什么是并发
计算机术语中的"并发",指的是在单个系统里同时执行多个独立的活动,而不是顺序的一个接一个的执行。对于单核CPU来说,在某个时刻只可能处理一个任务,但它却不是完全执行完一个任务再执行一个下一任务,而是一直在任务间切换,每个任务完成一点就去执行下一个任务,看起来就像任务在并行发生,虽然不是严格的同时执行多个任务,但是我们仍然称之为 并发(concurrency) 。真正的并发是在在多核CPU上,能够真正的同时执行多个任务,称为硬件并发(hardware concurrency)。
注意: 在单核CPU并发执行两个任务需要付出上下文切换的时间代价。
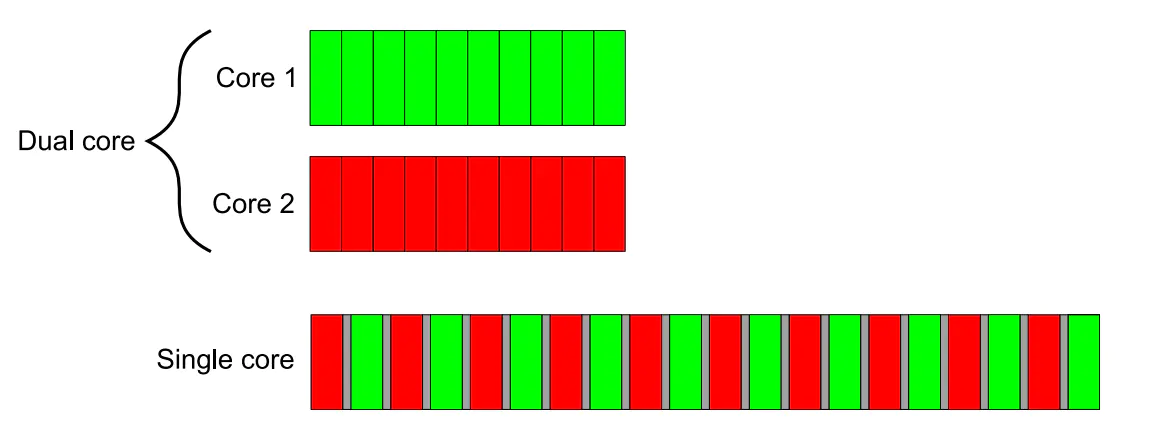
图中,single core 并发执行时,需要小号任务切换时间,即图中灰色部分。
并发方式
多进程并发
将应用程序分为多个独立的、单线程的进程,他们可以同时运行。这些独立的进程可以通过常规的进程间通信机制进行通信,如管道、信号、消息队列、共享内存、存储映射I/O、信号量、套接字等.
缺点:
- 进程间通信较为复杂,速度相对线程间的通信更慢。
- 启动进程的开销比线程大,使用的系统资源也更多。
优点:
- 进程间通信的机制相对于线程更加安全。
- 能够很容易的将一台机器上的多进程程序部署在不同的机器上(如果通信机制选取的是套接字的话)。
多线程并发
线程很像轻量级的进程,但是一个进程中的所有线程都共享相同的地址空间,线程间的大部分数据都可以共享。线程间的通信一般都通过共享内存来实现。
优点:
- 由于可以共享数据,多线程间的通信开销比进程小的多。
- 线程启动的比进程快,占用的资源更少。
缺点:
- 共享数据太过于灵活,为了维护正确的共享,代码写起来比较复杂。
- 无法部署在分布式系统上。
多线程编程
- 多线程标准库
C++98标准中并没有线程库的存在,而在C++11中终于提供了多线程的标准库,提供了管理线程、保护共享数据、线程间同步操作、原子操作等类。
#include <iostream>
#include <thread>
void function_1() {
std::cout << "I'm function_1()" << std::endl;
}
int main() {
std::thread t1(function_1);
// do other things
t1.join();
return 0;
}
分析:
- 首先,构建一个
std::thread对象t1,构造的时候传递了一个参数,这个参数是一个函数,这个函数就是这个线程的入口函数,函数执行完了,整个线程也就执行完了。 - 线程创建成功后,就会立即启动,并没有一个类似
start的函数来显式的启动线程。
一旦线程开始运行, 就需要显式的决定是要等待它完成(join,主线程在此卡住,等候),或者分离它让它自行运行(detach,主线程继续执行)。这个例子中选择了使用t1.join(),主线程会一直阻塞着,直到子线程完成,join()函数的另一个任务是回收该线程中使用的资源。
线程对象和对象内部管理的线程的生命周期并不一样,如果线程执行的快,可能内部的线程已经结束了,但是线程对象还活着,也有可能线程对象已经被析构了,内部的线程还在运行。
假设t1线程是一个执行的很慢的线程,主线程并不想等待子线程结束就想结束整个任务,直接删掉t1.join()是不行的,程序会被终止(析构t1的时候会调用std::terminate,程序会打印terminate called without an active exception)。
与之对应,我们可以调用t1.detach(),从而将t1线程放在后台运行,所有权和控制权被转交给C++运行时库,以确保与线程相关联的资源在线程退出后能被正确的回收。参考UNIX的守护进程(daemon process)的概念,这种被分离的线程被称为守护线程(daemon threads)。线程被分离之后,即使该线程对象被析构了,线程还是能够在后台运行,只是由于对象被析构了,主线程不能够通过对象名与这个线程进行通信。例如:
#include <iostream>
#include <thread>
void function_1() {
//延时500ms 为了保证test()运行结束之后才打印
std::this_thread::sleep_for(std::chrono::milliseconds(500));
std::cout << "I'm function_1()" << std::endl;
}
void test() {
std::thread t1(function_1);
t1.detach();
// t1.join();
