调优思路
对查询进行缓存
强制限制 MySQL 资源设置
关键字缓冲区
调优思路
1. 硬件优化
2. 数据库设计与规划--以后再修改很麻烦,估计数据量,使用什么存储引擎
3. 数据的应用--怎样取数据,SQL语句的优化
4. 磁盘 IO优化
5. 操作系统的优化--内核、TCP连接数量
6. MySQL服务优化--内存的使用,磁盘的使用
7. my.cnf 内参数的优化
8. 分库分表思路和优劣
硬件优化
CPU—— 64 位、高主频、高缓存,高并行处理能力
内存——大内存、主频高,尽量不要用 SWAP
硬盘——15000转、RAID5、raid10 。 SSD
网络——标配的千兆网卡,10G网卡,bond0,MySQL服务器尽可能和使用它的web服务器在同一局域网内,尽量避
免诸如防火墙策略等不必要的开销
数据库设计与规划(架构上的优化)
纵向拆解: 专机专用
现在公司一台服务器同时负责 web、ftp、数据库等多个角色。 R720 dell 内存 :768G
纵向拆解后就是:数据库服务器专机专用,避免额外的服务可能导致的性能下降和不稳定性。
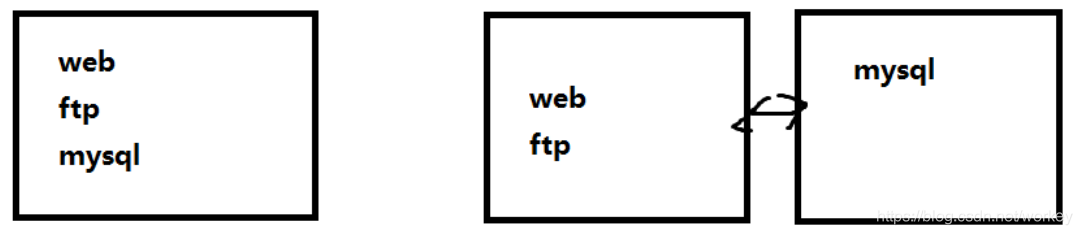
横向拆解: 主从同步、负载均衡、高可用性集群,当单个 MySQL 数据库无法满足日益增加的需求时,可以考虑在数据
库这个逻辑层面增加多台服务器,以达到稳定、高效的效果。
查询优化
1. 建表时表结构要合理,每个表不宜过大;在任何情况下均应使用最精确的类型。例如,如果ID列用int是一个好主意,
而用text类型则是个蠢办法;TIME列酌情使用DATE或者DATETIME。
2. 索引,建立合适的索引。
3. 查询时尽量减少逻辑运算(与运算、或运算、大于小于某值的运算);
4. 减少不当的查询语句,不要查询应用中不需要的列,比如说 select * from 等操作。
5. 减小事务包的大小;
6. 将多个小的查询适当合并成一个大的查询,减少每次建立/关闭查询时的开销;
7. 将某些过于复杂的查询拆解成多个小查询,和上一条恰好相反
8. 建立和优化存储过程来代替大量的外部程序交互。
磁盘 IO 规划,IO 相关的技术
15000转、RAID5、raid10 。 SSD
swap 分区:最好使用 raid0 或 SSD
磁盘分区:将数据库目录放到一个分区上或一个磁盘上的物理分区. 存储数据的硬盘或分区和系统所在的硬盘分开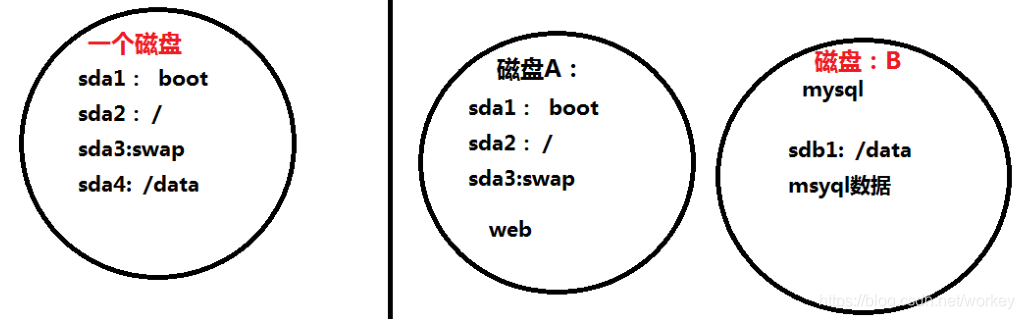
设置主从时,由于binlog日志频繁记录操作,开销非常大,需要把binlog日志放到其它硬盘分区上:
vim /etc/my.cnf
[mysqld]
datadir=/data/ #放在独立的硬盘上 SSD
socket=/var/lib/mysql/mysql.sock
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0 #在原配置文件中,添加以下内容:
log-bin=/data/mysqllog #启用二进制日志,默认存在/var/lib/mysql 下面
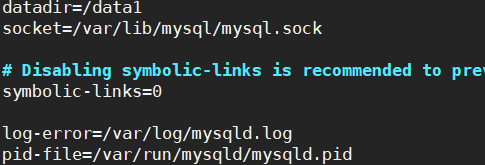
这里datadir=/data/设置先后顺序有问题就会一直报错。摸索出来的顺序是,刚装完mysql之后,密码还都没有设置的时候,直接改这个/etc/my.cnf的配置,然后重启,在继续进行其他的操作。
如果改了密码或者做了其它操作的话 要cp -a 把源目录复制到新目录给权限
操作系统的优化
网卡 bonding 技术
设置TCP连接数量限制,优化系统打开文件的最大限制。
使用64位操作系统,64位系统可以分给单个进程更多的内存,计算更快 。
禁用不必要启动的服务
文件系统调优,给数据仓库一个单独的文件系统,推荐使用XFS,一般效率更高、更可靠。
ext3 不错。 ext4 只是一个过渡的文件系统。
可以考虑在挂载分区时启用 noatime 选项。 #不记录访问时间
最小化原则:
1) 安装系统最小化。
