
interface ThreeArgs {
void call3(This athis, int i, double d, String s);
}
interface FourArgs {
void call4(
This athis, int i, double d, String s, char c);
}
public class MultiUnbound {
public static void main(String[] args) {
TwoArgs twoargs = This::two;
ThreeArgs threeargs = This::three;
FourArgs fourargs = This::four;
This athis = new This();
twoargs.call2(athis, 11, 3.14);
threeargs.call3(athis, 11, 3.14, "Three");
fourargs.call4(athis, 11, 3.14, "Four", 'Z');
}
}
看来如果传非静态方法的引用是必须需要有对象的,毕竟Java类是第一等公民。
构造函数引用
// functional/CtorReference.java
class Dog {
String name;
int age = -1; // For "unknown"
Dog() { name = "stray"; }
Dog(String nm) { name = nm; }
Dog(String nm, int yrs) { name = nm; age = yrs; }
}
interface MakeNoArgs {
Dog make();
}
interface Make1Arg {
Dog make(String nm);
}
interface Make2Args {
Dog make(String nm, int age);
}
public class CtorReference {
public static void main(String[] args) {
MakeNoArgs mna = Dog::new; // [1]
Make1Arg m1a = Dog::new; // [2]
Make2Args m2a = Dog::new; // [3]
Dog dn = mna.make();
Dog d1 = m1a.make("Comet");
Dog d2 = m2a.make("Ralph", 4);
}
}
直接按main方法里面,mna,m1a,m2a分别被赋值了构造方法引用,然后下面通过make方法调用,然后通过传入不同的参数调用不同的构造方法。原来还以这么玩,是我太菜了。。。。
函数式接口
先看看为什么需要函数式接口?
x -> x.toString()
如上代码,x是什么类型呢?Lambda表达式包含类型推导,再看下面的例子:
(x, y) -> x + y
加操作两边可以是不同的数值类型,也可以是String加任意一种可自动转换为String的类型。当Lambda表达式被编译的时候 x和y的类型必须确定才能生成正确的代码吗。
这同样也适用于方法引用假如 System.out :: println传递到正在编写的方法,该怎么知道传递方法的确切类型呢?
这句话我理解了一会,我觉得可能是这样。你把方法引用传过去,然后调用的时候你怎么知道传的参数的确切类型呢?应该就是这样了!
看如下代码:
// functional/FunctionalAnnotation.java
@FunctionalInterface
interface Functional {
String goodbye(String arg);
}
interface FunctionalNoAnn {
String goodbye(String arg);
}
/*
@FunctionalInterface
interface NotFunctional {
String goodbye(String arg);
String hello(String arg);
}
产生错误信息:
NotFunctional is not a functional interface
multiple non-overriding abstract methods
found in interface NotFunctional
*/
public class FunctionalAnnotation {
public String goodbye(String arg) {
return "Goodbye, " + arg;
}
public static void main(String[] args) {
FunctionalAnnotation fa =
new FunctionalAnnotation();
Functional f = fa::goodbye;
FunctionalNoAnn fna = fa::goodbye;
// Functional fac = fa; // Incompatible
Functional fl = a -> "Goodbye, " + a;
FunctionalNoAnn fnal = a -> "Goodbye, " + a;
}
}
@FunctionalInterface注解作用就是,当方法中的抽象方法多余一个时产生编译错误。
看一下 f和fna,他们是接口却被赋值了方法goodbye()。在Java8中如果将方法引用和Lambda表达式赋值函数式接口(类型需要匹配),Java会适配你的赋值到目标接口。编译器后台会把方法应用或者Lambda表达式包装进实现目标接口的实例中。
Functional fac = fa; // Incompatible这样定义是不允许的因为FunctionalAnnotation并没有显式的实现Functional接口。但是我们可以将函数赋值给接口。
java.util.function包旨在创建一组完整的目标接口,使得我们一般情况下不需再定义自己的接口。主要因为基本类型的存在,导致预定义的接口数量有少许增加。 如果你了解命名模式,顾名思义就能知道特定接口的作用。
也就是说java帮我们定义了一些函数式接口,我们直接用就可以不用再去自己根据类型定义一些常用的函数式接口。
