文章目录
一、文章解决的问题
1.提出了two-stream结构的CNN,由空间和时间两个维度的网络组成
2.使用多帧的稠密光流场作为训练输入,可以提取动作的信息
3.利用了多任务学习的方法把两个数据集联合起来
二、论文细节
1.双流网络的具体结构是什么
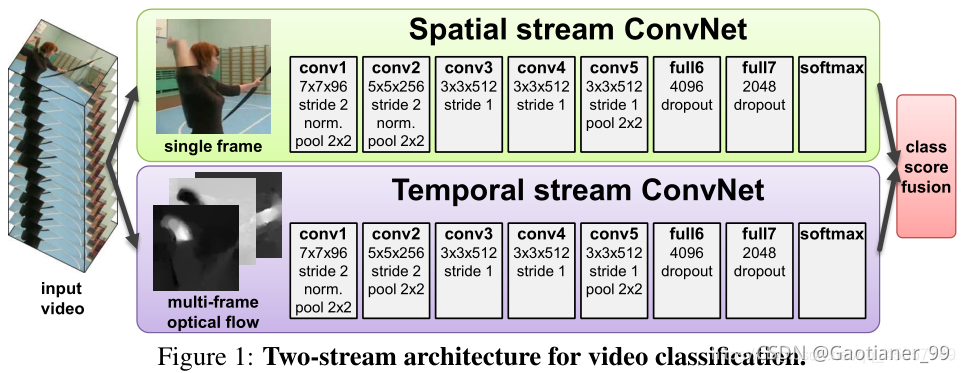
该网络有两个独立的识别流——空间和时间,在网络尾部再用softmax融合在一起。空间流(Spatial stream ConvNet)从静态的视频单帧中识别动作,而时间流(Temporal stream ConvNet)以稠密光流的形式从运动中识别动作。这两个流均为ConvNets。时间流的输入是通过几个连续帧之间叠加光流位移场来实现的。
双流网络的结构,由两个独立的网络构成,Spatial stream ConvNet的输入是单张图像,用来对目标和场景的appearance提取特征(有些action的识别依赖单张图像就够,有些则必须依赖运动和时间特征)。Temporal stream ConvNet的输入是多张相邻帧的光流,对motion特征进行表示。通过两个网络的softmax输出向量进行融合,来最终确定分类。
2.两个网络怎么合并在一起
空间流和时间流分别经过softmax后做class score fusion
(1)求平均
(2)以L2正则化的softmax输出作为特征,训练多分类线性SVM
3.optical flow(光流)是什么
optical flow(光流):提取出物体运动的方向和速度,颜色表示方向,亮度表示速度。
Dense optical flow(稠密光流):可以看做是连续帧t和t+1之间的位移向量场的集合。用 dt(u,v)表示第t帧中点(u,v)移动到下一帧t+1中相应的点的位移向量。向量场dt包含两部分(因为每个像素点有x和y方向的移动):水平分量dtx和垂直分量dty,L表示堆叠的帧数,那么一共可以得到2L个通道的光流(x和y两个方向)然后作为Temporal stream ConvNet的输入。
假设一个视频的宽和高分别是w和h,那么Temporal stream ConvNet的输入维度Iτ应该是下式 ,其中τ表示任意的一帧。
有两种得到Iτ的方法,分别为optical flow stacking和trajectory stacking。
Optical flow stacking(光流的简单叠加):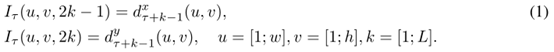
公式(1)给出了水平和垂直方向的I τ的计算公式,其中 (u,v) 表示任意一个点的坐标,c是通道, c=[1;2L],因此Iτ(u,v,c) 存的就是(u,v)这个位置的位移向量。简单的光流场叠加并没有追踪,每个都是计算的某帧t+1中某个像素点(u,v)相对于t 帧中对应像素点(u,v)的位移,光流场叠加最终得到的是每个像素点的两帧之间的光流图。