2) 开启程序服务最小化原则。 #比方说就跑数据库,那别的服务都停了就完了
3) 操作最小化原则。#比方说差某字段,就只查询某个字段
4) 登录最小化原则。#不要登录过多客户端
5) 权限最小化。#没必要的权限不要给任何人,他能做什么就只能做什么,他能查询,就只能做查询,不嫩过插入更新删除操作。
blkid
/dev/sda1: UUID="66f9258a-3508-4b19-89b0-aef32f608604" TYPE="xfs"
/dev/sda2: UUID="c5f23f48-28fc-4e14-8c4a-fdd453832c76" TYPE="swap"
/dev/sda3: UUID="1f7f435e-7480-4a62-8f98-808fbf2d389c" TYPE="xfs"
/dev/sdb1: UUID="ad959e1b-f05a-422f-8392-39e90253a7d8" TYPE="xfs"
/dev/sr0: UUID="2017-09-06-10-53-42-00" LABEL="CentOS 7 x86_64" TYPE="iso9660" PTTYPE="dos"
vim /etc/fstab #在挂载项中添加noatime选项就可以了。
UUID=ad959e1b-f05a-422f-8392-39e90253a7d8 /date xfs defaults,noatime0 0
mount #查看添加前 mount 挂载选项
/dev/sdb1 on /date type xfs (rw,relatime,attr2,inode64,noquota)
mount -o remount /dev/sdb1 #使设置立即生效
mount #查看添加后 mount 挂载选项
/dev/sdb1 on /date type xfs (rw,noatime,attr2,inode64,noquota)
MySQL服务优化(数据库服务的优化)
保持每个表都不要太大,可以对大表做横切和纵切:比如说我要取得某 ID 的 lastlogin,完全可以做一张只有“ID“和
“lastlog”的小表,而非几十、几百列数据的并排大表。另外对一个有 1000 万条记录的表做更新比对 10 个 100 万记录的表做更新一般来的要慢。
存储引擎:
myisam 引擎,表级锁,表级锁开销小,影响范围大,适合读多写少的表,不支持事务。 表锁定不存在死锁 (也有例外)
innodb 引擎,行级锁,锁定行的开销要比锁定全表要大。影响范围小,适合写操作比较频繁的数据表。行级锁可能存在死锁。
MySQL的锁机制比较简单,其最显著的特点是不同的存储引擎支持不同的锁机制。
详解死锁https://www.douban.com/note/344647957/?type=like
http://www.jb51.net/article/100689.htm
之所以出现死锁,是因为多线程对资源的强占,你要我的,我也要你的,两人堵在路上谁都不让,所以死锁了。
#开启后会将所有的死锁记录到 error_log 中 错误日志在 my.cnf 配置为
log-error=/var/log/mysqld.log
innodb_print_all_deadlocks = 1
innodb_sort_buffer_size = 16M #排序缓冲 ,可加可不加,就是读取数据比较多,可以缓存一部分数据到内存中,整个表读完后,显示结果。
systemctl restart mysqld
mysql -uroot -p123456
show variables like "%deadlocks%";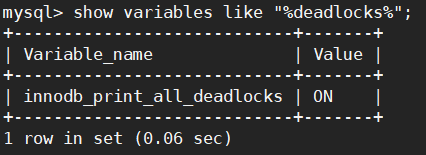
已经开启了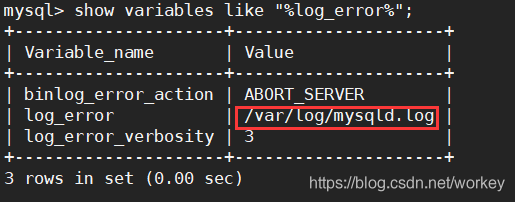
查看错误日志位置
show warnings; 查看警告信息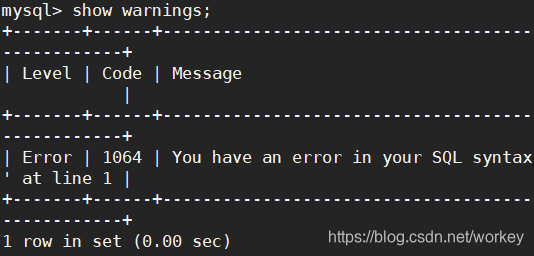