下表描述了 java.util.function 中的目标类型(包括例外情况):
| 特征 | 函数式方法名 | 示例 |
|---|---|---|
| 无参数; 无返回值 | Runnable (java.lang) run() | Runnable |
| 无参数; 返回类型任意 | Supplier get() getAs类型() | Supplier<T> BooleanSupplier IntSupplier LongSupplier DoubleSupplier |
| 无参数; 返回类型任意 | Callable (java.util.concurrent) call() | Callable<V> |
| 1 参数; 无返回值 | Consumer accept() | Consumer<T> IntConsumer LongConsumer DoubleConsumer |
| 2 参数 Consumer | BiConsumer accept() | BiConsumer<T,U> |
| 2 参数 Consumer; 第一个参数是 引用; 第二个参数是 基本类型 | Obj类型Consumer accept() | ObjIntConsumer<T> ObjLongConsumer<T> ObjDoubleConsumer<T> |
| 1 参数; 返回类型不同 | Function apply() To类型 和 类型To类型 applyAs类型() | Function<T,R> IntFunction<R> LongFunction<R> DoubleFunction<R> ToIntFunction<T> ToLongFunction<T> ToDoubleFunction<T> IntToLongFunction IntToDoubleFunction LongToIntFunction LongToDoubleFunction DoubleToIntFunction DoubleToLongFunction |
| 1 参数; 返回类型相同 | UnaryOperator apply() | UnaryOperator<T> IntUnaryOperator LongUnaryOperator DoubleUnaryOperator |
| 2 参数,类型相同; 返回类型相同 | BinaryOperator apply() | BinaryOperator<T> IntBinaryOperator LongBinaryOperator DoubleBinaryOperator |
| 2 参数,类型相同; 返回整型 | Comparator (java.util) compare() | Comparator<T> |
| 2 参数; 返回布尔型 | Predicate test() | Predicate<T> BiPredicate<T,U> IntPredicate LongPredicate DoublePredicate |
| 参数基本类型; 返回基本类型 | 类型To类型Function applyAs类型() | IntToLongFunction IntToDoubleFunction LongToIntFunction LongToDoubleFunction DoubleToIntFunction DoubleToLongFunction |
| 2 参数; 类型不同 | Bi操作 (不同方法名) | BiFunction<T,U,R> BiConsumer<T,U> BiPredicate<T,U> ToIntBiFunction<T,U> ToLongBiFunction<T,U> ToDoubleBiFunction<T> |
定义了那么多函数式接口,一时间也不知道是干啥的,晕乎乎的。直接看看下面的应用吧!
// functional/FunctionVariants.java
import java.util.function.*;
class Foo {}
class Bar {
Foo f;
Bar(Foo f) { this.f = f; }
}
class IBaz {
int i;
IBaz(int i) {
this.i = i;
}
}
class LBaz {
long l;
LBaz(long l) {
this.l = l;
}
}
class DBaz {
double d;
DBaz(double d) {
this.d = d;
}
}
public class FunctionVariants {
static Function<Foo,Bar> f1 = f -> new Bar(f);
static IntFunction<IBaz> f2 = i -> new IBaz(i);
static LongFunction<LBaz> f3 = l -> new LBaz(l);
static DoubleFunction<DBaz> f4 = d -> new DBaz(d);
static ToIntFunction<IBaz> f5 = ib -> ib.i;
static ToLongFunction<LBaz> f6 = lb -> lb.l;
static ToDoubleFunction<DBaz> f7 = db -> db.d;
static IntToLongFunction f8 = i -> i;
static IntToDoubleFunction f9 = i -> i;
static LongToIntFunction f10 = l -> (int)l;
static LongToDoubleFunction f11 = l -> l;
static DoubleToIntFunction f12 = d -> (int)d;
static DoubleToLongFunction f13 = d -> (long)d;
public static void main(String[] args) {
Bar b = f1.apply(new Foo());
IBaz ib = f2.apply(11);
LBaz lb = f3.apply(11);
