若发现文章有误,敬请指出,感谢
一、运行环境
- Vmware
- CentOS 7 操作系统
- JDK 8
- MySQL8
- Hadoop3.3.0(单节点)
- HIve 3.1.2 on YARN
- Maven 3.8.4
- IDEA 2021.3 旗舰版
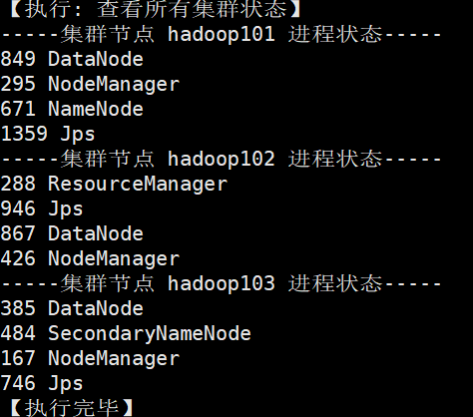
节点分配:
其中MySQL和Hive都安装在hadoop101节点
二、Hive的内置函数
官方参考文档:点击查看
Hive提供的函数主要分为三种,分别是 UDF、UDAF、UDTF,它们之间的比较如下表:
| 函数类型 | 全称 | 描述 | 范例 |
|---|---|---|---|
| UDF | User Defined Function | 一进一出 | floor()向下取整、ceil()向上取整… |
| UDAF | User Defined Aggregation Function | 多进一出 | min(col)取最小值、max(col)取最大值… |
| UDTF | User Defined Table-Generating Functions | 一进多出 | explode()炸裂函数,可遍历一个集合、数组等 |
如何自定义UDF、UDTF函数?(由于官方提供的UDAF函数十分丰富,所以一般不需要自定义)
步骤如下:
- 继承Hive提供的类
org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
org.apache.hadoop.hive.ql.udf.generic.GenericUDTF; - 实现要求实现的方法
- 打包成jar包提交到Hive所在的集群节点(如果在Hive根目录的lib文件夹下就无需手动导入,否则需要在Hive Shell里手动执行
add jar 文件位置,添加jar包 - 注册函数,使用
create temporary function 自定义函数名 as "实现类的包名加上类名";命令来完成自定义函数的注册 - 最后测试函数,可以使用实际表的数据,也可以直接用字符串或者变量来进行测试。
三、自定义UDF函数
官方参考文档:点击查看
3.1 编写代码实现自定义的Hive函数
pom.xml Maven 依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.uni</groupId>
<artifactId>project</artifactId>
<packaging>pom</packaging>
<version>1.0-SNAPSHOT</version>
<modules>
<module>hive-demo</module>
</modules>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<!-- 声明并引入,所有子模块都会自动引入该依赖 -->
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-common -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
</dependencies>
</project>
myUDF.java 实现代码
package com.uni.hive;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
/**
* Author: Unirithe
* Date: 2022/3/26
**/
public class myUDF extends GenericUDF {
// 校验数据参数个数
@Override
public ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {
if(objectInspectors.length != 1)
throw new UDFArgumentException("参数个数不为1");
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
// 处理数据
@Override
public Object evaluate(DeferredObject[] deferredObjects) throws HiveException {
// 1. 取出输入数据
String input = deferredObjects[0].get().toString();
// 2. 判断输入数据是否为NULL
if(input == null)
return 0;
else
return input.length();
}
@Override
public String getDisplayString(String[] strings) {