std::cout << "test() finished" << std::endl;
}
int main() {
test();
//让主线程晚于子线程结束
std::this_thread::sleep_for(std::chrono::milliseconds(1000)); //延时1s
return 0;
}
// 使用 t1.detach()时
// test() finished
// I'm function_1()
// 使用 t1.join()时
// I'm function_1()
// test() finished
分析:
- 由于线程入口函数内部有个
500ms的延时,所以在还没有打印的时候,test()已经执行完成了,t1已经被析构了,但是它负责的那个线程还是能够运行,这就是detach()的作用。 - 如果去掉
main函数中的1s延时,会发现什么都没有打印,因为主线程执行的太快,整个程序已经结束了,那个后台线程被C++运行时库回收了。如果将t1.detach()换成t1.join(),test函数会在t1线程执行结束之后,才会执行结束。 - 一旦一个线程被分离了,就不能够再被
join了。如果非要调用,程序就会崩溃,可以使用joinable()函数判断一个线程对象能否调用join()。
注意: 在使用detach()时,如果t1线程中用到主线程中的变量,当主线程main函数退出时,t1线程很可能会出现问题,因此需要慎用detach()功能。
线程锁
加锁要求:
1.对于int,short,char,BOOL等小于等于4字节的简单数据类型,如果无逻辑上的先后关系,多线程读写可以完全不用加锁
2.尽管float为4字节,多线程访问时也需要加锁
3.对于大于4字节的简单类型,比如double,__int64等,多线程读写必须加锁。
4.对于所有复杂类型,比如类,结构体,容器等类型必须加锁
基本锁类型
- std::mutex 最基本也是最常用的互斥类
- std::recursive_mutex 同一线程内可递归(重入)的互斥类
- timed_mutex带超时功能。在规定的等待时间内,没有获取锁,线程不会一直阻塞,代码会继续执行。
功能
lock:如果互斥量没有被锁住,则调用线程将该mutex锁住,直到调用线程调用unlock释放。
unlock:如果mutex已被其它线程lock,则调用线程将被阻塞,直到其它线程unlock该mutex。如果当前mutex已经被调用者线程锁住,则std::mutex死锁,而recursive系列则成功返回true。
try_lock:
1.如果互斥锁当前未被任何线程锁定,则调用线程将其锁定(从此点开始,直到调用其成员解锁,该线程拥有互斥锁)。
2.如果互斥锁当前被另一个线程锁定,则该函数将失败并返回false,而不会阻塞(调用线程继续执行)。
3.如果互斥锁当前被调用此函数的同一线程锁定,则会产生死锁(具有未定义的行为)。
std::mutex mtx;
volatile int counter;
static void attempt_10k_increases()
{
for (int i = 0; i<10000; ++i)
{
if (mtx.try_lock())
{
++counter;
mtx.unlock();
}
//mtx.lock();
//++counter;
//mtx.unlock();
}
}
int test_mutex_3()
{
std::thread threads[10];
for (int i = 0; i<10; ++i)
threads[i] = std::thread(attempt_10k_increases);
for (auto& th : threads)
th.join();
std::cout << counter << "successful increases of the counter.\n";
return 0;
}
int main()
{
test_mutex_3();
getchar();
return 0;
}
分析: 经过多次运行,可以发现counter的值基本集中在3W多,4W多,5W多,而如果不用try_lock(),使用lock(),counter的值一定是100000。
timed_mutex 应用举例:
#include <iostream>
#include <thread>
#include <mutex>
#include <chrono>
void run500ms(std::timed_mutex &mutex) {
auto _500ms = std::chrono::milliseconds(500);
if (mutex.try_lock_for(_500ms)) {