DBaz db = f4.apply(11);
int i = f5.applyAsInt(ib);
long l = f6.applyAsLong(lb);
double d = f7.applyAsDouble(db);
l = f8.applyAsLong(12);
d = f9.applyAsDouble(12);
i = f10.applyAsInt(12);
d = f11.applyAsDouble(12);
i = f12.applyAsInt(13.0);
l = f13.applyAsLong(13.0);
}
}
如上代码,大家可以发现。其实就是根据接受参数和返回值的类型提前造了好多函数式接口,比如Function<Foo,Bar> f1 = f -> new Bar(f);
因为lambda表达式的参数和返回类型是要推导出来的,函数式接口的类型要和他匹配。如上例子,f就是Foo类型,返回的值Bar类型,仔细看看下面也是如此。
所以说到底,表格里面那些接口就是提前造好个常用参数和返回类型的接口。
再来看看方法引用:
/ functional/MethodConversion.java
import java.util.function.*;
class In1 {}
class In2 {}
public class MethodConversion {
static void accept(In1 i1, In2 i2) {
System.out.println("accept()");
}
static void someOtherName(In1 i1, In2 i2) {
System.out.println("someOtherName()");
}
public static void main(String[] args) {
BiConsumer<In1,In2> bic;
bic = MethodConversion::accept;
bic.accept(new In1(), new In2());
bic = MethodConversion::someOtherName;
// bic.someOtherName(new In1(), new In2()); // Nope
bic.accept(new In1(), new In2());
}
}
输出结果:
accept()
someOtherName()
我们先来看看BiConsumer中的accept代码
void accept(T t, U u);
再来看看上面例子里面accept和someOtherName代码
static void accept(In1 i1, In2 i2) {
System.out.println("accept()");
}
static void someOtherName(In1 i1, In2 i2) {
System.out.println("someOtherName()");
}
最后看看BiConsumer变量的定义:
BiConsumer<In1,In2> bic;
发现没有他们的参数类型和返回都是一样,只要类型一样方法名字根本无所谓。
再来看看将方法引用应用于基于类的函数式接口。
// functional/ClassFunctionals.java
import java.util.*;
import java.util.function.*;
class AA {}
class BB {}
class CC {}
public class ClassFunctionals {
static AA f1() { return new AA(); }
static int f2(AA aa1, AA aa2) { return 1; }
static void f3(AA aa) {}
static void f4(AA aa, BB bb) {}
static CC f5(AA aa) { return new CC(); }
static CC f6(AA aa, BB bb) { return new CC(); }
static boolean f7(AA aa) { return true; }
static boolean f8(AA aa, BB bb) { return true; }
static AA f9(AA aa) { return new AA(); }
static AA f10(AA aa1, AA aa2) { return new AA(); }
public static void main(String[] args) {
Supplier<AA> s = ClassFunctionals::f1;
s.get();
Comparator<AA> c = ClassFunctionals::f2;
c.compare(new AA(), new AA());
Consumer<AA> cons = ClassFunctionals::f3;
cons.accept(new AA());
BiConsumer<AA,BB> bicons = ClassFunctionals::f4;
bicons.accept(new AA(), new BB());
Function<AA,CC> f = ClassFunctionals::f5;
CC cc = f.apply(new AA());
BiFunction<AA,BB,CC> bif = ClassFunctionals::f6;
cc = bif.apply(new AA(), new BB());
Predicate<AA> p = ClassFunctionals::f7;
boolean result = p.test(new AA());
BiPredicate<AA,BB> bip = ClassFunctionals::f8;
result = bip.test(new AA(), new BB());
UnaryOperator<AA> uo = ClassFunctionals::f9;
AA aa = uo.apply(new AA());
BinaryOperator<AA> bo = ClassFunctionals::f10;
aa = bo.apply(new AA(), new AA());
