(1)flow_from_dataframe函数实例
参考文章
keras中文官方文档flow_from_dataframe()
flow_from_dataframe()
我们需要train训练集图片文件都放在一个文件夹里,
然后csv文件的形式是文件名对应类标签,
然后调用flow_from_dataframe()就可以
- 传入该csv文件名 和 图像所在的文件夹
- 传入x_col: 字符串,dataframe 中包含目标图像文件夹的目录的列。
- y_col: 字符串或字符串列表,dataframe 中将作为目标数据的列。
- subset 在指定了validation的时候使用
- batch_size
- shuffle
- class_mode =“categorical”,
- target_size =(32,32)
开始~
首先,下载数据集并将图像文件保存在单个目录下
例如,我将使用cifar-10数据集
下载并解压缩train.7z和test.7z,将获得 “train”的文件夹和“test”文件夹
下载trainLabels.csv文件,该文件将训练图像的文件名映射到类名
导入包并使用pandas读取CSV文件
from keras.models import Sequential
from keras.preprocessing.image import ImageDataGenerator
from keras.layers import Dense, Activation, Flatten, Dropout, BatchNormalization
from keras.layers import Conv2D, MaxPooling2D
from keras import regularizers, optimizers
import pandas as pd
import numpy as np
def append_ext(fn):
return fn+".png"
traindf=pd.read_csv(“./trainLabels.csv”,dtype=str)
testdf=pd.read_csv("./sampleSubmission.csv",dtype=str)
traindf["id"]=traindf["id"].apply(append_ext)
testdf["id"]=testdf["id"].apply(append_ext)
datagen=ImageDataGenerator(rescale=1./255.,validation_split=0.25)
将“.png”附加到数据框“id”列中的所有文件名,以将文件ID转换为实际文件名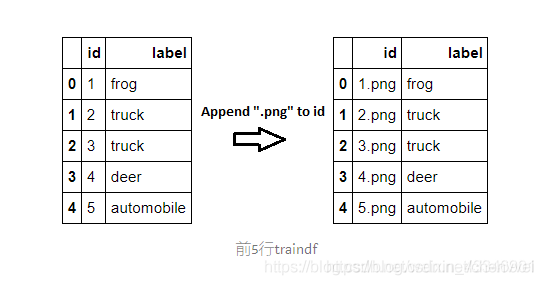
将train分为2组,一组用于训练(train),另一组用于验证(vaild),只需指定参数validation_split = 0.25,将数据集拆分为2组,其中验证集将占总图像的25%
将数据帧传递给两个不同的flow_from_dataframe函数
将数据帧传递给两个不同的flow_from_dataframe函数
train_generator = datagen.flow_from_dataframe(dataframe = traindf,
directory =“./ train /”,
x_col =“id”,
y_col =“label”,
subset =“training”,
batch_size = 32,
seed = 42,
shuffle = True,
class_mode =“categorical”,
target_size =(32,32))
valid_generator = datagen.flow_from_dataframe(dataframe = traindf,
directory =“./ train /”,
x_col =“id”,
y_col =“label”,
subset =“validation”,
batch_size = 32,
seed = 42,
shuffle = True,
class_mode =“categorical”,
target_size =(32,32))
testdatagen = ImageDataGenerator(rescale = 1. / 255。)
test_generator = test_datagen.flow_from_dataframe(dataframe = testdf,
directory =“./ test /”,
x_col =“id”,
y_col = None,
batch_size = 32,
seed = 42,
shuffle = False,
class_mode = None,
target_size =(32,32))
由于ImageDataGenerator中使用了validation_split分割数据集,因此必须指定哪个集合用于哪个flow_from_dataframe函数,即
datagen.flow_from_dataframe()中必须指定suset是training还是validation
创建模型:
train_generator = datagen.flow_from_dataframe(dataframe = traindf,
directory =“./ train /”,
x_col =“id”,
y_col =“label”,
subset =“training”,
batch_size = 32,
seed = 42,
shuffle = True,
class_mode =“categorical”,
target_size =(32,32))
valid_generator = datagen.flow_from_dataframe(dataframe = traindf,
directory =“./ train /”,
x_col =“id”,
y_col =“label”,
subset =“validation”,
batch_size = 32,
seed = 42,
shuffle = True,
class_mode =“categorical”,
target_size =(32,32))
testdatagen = ImageDataGenerator(rescale = 1. / 255。)
test_generator = test_datagen.flow_from_dataframe(dataframe = testdf,
directory =“./ test /”,
x_col =“id”,
y_col = None,
batch_size = 32,
seed = 42,
shuffle = False,
class_mode = None,
target_size =(32,32))
拟合模型fit_generator()
STEP_SIZE_TRAIN=train_generator.n//train_generator.batch_size
STEP_SIZE_VALID=valid_generator.n//valid_generator.batch_size
STEP_SIZE_TEST=test_generator.n//test_generator.batch_size
model.fit_generator(generator=train_generator,
steps_per_epoch=STEP_SIZE_TRAIN,
validation_data=valid_generator,
validation_steps=STEP_SIZE_VALID,
epochs=10
)
评估模型
model.evaluate_generator(generator=valid_generator,
steps=STEP_SIZE_TEST)
由于我们正在评估模型,因此我们应该将验证集视为测试集。因此,我们应该只在验证集中对图像进行一次采样(如果您计划进行评估,则需要将有效生成器的批量大小更改为1或者确切地划分验证集中样本总数的内容),但是顺序无关紧要,所以让“shuffle”变得像以前一样真实
预测模型
1、重置,reset(),并predict_generator()
无论何时调用predict_generator,都需要重置test_generator。这很重要,如果没有重置test_generator,输出的的顺序会打乱。
test_generator.reset()
pred = model.predict_generator(test_generator,
steps = STEP_SIZE_TEST,
verbose = 1)
2、将预测的概率矩阵pred转换为类别class_indices
predicted_class_indices=np.argmax(pred,axis=1)
现在predict_class_indices中有预测的标签,但你还不能知道预测的什么,因为你能看到的只是0,1,4,1,0,6等数字…
3、需要用预测的标签映射他们独特的ID(如文件名),以找出预测的图像
train_generator.class_indices可以获取包含类名到类索引的字典例如,dog 对应0,cat 对应1
labels = (train_generator.class_indices)
#k是类名,即dog,cat,v是数字索引,即labels变成
#{1: 'dog', 2: 'cat'}
labels = dict((v,k) for k,v in labels.items())
predictions = [labels[k] for k in predicted_class_indices]
结果保存为CSV文件
filenames=test_generator.filenames
results=pd.DataFrame({"Filename":filenames, "Predictions":predictions})
results.to_csv("results.csv",index=False)