std::cout << "获得了锁" << std::endl;
} else {
std::cout << "未获得锁" << std::endl;
}
}
int main() {
std::timed_mutex mutex;
mutex.lock();
std::thread thread(run500ms, std::ref(mutex));
thread.join();
mutex.unlock();
return 0;
}
//输出:未获得锁
lock_guard、unique_lock、scope_lock、share_lock。
lock_guard:更加灵活的锁管理类模板,构造时是否加锁是可选的,在对象析构时如果持有锁会自动释放锁,所有权可以转移。对象生命期内允许手动加锁和释放锁。
unique_lock 和 lock_guard 一样,对 std::mutex 类型的互斥量的上锁和解锁进行管理,一样也不管理 std::mutex 类型的互斥量的声明周期。但是它的使用更加的灵活。
scope_lock:严格基于作用域(scope-based)的锁管理类模板,构造时是否加锁是可选的(不加锁时假定当前线程已经获得锁的所有权),析构时自动释放锁,所有权不可转移,对象生存期内不允许手动加锁和释放锁。
share_lock:用于管理可转移和共享所有权的互斥对象。
使用std::lock_guard类模板修改前面的代码,在lck对象构造时加锁,析构时自动释放锁,即使insert抛出了异常lck对象也会被正确的析构,所以也就不会发生互斥对象没有释放锁而导致死锁的问题。
std::set<int> int_set;
std::mutex mt;
auto f = [&int_set, &mt]() {
try {
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<> dis(1, 1000);
for(std::size_t i = 0; i != 100000; ++i) {
std::lock_guard<std::mutex> lck(mt);
int_set.insert(dis(gen));
}
} catch(...) {}
};
std::thread td1(f), td2(f);
td1.join();
td2.join();
互斥对象管理类模板的加锁策略
前面提到std::lock_guard、std::unique_lock和std::shared_lock类模板在构造时是否加锁是可选的,C++11提供了3种加锁策略。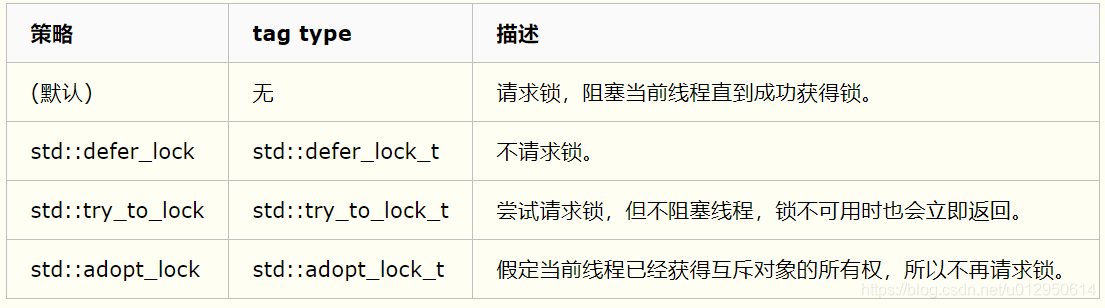
下表列出了互斥对象管理类模板对各策略的支持情况。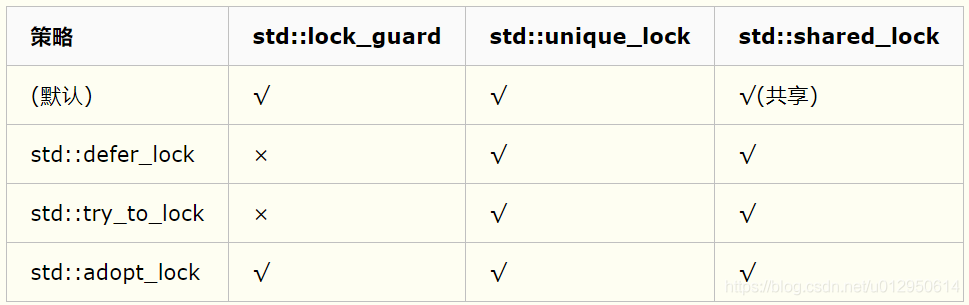
举例:
std::mutex mt;
std::unique_lock<std::mutex> lck(mt, std::defer_lock);
assert(lck.owns_lock() == false);
lck.lock();
assert(lck.owns_lock() == true);
死锁问题
在某些情况下我们可能需要对多个互斥对象进行加锁,考虑下面的代码
std::mutex mt1, mt2;
// thread 1
{
std::lock_guard<std::mutex> lck1(mt1);
std::lock_guard<std::mutex> lck2(mt2);
// do something
}
// thread 2
{
std::lock_guard<std::mutex> lck2(mt2);
std::lock_guard<std::mutex> lck1(mt1);
// do something
}
如果线程1执行到第5行的时候恰好线程2执行到第11行。那么就会出现
- 线程1持有mt1并等待mt2
- 线程2持有mt2并等待mt1
发生死锁。 为了避免发生这类死锁,对于任意两个互斥对象,在多个线程中进行加锁时应保证其先后顺序是一致。前面的代码应修改成
std::mutex mt1, mt2;
// thread 1
{
std::lock_guard<std::mutex> lck1(mt1);
std::lock_guard<std::mutex> lck2(mt2);
// do something
}
// thread 2
{
std::lock_guard<std::mutex> lck1(mt1);
std::lock_guard<std::mutex> lck2(mt2);
// do something