}
}
emmm… 就是普通的将方法引用复制过去嘛,和lambda表达式不同是就是 lambda直接复制的”函数“(至少看上去是这样)。
多参数函数式接口
就是告诉你万一你要的函数式接口官方库里面没有咋办,看着源码自己造呗!下面就是一个三参数的函数式接口
// functional/TriFunction.java
@FunctionalInterface
public interface TriFunction<T, U, V, R> {
R apply(T t, U u, V v);
}
测试一下:
// functional/TriFunctionTest.java
public class TriFunctionTest {
static int f(int i, long l, double d) { return 99; }
public static void main(String[] args) {
TriFunction<Integer, Long, Double, Integer> tf =
TriFunctionTest::f;
tf = (i, l, d) -> 12;
}
}
缺少基本类型的函数
直接看码:
// functional/BiConsumerPermutations.java
import java.util.function.*;
public class BiConsumerPermutations {
static BiConsumer<Integer, Double> bicid = (i, d) ->
System.out.format("%d, %f%n", i, d);
static BiConsumer<Double, Integer> bicdi = (d, i) ->
System.out.format("%d, %f%n", i, d);
static BiConsumer<Integer, Long> bicil = (i, l) ->
System.out.format("%d, %d%n", i, l);
public static void main(String[] args) {
bicid.accept(47, 11.34);
bicdi.accept(22.45, 92);
bicil.accept(1, 11L);
}
}
输出结果:
47, 11.340000
92, 22.450000
1, 11
emmmm 正常理解之内 就是普通的lambda表达式和函数式接口结合起来用。
自动装箱和拆箱和Function一起使用:
// functional/FunctionWithWrapped.java
import java.util.function.*;
public class FunctionWithWrapped {
public static void main(String[] args) {
Function<Integer, Double> fid = i -> (double)i;
IntToDoubleFunction fid2 = i -> i;
}
}
如果么有强制类型转换,则会报错:“Integer cannot be converted to Double”,这时候可以使用IntToDoubleFunction ,源码如下:
@FunctionalInterface
public interface IntToDoubleFunction {
double applyAsDouble(int value);
}
因为我们可以简单地写 Function <Integer,Double> 并产生正常的结果,所以用基本类型(IntToDoubleFunction)的唯一理由是可以避免传递参数和返回结果过程中的自动拆装箱,进而提升性能
高阶函数
这名字听起来好像很牛逼,其实就是接受一个函数作为参数或者返回一个函数的函数(就这样而已)。
看码:
// functional/ProduceFunction.java
import java.util.function.*;
interface
FuncSS extends Function<String, String> {} // [1]
public class ProduceFunction {
static FuncSS produce() {
return s -> s.toLowerCase(); // [2]
}
public static void main(String[] args) {
FuncSS f = produce();
System.out.println(f.apply("YELLING"));
}
}
输出:
yelling
稍微解释一下:
[1]这里继承了函数式接口Function 然后重新命名并且接受参数和返回参数都指定为为String。
[2]返回变小写的方法(lambda表达式)。
要消费一个函数,消费函数需要在参数列表正确地描述函数类型。代码示例:
// functional/ConsumeFunction.java
import java.util.function.*;
class One {}
class Two {}
public class ConsumeFunction {
static Two consume(Function<One,Two> onetwo) {
return onetwo.apply(new One());
}
public static void main(String[] args) {
Two two = consume(one -> new Two());
}
}
当消费函数并且产生函数:
// functional/TransformFunction.java
import java.util.function.*;
class I {
@Override
public String toString() { return "I"; }
}
class O {
@Override
public String toString() { return "O"; }
}
public class TransformFunction {
static Function<I,O> transform(Function<I,O> in) {