trajectory stacking(轨迹叠加):
轨迹叠加就是假设第一帧的某个像素点,我们可以通过光流来追踪它在视频中的轨迹。在几个帧的相同位置采样,沿着运动轨迹采样。帧τ对应的输入Iτ为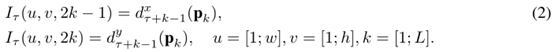
Pk是轨迹上的第k个点,在帧τ的开始位置为 (u,v),且定义以下递推关系
公式(1)中Iτ(u,v,c)存的是位置(u,v)处的位移向量(displacement vectors),而公式(2)中 Iτ(u,v,c)存的是沿着轨迹Pk采样的向量。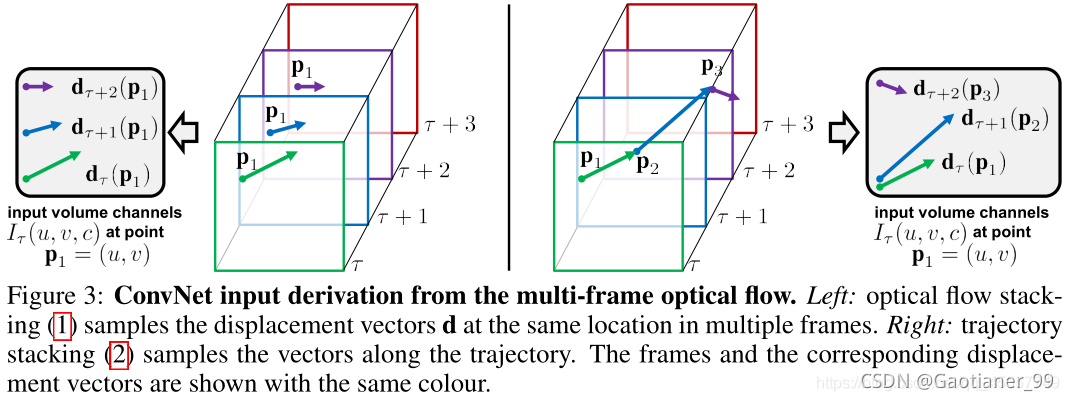
4.多任务学习怎么做
Spatial stream ConvNet输入的是静态的图像,所以其预训练模型较容易得到(一般采用在ImageNet数据集上的预训练模型),但是Temporal stream ConvNet的预训练模型需要在视频数据集上训练得到,目前可供训练的视频数据集很少,所以作者提出能不能把多个数据集(这里就是UCF101和HMDB-51,训练集数量分别是9500和3700个视频)联合起来,这样还能避免过拟合的现象。由此文章采用multi-task的方式来解决。
首先原来的网络(Temporal stream ConvNet)在全连接层后只有一个softmax层,现在要变成两个softmax层,一个用来计算UCF-101数据集的分类输出,另一个用来计算HDMB-51数据集的分类输出,这就是两个task。这两条支路有各自的loss,最终的loss就是两个loss的和,然后回传更新参数。所以这里的重点就是:网络全卷积层是不变的,或者说对于两个数据集是共享参数的。只是改变了最终的loss。
5.Bi-directional optical flow(双向光流)
光流的简单叠加和轨迹叠加两个方法其实考虑的都是前馈光流,都是依靠后一帧计算相对于前一帧的光流。当我们考虑 T 帧时,我们不再一直往后堆 L 帧,而是计算 T 帧之前 L/2 和 T 帧之后的 L/2 帧。
6.优点和不足
(1)优点:
提出了two-stream(spatial stream convnet获取图像目标和场景的appearance,temporal stream convnet获取时序motion信息),开创了two-stream视频分析时代
(2)不足:
<1>不是完全end-to-end的视频分析,需要离线计算光流,计算光流比较耗时,没法达到实时
<2>解决的是short-term video分析,没法有效的解决long-term video分析。