}
更好的做法是使用标准库中的std::lock和std::try_lock函数来对多个Lockable对象加锁。std::lock(或std::try_lock)会使用一种避免死锁的算法对多个待加锁对象进行lock操作(std::try_lock进行try_lock操作),当待加锁的对象中有不可用对象时会阻塞当前线程知道所有对象都可用(std::try_lock不会阻塞线程当有对象不可用时会释放已经加锁的其他对象并立即返回)。使用std::lock改写前面的代码,这里刻意让第6行和第13行的参数顺序不同
std::mutex mt1, mt2;
// thread 1
{
std::unique_lock<std::mutex> lck1(mt1, std::defer_lock);
std::unique_lock<std::mutex> lck2(mt2, std::defer_lock);
std::lock(lck1, lck2);
// do something
}
// thread 2
{
std::unique_lock<std::mutex> lck1(mt1, std::defer_lock);
std::unique_lock<std::mutex> lck2(mt2, std::defer_lock);
std::lock(lck2, lck1);
// do something
}
此外std::lock和std::try_lock还是异常安全的函数(要求待加锁的对象unlock操作不允许抛出异常),当对多个对象加锁时,其中如果有某个对象在lock或try_lock时抛出异常,std::lock或std::try_lock会捕获这个异常并将之前已经加锁的对象逐个执行unlock操作,然后重新抛出这个异常(异常中立)。并且std::lock_guard的构造函数lock_guard(mutex_type& m, std::adopt_lock_t t)也不会抛出异常。所以std::lock像下面这么用也是正确
std::lock(mt1, mt2);
std::lock_guard<std::mutex> lck1(mt1, std::adopt_lock);
std::lock_guard<std::mutex> lck2(mt2, std::adopt_lock);
原子操作 atomic
所谓的原子操作,取的就是“原子是最小的、不可分割的最小个体”的意义,它表示在多个线程访问同一个全局资源的时候,能够确保所有其他的线程都不在同一时间内访问相同的资源。也就是他确保了在同一时刻只有唯一的线程对这个资源进行访问。这有点类似互斥对象对共享资源的访问的保护,但是原子操作更加接近底层,因而效率更高。
使用方法和普通的变量使用方法相同,只是它的操作已经被封装成类似原子操作,虽然实际上是封装后的,不是真正内核意义上的原子操作,但是这也简化了编程。
原子变量类型
C++11下的用法:
头文件:#include<atomic>
std::atomic<int> count(0);//声明并初始化
原子变量类型如下图: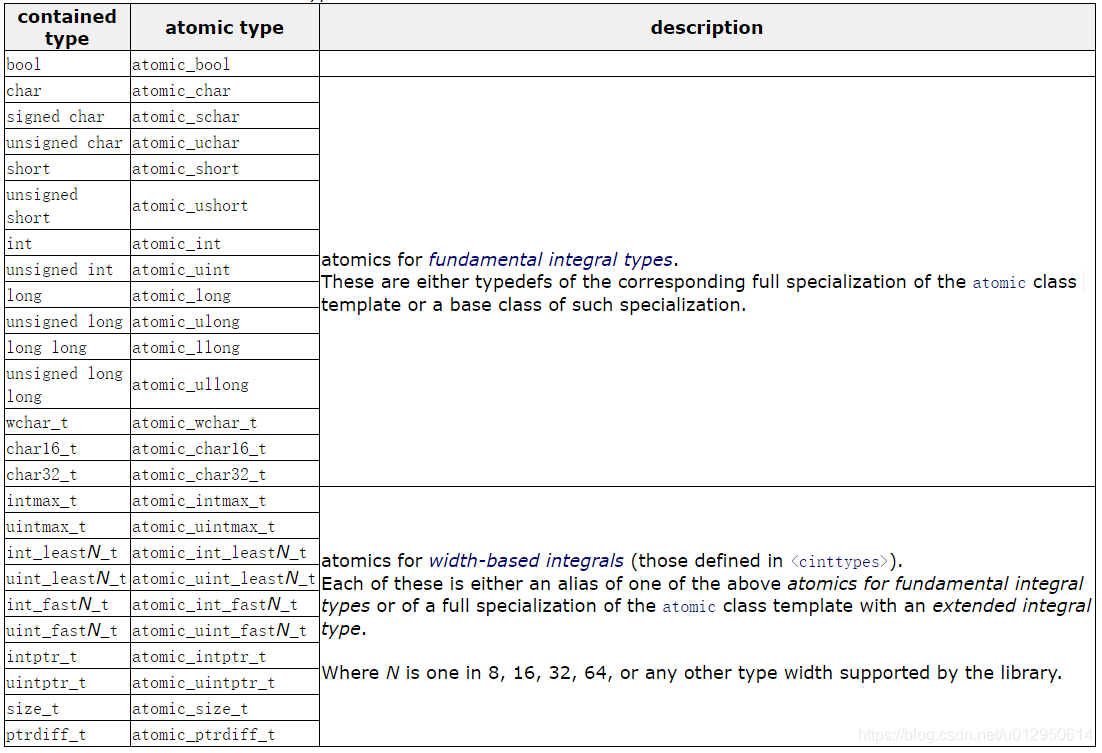
std::condition_variable
当 std::condition_variable 对象的某个 wait 函数被调用的时候,它使用 std::unique_lock(通过 std::mutex) 来锁住当前线程。当前线程会一直被阻塞,直到另外一个线程在相同的 std::condition_variable 对象上调用了 notification 函数来唤醒当前线程。
std::condition_variable::notify_one() :唤醒某个等待(wait)线程。如果当前没有等待线程,则该函数什么也不做,如果同时存在多个等待线程,则唤醒某个线程是不确定的(unspecified)。
std::condition_variable::notify_all() :唤醒所有的等待(wait)线程。如果当前没有等待线程,则该函数什么也不做。
std::condition_variable 对象通常使用 std::unique_lock<std::mutex> 来等待。
#include <iostream> // std::cout
#include <thread> // std::thread
#include <mutex> // std::mutex, std::unique_lock
#include <condition_variable> // std::condition_variable
std::mutex mtx; // 全局互斥锁.