return in.andThen(o -> {
System.out.println(o);
return o;
});
}
public static void main(String[] args) {
Function<I,O> f2 = transform(i -> {
System.out.println(i);
return new O();
});
O o = f2.apply(new I());
}
}
输出结果:
I
O
解释一下:
transform接受一个函数然后先执行传进去的函数,然后执行andThen的里面的函数。我们看看andThen的源码(为了方便分析我再放上其他部分):
@FunctionalInterface
public interface Function<T, R> {
R apply(T t);
default <V> Function<V, R> compose(Function<? super V, ? extends T> before) {
Objects.requireNonNull(before);
return (V v) -> apply(before.apply(v));
}
default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {
Objects.requireNonNull(after);
return (T t) -> after.apply(apply(t));
}
static <T> Function<T, T> identity() {
return t -> t;
}
}
首先看看main里面的代码:
Function<I,O> f2 = transform(i -> {
System.out.println(i);
return new O();
});
transform括号里面就是参数(lambda形式的函数),函数参数接受对象I作为参数。所以这句 O o = f2.apply(new I());中的apply实际就是穿进去的函数,new I()就是参数。然后到transform定义的地方的也就是如下代码:
static Function<I,O> transform(Function<I,O> in) {
return in.andThen(o -> {
System.out.println(o);
return o;
});
}
in就是刚刚的上面所说的lambda形式 的函数,然后我们再看andThen的源码参数after实际就是in.andThen的参数,也就是(0->{})。再看andThen源码里面这句。return (T t) -> after.apply(apply(t));他返 回了这个lambda表达式,t为表达式参数。仔细看看in.andThen的调用方法像不像普通对象调用方法的方式,那么此时里层的apply是不是就想是和in对象绑定的属性。我思考了很久还是觉得这样理解比较容易,也不知道想的对不对,是不是依然没有摸到函数式的内核。
闭包
所谓的闭包就是内部方法引用外部变量,java的内部类引用了外部类的变量其实就是一种闭包。我们来看一下作者的解释:
考虑一个更复杂的 Lambda,它使用函数作用域之外的变量。 返回该函数会发生什么? 也就是说,当你调用函数时,它对那些 “外部 ”变量引用了什么? 如果语言不能自动解决,那问题将变得非常棘手。 能够解决这个问题的语言被称作 支持闭包,或者称作 词法定界(lexically scoped ,基于词法作用域的)( 也有用术语 变量捕获 variable capture 称呼的)。Java 8 提供了有限但合理的闭包支持,我们将用一些简单的例子来研究它。
看下面的例子:
// functional/Closure1.java
import java.util.function.*;
public class Closure1 {
int i;
IntSupplier makeFun(int x) {
return () -> x + i++;
}
}
makeFun函数返回一个lambda表达式,表达式引用了外部变量i。看你下面的调用和输出,可以发现 多次函数调用makeFun共享了一个变量i。getAsInt就是IntSupplier函数式接口的唯一方法。
// functional/SharedStorage.java
import java.util.function.*;
public class SharedStorage {
public static void main(String[] args) {
Closure1 c1 = new Closure1();
IntSupplier f1 = c1.makeFun(0);
IntSupplier f2 = c1.makeFun(0);
IntSupplier f3 = c1.makeFun(0);
System.out.println(f1.getAsInt());
System.out.println(f2.getAsInt());
System.out.println(f3.getAsInt());
}
}
输出:
0
1
2
如果i是内部变量怎么办?看如下代码:
// functional/Closure2.java
import java.util.function.*;
public class Closure2 {
IntSupplier makeFun(int x) {
int i = 0;
return () -> x + i;
}
}
编译可以过,然后当makeFun完成之后i就会被GC掉,所以此时lambda表达式内部的i就索引不到了。所以这个例子并不能对x和i进行递增操作。
// functional/Closure3.java
// {WillNotCompile}
import java.util.function.*;
public class Closure3 {
IntSupplier makeFun(int x) {
int i = 0;
// x++ 和 i++ 都会报错:
return () -> x++ + i++;
}
}