return "";
}
}
3.2 打包成jar包,发布到集群节点,进行测试
使用Maven进行打包,将jar包发布到Hive所在的集群节点Hive根目录下的lib文件夹里
若放在其他目录,则需在Hive Shell里手动导入jar包
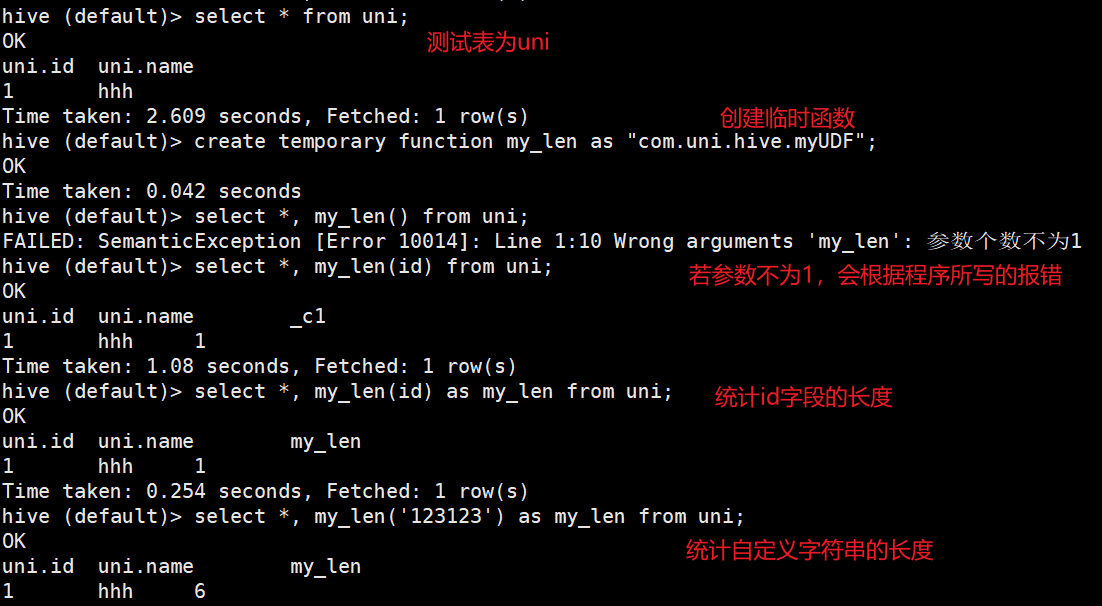
hive > add jar /opt/module/hive/data/hive-demo-1.0-SNAPSHOT.jar;
创建临时函数,将函数与自定义的类进行关联
hive > create temporary function my_len as "com.uni.hive.myUDF";
然后随便使用一张表(至少要有一行数据)进行测试
四、自定义UDTF函数
4.1 编写代码
pom.xml 引入Maven依赖
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
myUDTF.java
package com.uni.hive;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.util.ArrayList;
import java.util.List;
/**
* 输入数据: hello,uni,hive
* 输出数据:
* hello
* uni
* hive
* Author: Unirithe
* Date: 2022/3/26
**/
public class myUDTF extends GenericUDTF {
private ArrayList<String> outList = new ArrayList<>();
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
// 输出数据的默认列名,可以被别名覆盖
List<String> fieldNames = new ArrayList<>();
// 输出数据的类型
List<ObjectInspector> fieldOIs = new ArrayList<>();
// 设置别名
fieldNames.add("TheWord");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
// 最终返回值
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
// 处理输入数据 hello,uni,hive
@Override
public void process(Object[] args) throws HiveException {
// 1. 取出输入数据
String input = args[0].toString();
// 2. 获取分隔符
String splitKey = args[1].toString();
// 2. 按照 "," 分割字符串
String[] fields = input.split(splitKey);
// 3.遍历数据写出
for (String field : fields) {
// 清空集合
outList.clear();
// 将数据放入集合
outList.add(field);
// 输出数据
forward(outList);
}
}
// 收尾方法
@Override
public void close() throws HiveException {
}
}
4.2 测试
将上面的程序打包后发到Hive所在的集群节点,移动到hive根目录下的lib文件夹即可
插入测试数据
hive > create table testudtf(words string);
hive > insert into testudtf values('hello,uni,hive'), ('hi,hadoop');
hive > select * from testudtf;
创建函数
hive > create temporary function my_explode as "com.uni.hive.myUDTF";
测试程序效果
hive > select my_explode(words, ',') from testudtf;
运行结果:
theword
hello
uni
hive
hi
hadoop
除了使用结构表测试,还可以直接使用字符串测试
hive > select my_explode('hi-hadoop-do-you-like-sleep', '-');
运行结果:
theword
hi
hadoop
do
you
like
sleep
参 考 资 料
版权声明:本文为Unirithe原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。