std::condition_variable cv; // 全局条件变量.
bool ready = false; // 全局标志位.
void do_print_id(int id)
{
std::unique_lock <std::mutex> lck(mtx);
while (!ready) // 如果标志位不为 true, 则等待...
cv.wait(lck); // 当前线程被阻塞, 当全局标志位变为 true 之后,
// 线程被唤醒, 继续往下执行打印线程编号id.
std::cout << "thread " << id << '\n';
}
void go()
{
std::unique_lock <std::mutex> lck(mtx);
ready = true; // 设置全局标志位为 true.
cv.notify_all(); // 唤醒所有线程.
}
int main()
{
std::thread threads[10];
// spawn 10 threads:
for (int i = 0; i < 10; ++i)
threads[i] = std::thread(do_print_id, i);
std::cout << "10 threads ready to race...\n";
go(); // go!
for (auto & th:threads)
th.join();
return 0;
}
std::condition_variable_any
与 std::condition_variable 类似,只不过 std::condition_variable_any 的 wait 函数可以接受任何 lockable 参数,而 std::condition_variable 只能接受 std::unique_lock<std::mutex> 类型的参数,除此以外,和 std::condition_variable 几乎完全一样。
#include <iostream> // std::cout
#include <thread> // std::thread
#include <mutex> // std::mutex, std::unique_lock
#include <condition_variable> // std::condition_variable
std::mutex mtx;
std::condition_variable cv;
bool ready = false;
void print_id (int id) {
std::unique_lock<std::mutex> lck(mtx);
while (!ready) cv.wait(lck);
// ...
std::cout << "thread " << id << '\n';
}
void go() {
std::unique_lock<std::mutex> lck(mtx);
std::notify_all_at_thread_exit(cv,std::move(lck));
ready = true;
}
int main ()
{
std::thread threads[10];
// spawn 10 threads:
for (int i=0; i<10; ++i)
threads[i] = std::thread(print_id,i);
std::cout << "10 threads ready to race...\n";
std::thread(go).detach(); // go!
for (auto& th : threads) th.join();
return 0;
}
线程池
简介
线程池(thread pool):一种线程的使用模式,线程过多会带来调度开销,进而影响缓存局部性和整体性能。而线程池维护着多个线程,等待着监督管理者分配可并发执行的任务。这避免了在处理短时间任务时创建与销毁线程的代价。线程池不仅能够保证内核的充分利用,还能防止过分调度。可用线程数量应该取决于可用的并发处理器、处理器内核、内存、网络sockets等的数量。在程序启动时候,一次性创建好一定数量的线程。这样的代码更稳定。
线程池的组成
1、线程池管理器
创建一定数量的线程,启动线程,调配任务,管理着线程池。
本篇线程池目前只需要启动(start()),停止方法(stop()),及任务添加方法(addTask).
start()创建一定数量的线程池,进行线程循环.
stop()停止所有线程循环,回收所有资源.
addTask()添加任务.
2、工作线程
线程池中线程,在线程池中等待并执行分配的任务.
本篇选用条件变量实现等待与通知机制.
3、任务接口,
添加任务的接口,以供工作线程调度任务的执行。
4、任务队列
用于存放没有处理的任务。提供一种缓冲机制
同时任务队列具有调度功能,高优先级的任务放在任务队列前面;本篇选用priority_queue 与pair的结合用作任务优先队列的结构.
线程池工作的四种情况(假设我们的线程池大小为3,任务队列目前不做大小限制)
1、主程序当前没有任务要执行,线程池中的任务队列为空闲状态
此情况下所有工作线程处于空闲的等待状态,任务缓冲队列为空.