x和i必须是final的或者是等同final的效果。但是为什么Closure2就可以运行呢?因为虽然没有明确的声明变量是final,但是你没有改变过变量就默认有了final的效果。
那下面这样会不会错呢?我在lambda表达式之前改变了变量而不是在lambda表达式里面。实际上还是不可以的,引用原文的一句话:
等同 final 效果意味着可以在变量声明前加上 final 关键字而不用更改任何其余代码。 实际上它就是具备 final 效果的,只是没有明确说明。
// functional/Closure5.java
// {无法编译成功}
import java.util.function.*;
public class Closure5 {
IntSupplier makeFun(int x) {
int i = 0;
i++;
x++;
return () -> x + i;
}
}
但是下面这样确实可以的,在改变之后赋值给了final修饰的变量。
// functional/Closure6.java
import java.util.function.*;
public class Closure6 {
IntSupplier makeFun(int x) {
int i = 0;
i++;
x++;
final int iFinal = i;
final int xFinal = x;
return () -> xFinal + iFinal;
}
}
如果使用包装类也是一样不行的。
// functional/Closure7.java
// {无法编译成功}
import java.util.function.*;
public class Closure7 {
IntSupplier makeFun(int x) {
Integer i = 0;
i = i + 1;
return () -> x + i;
}
}
我们尝试一下List:
// functional/Closure8.java
import java.util.*;
import java.util.function.*;
public class Closure8 {
Supplier<List<Integer>> makeFun() {
final List<Integer> ai = new ArrayList<>();
ai.add(1);
return () -> ai;
}
public static void main(String[] args) {
Closure8 c7 = new Closure8();
List<Integer>
l1 = c7.makeFun().get(),
l2 = c7.makeFun().get();
System.out.println(l1);
System.out.println(l2);
l1.add(42);
l2.add(96);
System.out.println(l1);
System.out.println(l2);
}
}
输出:
[1]
[1]
[1, 42]
[1, 96]
为什么使用List看起来就可以呢?因为final是应用于对象引用的,仅表示不会重新复制引用,并不代表你不能修改对象本身。
下面重新对对象引用进行重新赋值就不可以:
// functional/Closure9.java
// {无法编译成功}
import java.util.*;
import java.util.function.*;
public class Closure9 {
Supplier<List<Integer>> makeFun() {
List<Integer> ai = new ArrayList<>();
ai = new ArrayList<>(); // Reassignment
return () -> ai;
}
}
作为闭包的内部类
// functional/AnonymousClosure.java
import java.util.function.*;
public class AnonymousClosure {
IntSupplier makeFun(int x) {
int i = 0;
// 同样规则的应用:
// i++; // 非等同 final 效果
// x++; // 同上
return new IntSupplier() {
public int getAsInt() { return x + i; }
};
}
}
实际上只要有内部类,就会有闭包(Java 8 只是简化了闭包操作)。在 Java 8 之前,变量
x和i必须被明确声明为final。在 Java 8 中,内部类的规则放宽,包括等同 final 效果。
函数组合
函数组合意为多个函数组合成的函数。想想前面的andThen就和那一样。
| 组合方法 | 支持接口 |
|---|---|
andThen(argument) 执行原操作,再执行参数操作 | Function BiFunction Consumer BiConsumer IntConsumer LongConsumer DoubleConsumer UnaryOperator IntUnaryOperator LongUnaryOperator DoubleUnaryOperator BinaryOperator |
compose(argument) 执行参数操作,再执行原操作 | Function UnaryOperator IntUnaryOperator LongUnaryOperator DoubleUnaryOperator |
and(argument) 原谓词(Predicate)和参数谓词的短路逻辑与 | Predicate BiPredicate IntPredicate LongPredicate DoublePredicate |
or(argument) 原谓词和参数谓词的短路逻辑或 | Predicate BiPredicate IntPredicate LongPredicate DoublePredicate |
negate() 该谓词的逻辑非 | Predicate BiPredicate IntPredicate LongPredicate DoublePredicate |
看例子:
// functional/FunctionComposition.java
