最近有个小项目需要打包为exe,然而当用scrapy框架编写的项目打包成exe,会出现各种错误,整得我是头晕目眩,反复查了网上的相关方法全部不管用,无奈之下只能自己苦心研究,终于修成正果,在这里给大家分享下。
我用的是auto-py-to-exe 打包的,针对于 本人的项目,其他方法无效,只有用auto-py-to-exe 打包才能成功,下面是我的环境参数:
python版本:python3.6.8
打包工具:auto-py-to-exe
解释器:py3.6.8 虚拟环境
pip install auto-py-to-exe
auto-py-to-exe #启动代码 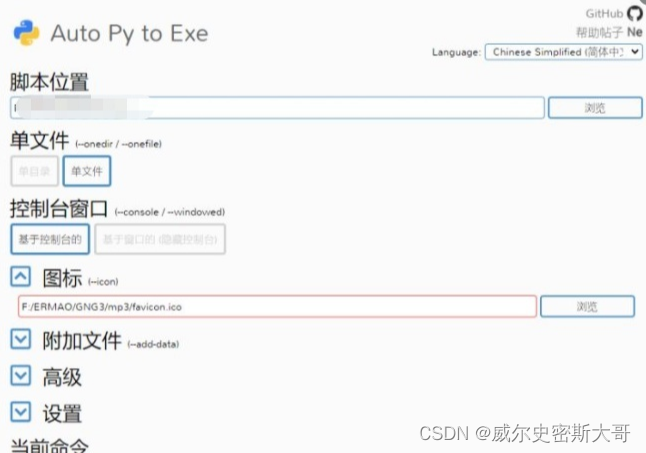
启动文件是核心问题:选择你的项目启动文件,但是启动文件要注意了,有两种代码格式。
方案一
# 方案一
# from scrapy.cmdline import execute
# if __name__ == '__main__':
# execute("scrapy crawl 爬虫名称".split())
#但是这种方式无法循环启动爬虫,如果有需要循环启动爬虫,可用方案二方案二:
# -*- coding: utf-8 -*-
from twisted.internet import reactor, defer
from scrapy.crawler import CrawlerRunner
import time
from scrapy.utils.project import get_project_settings
# CrawlerRunner获取settings.py 里的设置信息
runner = CrawlerRunner(get_project_settings())
def slepe_style(num):
#num = 50 # 设置倒计时时间
timeflush = 0.1 # 设置屏幕刷新的间隔时间
for i in range(0, int(num / timeflush) + 1):
print("\r系统正在重新启动:" + "|" + "*" * i + " " * (int(num / timeflush) + 1 - i) + "|" + str(i) + "%", end="")
time.sleep(timeflush)
print("\r重启完成!")
@defer.inlineCallbacks
def crawl():
while True:
# logging.info("new cycle starting")
yield runner.crawl("你的爬虫名称")
# 1s跑一次
slepe_style(10)
reactor.stop()
crawl()
reactor.run()剩下的就是导入你项目里用到的包了,在附加文件里选择路径,直接选择你虚拟环境里的包就可以,至于都需要导入什么包,你可以先打包然后把exe拖入dos运行就可以看到缺少什么包了,但是一定要注意一个细节,必须要把scrapy.cfg 和你新打包的exe放到同一个目录。还有一个要注意的地方,在附加文件里一定要把你当scrapy项目文件夹包含进去。
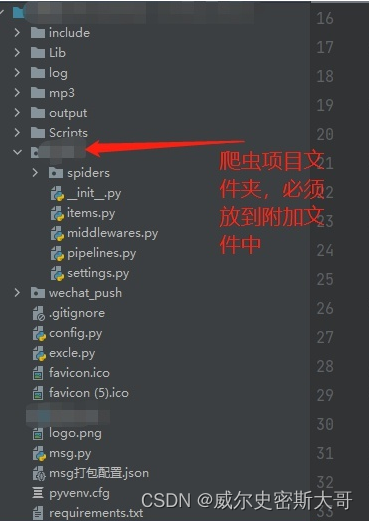
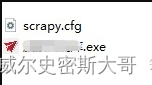
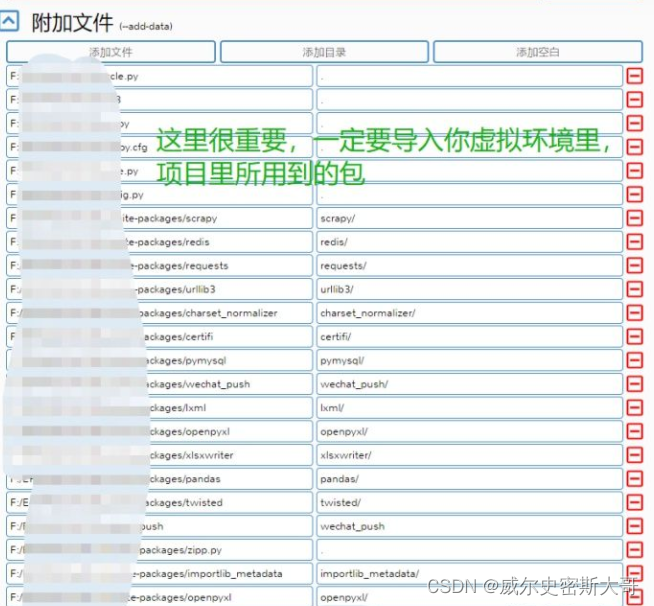
当配置好附加文件后,切记导出一个配置文件,因为你不确定是否还缺包,所以先导出配置以免下次打包的时候重复选择。
一直反复尝试,导入 你缺少的包就可以
版权声明:本文为qq_41438984原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。