2、主程序添加小于等于线程池中线程数量的任务.
此情况基于情形1,所有工作线程已处在等待状态,主线程开始添加三个任务,添加后通知(notif())唤醒线程池中的线程开始取(take())任务执行. 此时的任务缓冲队列还是空。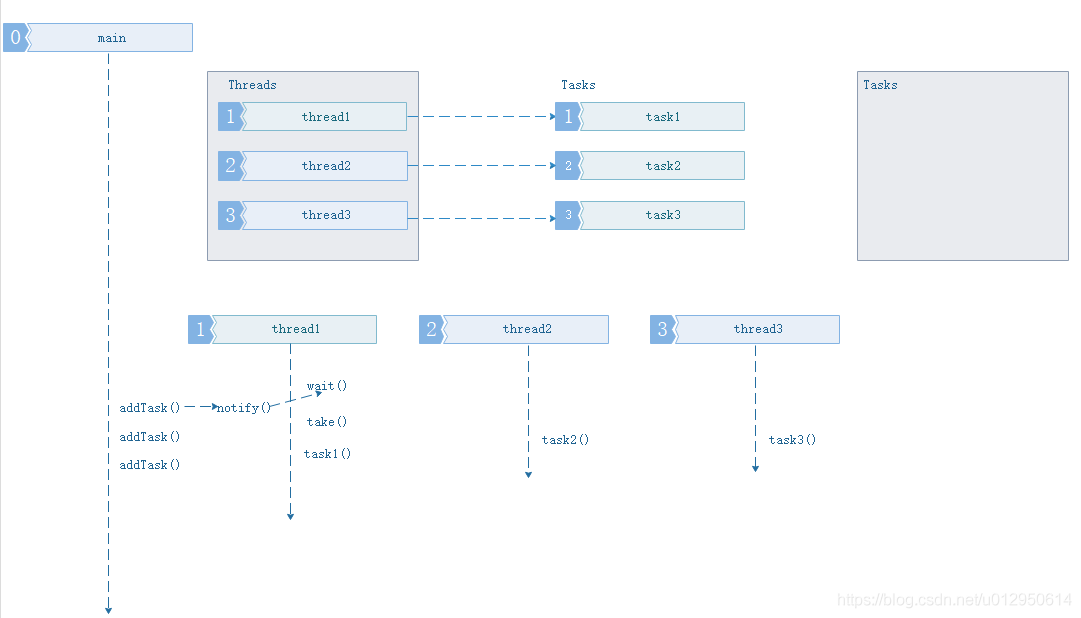 3、主程序添加任务数量大于当前线程池中线程数量的任务.
3、主程序添加任务数量大于当前线程池中线程数量的任务.
此情况发生情形2后面,所有工作线程都在工作中,主线程开始添加第四个任务,添加后发现现在线程池中的线程用完了,于是存入任务缓冲队列。工作线程空闲后主动从任务队列取任务执行.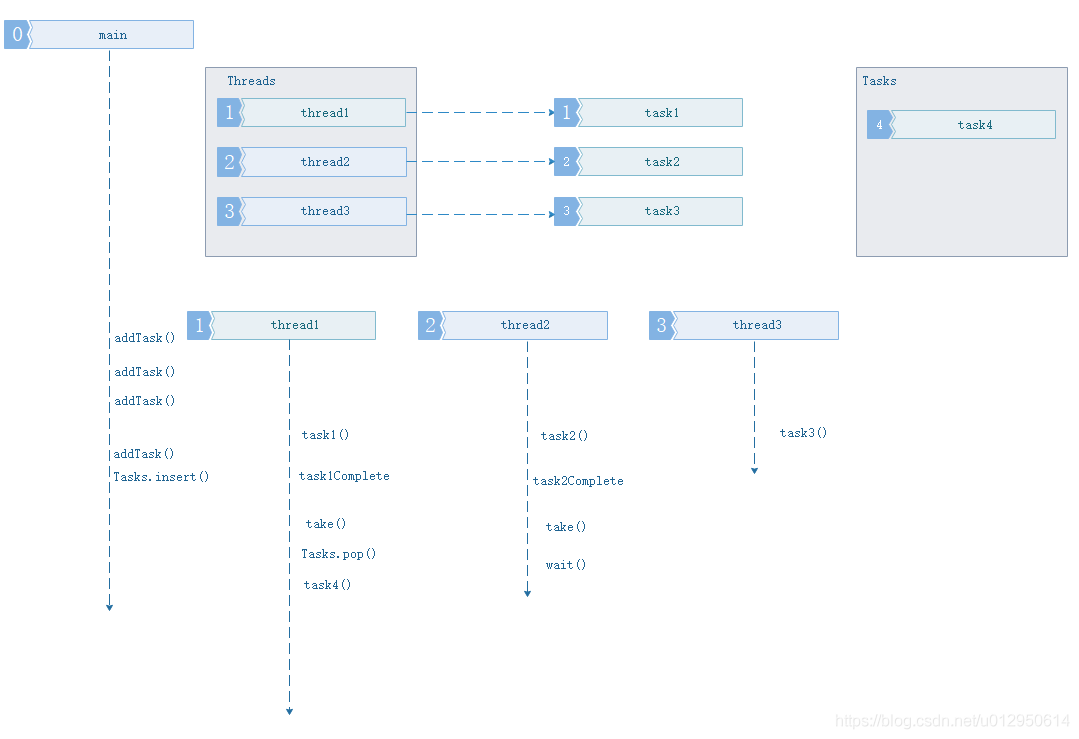
4、主程序添加任务数量大于当前线程池中线程数量的任务,且任务缓冲队列已满.