import java.util.function.*;
public class FunctionComposition {
static Function<String, String>
f1 = s -> {
System.out.println(s);
return s.replace('A', '_');
},
f2 = s -> s.substring(3),
f3 = s -> s.toLowerCase(),
f4 = f1.compose(f2).andThen(f3);
public static void main(String[] args) {
System.out.println(
f4.apply("GO AFTER ALL AMBULANCES"));
}
}
输出:
AFTER ALL AMBULANCES
_fter _ll _mbul_nces
很好理解,根据上面的表格。compose会先执行参数化操作,所以先截取字符串去掉前三个。然后执行f1输出字符串然后将‘A’换成'_'最后执行f3全部转小写。
再看看谓词(Predicate)逻辑的例子:
// functional/PredicateComposition.java
import java.util.function.*;
import java.util.stream.*;
public class PredicateComposition {
static Predicate<String>
p1 = s -> s.contains("bar"),
p2 = s -> s.length() < 5,
p3 = s -> s.contains("foo"),
p4 = p1.negate().and(p2).or(p3);
public static void main(String[] args) {
Stream.of("bar", "foobar", "foobaz", "fongopuckey")
.filter(p4)
.forEach(System.out::println);
}
}
输出:
foobar
foobaz
先执行p1的逻辑非操作,就是保留不包括bar的字符串。然后执行p2就是并且长度大于5最后p3。!p1&&p2 || p3相当于这个操作。寻找包含foo或者不包含bar且长度小于5的字符串
柯里化和部分求值
柯里化的意思就是:将一个多参数的函数,转换为一系列单参数函数。
// functional/CurryingAndPartials.java
import java.util.function.*;
public class CurryingAndPartials {
// 未柯里化:
static String uncurried(String a, String b) {
return a + b;
}
public static void main(String[] args) {
// 柯里化的函数:
Function<String, Function<String, String>> sum =
a -> b -> a + b; // [1]
System.out.println(uncurried("Hi ", "Ho"));
Function<String, String>
hi = sum.apply("Hi "); // [2]
System.out.println(hi.apply("Ho"));
// 部分应用:
Function<String, String> sumHi =
sum.apply("Hup ");
System.out.println(sumHi.apply("Ho"));
System.out.println(sumHi.apply("Hey"));
}
}
输出:
Hi Ho
Hi Ho
Hup Ho
Hup Hey
[1]这里看起来就很奇怪,连续两个箭头。但其实就是b->a+b是就是Function接口定义的第二个参数。
[2]这里就是通过单个参数创建一个函数,所以现在有了一个“带参函数”和剩下的 “自由函数”(free argument) 。实际上,你从一个双参数函数开始,最后得到一个单参数函数。
我们来柯里化一个三参数函数:
// functional/Curry3Args.java
import java.util.function.*;
public class Curry3Args {
public static void main(String[] args) {
Function<String,
Function<String,
Function<String, String>>> sum =
a -> b -> c -> a + b + c;
Function<String,
Function<String, String>> hi =
sum.apply("Hi ");
Function<String, String> ho =
hi.apply("Ho ");
System.out.println(ho.apply("Hup"));
}
}
输出:
Hi Ho Hup
是不是有种剥洋葱的感觉和套娃似的,最后得到单参数的函数。
处理基本类型和装箱的时候,请使用适当的函数式接口:
// functional/CurriedIntAdd.java
import java.util.function.*;
public class CurriedIntAdd {
public static void main(String[] args) {
IntFunction<IntUnaryOperator>
curriedIntAdd = a -> b -> a + b;
IntUnaryOperator add4 = curriedIntAdd.apply(4);
System.out.println(add4.applyAsInt(5));
}
}
输出
9
纯函数式编程
建议看看Haskell,虽然Java可以进行函数式编程,但是我感觉有些瘸腿。你得保证一切都是final的,同时你的所有方法和函数没有副作用。
小结
函数式对我来说,其实思维上冲击挺大的。这章我理解了很久,这篇笔记也卡了很久。但是我觉得理解之后,让我可以拥有更高的抽象能力。