此情况发生情形3且设置了任务缓冲队列大小后面,主程序添加第N个任务,添加后发现池子中的线程用完了,任务缓冲队列也满了,于是进入等待状态、等待任务缓冲队列中的任务腾空通知。但是要注意这种情形会阻塞主线程,本篇暂不限制任务队列大小,必要时再来优化.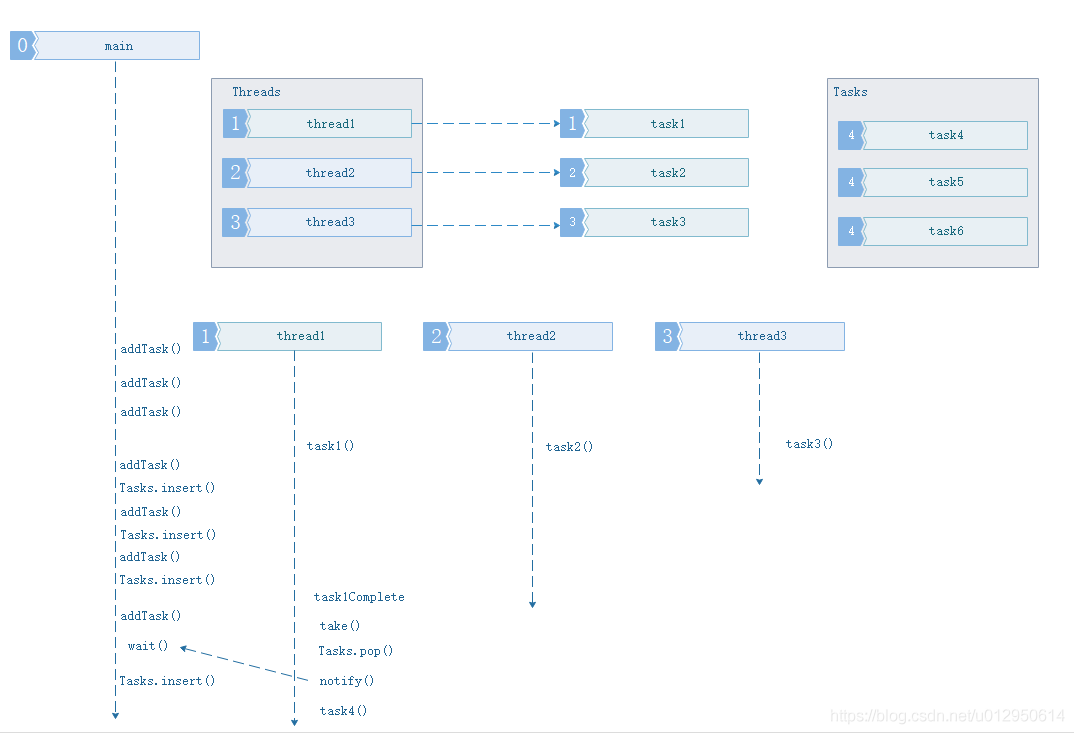
线程池实现
等待通知机制通过条件变量实现,Logger和CurrentThread,用于调试,可以无视.
#ifndef _THREADPOOL_HH
#define _THREADPOOL_HH
#include <vector>
#include <utility>
#include <queue>
#include <thread>
#include <functional>
#include <mutex>
#include "Condition.hh"
class ThreadPool{
public:
static const int kInitThreadsSize = 3;
enum taskPriorityE { level0, level1, level2, };
typedef std::function<void()> Task;
typedef std::pair<taskPriorityE, Task> TaskPair;
ThreadPool();
~ThreadPool();
void start();
void stop();
void addTask(const Task&);
void addTask(const TaskPair&);
private:
ThreadPool(const ThreadPool&);//禁止复制拷贝.
const ThreadPool& operator=(const ThreadPool&);
struct TaskPriorityCmp
{
bool operator()(const ThreadPool::TaskPair p1, const ThreadPool::TaskPair p2)
{
return p1.first > p2.first; //first的小值优先
}
};
void threadLoop();
Task take();
typedef std::vector<std::thread*> Threads;
typedef std::priority_queue<TaskPair, std::vector<TaskPair>, TaskPriorityCmp> Tasks;
Threads m_threads;
Tasks m_tasks;
std::mutex m_mutex;
Condition m_cond;
bool m_isStarted;
};
#endif
//Cpp
#include <assert.h>
#include "Logger.hh" // debug
#include "CurrentThread.hh" // debug
#include "ThreadPool.hh"
ThreadPool::ThreadPool()
:m_mutex(),
m_cond(m_mutex),
m_isStarted(false)
{
}
ThreadPool::~ThreadPool()
{
if(m_isStarted)
{
stop();
}
}
void ThreadPool::start()
{
assert(m_threads.empty());
m_isStarted = true;
m_threads.reserve(kInitThreadsSize);
for (int i = 0; i < kInitThreadsSize; ++i)
{
m_threads.push_back(new std::thread(std::bind(&ThreadPool::threadLoop, this)));
}
}
void ThreadPool::stop()
{
LOG_TRACE << "ThreadPool::stop() stop.";
{
std::unique_lock<std::mutex> lock(m_mutex);
m_isStarted = false;
m_cond.notifyAll();
LOG_TRACE << "ThreadPool::stop() notifyAll().";
}
for (Threads::iterator it = m_threads.begin(); it != m_threads.end() ; ++it)
{
(*it)->join();
delete *it;
}
m_threads.clear();
}
void ThreadPool::threadLoop()
{
LOG_TRACE << "ThreadPool::threadLoop() tid : " << CurrentThread::tid() << " start.";
while(m_isStarted)
{
Task task = take();
if(task)
{
task();
}
}
LOG_TRACE << "ThreadPool::threadLoop() tid : " << CurrentThread::tid() << " exit.";
}
void ThreadPool::addTask(const Task& task)
{
std::unique_lock<std::mutex> lock(m_mutex);
/*while(m_tasks.isFull())
{//when m_tasks have maxsize
cond2.wait();
}
*/
TaskPair taskPair(level2, task);
m_tasks.push(taskPair);
m_cond.notify();
}
void ThreadPool::addTask(const TaskPair& taskPair)
{
std::unique_lock<std::mutex> lock(m_mutex);
/*while(m_tasks.isFull())
{//when m_tasks have maxsize
cond2.wait();
}
*/
m_tasks.push(taskPair);
m_cond.notify();
}
ThreadPool::Task ThreadPool::take()
{
std::unique_lock<std::mutex> lock(m_mutex);
//always use a while-loop, due to spurious wakeup
while(m_tasks.empty() && m_isStarted)
{
LOG_TRACE << "ThreadPool::take() tid : " << CurrentThread::tid() << " wait.";
m_cond.wait(lock);
}
LOG_TRACE << "ThreadPool::take() tid : " << CurrentThread::tid() << " wakeup.";
Task task;
Tasks::size_type size = m_tasks.size();
if(!m_tasks.empty() && m_isStarted)
{
task = m_tasks.top().second;
m_tasks.pop();
assert(size - 1 == m_tasks.size());
/*if (TaskQueueSize_ > 0)
{
cond2.notify();
}*/
}
return task;
}
测试程序
int main()
{
{
ThreadPool threadPool;
threadPool.start();
getchar();
}
getchar();
return 0;
}
addTask()、PriorityTaskQueue
测试添加任务接口,及优先任务队列.
主线程首先添加了5个普通任务、 1s后添加一个高优先级任务,当前3个线程中的最先一个空闲后,会最先执行后面添加的priorityFunc().
std::mutex g_mutex;
void priorityFunc()
{
for (int i = 1; i < 4; ++i)
{
std::this_thread::sleep_for(std::chrono::seconds(1));
std::lock_guard<std::mutex> lock(g_mutex);
LOG_DEBUG << "priorityFunc() [" << i << "at thread [ " << CurrentThread::tid() << "] output";// << std::endl;
}
}
void testFunc()
{
// loop to print character after a random period of time
for (int i = 1; i < 4; ++i)
{
std::this_thread::sleep_for(std::chrono::seconds(1));
std::lock_guard<std::mutex> lock(g_mutex);
LOG_DEBUG << "testFunc() [" << i << "] at thread [ " << CurrentThread::tid() << "] output";// << std::endl;
}
}
int main()
{
ThreadPool threadPool;
threadPool.start();
for(int i = 0; i < 5 ; i++)
threadPool.addTask(testFunc);
std::this_thread::sleep_for(std::chrono::seconds(1));
threadPool.addTask(ThreadPool::TaskPair(ThreadPool::level0, priorityFunc));
getchar();
return 0;
}
参考
https://www.jianshu.com/p/5d273e4e3cbb.
https://www.cnblogs.com/lovebay/p/11582682.html
https://www.cnblogs.com/wangshaowei/p/9593201.html
https://www.cnblogs.com/defen/p/4409904.html
https://www.cnblogs.com/ailumiyana/p/10016965.html
C++ 11新特性