show processlist ; #显示MySQL系统中正在运行的所有线程,可以看到每个客户端正在执行的命令。
#本语句 TCP/IP 连接的主机名称(采用 host_name:client_port 格式),以方便地判定哪个客户端正在做什么。
启用 mysql 慢查询:---分析 sql 语句,找到影响效率的 SQL
vim /etc/my.cnf
[mysqld]
slow_query_log = 1 #开启慢查询日志
slow-query-log-file=/var/lib/mysql/slow.log #这个路径对 MySQL 用户具有可写权限
long_query_time = 5 #查询超过 5 秒钟的语句记录下来
log-queries-not-using-indexes = 1 #没有使用索引的查询
这 三 个 设 置 一 起 使 用 , 可 以 记 录 执 行 时 间 超 过 5 秒 和 没 有 使 用 索 引 的 查 询 。 请 注 意 有 关
log-queries-not-using-indexes 的警告。慢速查询日志都保存在/var/lib/mysql/slow.log。
systemctl restart mysqld
[root@xuegod63 ~]# mysql -u root -p123456
mysql> create database db;
mysql> use db;
mysql> create table test(id int (20),name char(40));
mysql> insert into test values(1,'kill');
mysql> select * from test;
[root@centos-60 ~]# cat /var/lib/mysql/slow.log
日期不正确,日志时间戳默认为UTC,因此会造成与系统时间不一致,与北京时间相差8个小时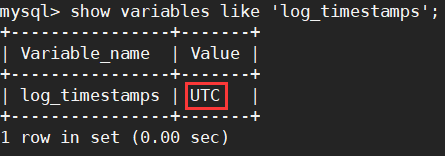
vim /etc/my.cnf
log_timestamps=system
systemctl restart mysqld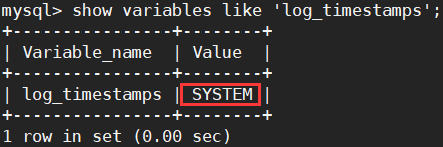
[root@centos-60 ~]# cat /var/lib/mysql/slow.log
与当前系统时间一致.没有使用索引的查询都被记录下来了,以及查询记录超过5秒的的sql语句。
my.cnf 内参数的优化
优化总原则:给 MySQL的资源太少,则 MySQL施展不开:给 MySQL的资源太多,可能会拖累整个 OS。
40%资源给 OS, 60%-70% 给 MySQL(内存和 CPU)
对查询进行缓存
PHP发出查询请求->数据库收到指令对查询语句进行分析->确定如何查询->从磁盘中加载信息->返回结果
如果反复查询,就反复执行这些。MySQL 有一个特性称为查询缓存,他可以将查询的结果保存在内存中,在很多情况
下,这会极大地提高性能。不过,问题是查询缓存在默认情况下是禁用的。
启动查询缓存:
vim /etc/my.cnf
[mysqld] #在此字段中添加
query_cache_size = 32M
至少 4M 以存储数据结构,可扩展。整体 100G,若此服务器只运行 MySQL 服务器。70-80G 给 mysql
systemctl restart mysqld.
mysql -u root -p123456
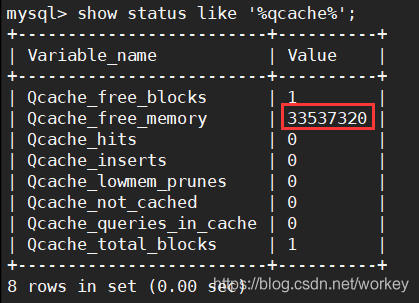
show status like '%qcache%';
Qcache_free_memory,剩余内存大小,还剩多大空间,是否需要增加,还是设置太大了用不完。
Qcache_free_blocks,如果该值非常大,则表明缓冲区中碎片很多。
Qcache_hits ,多少次命中。通过这个参数我们可以查看到Query Cache 的基本效果;值非常大,则表明查询缓冲使用非常频繁,如果该值较小反而会影响效率,那么可以考虑不用查询缓冲;
Qcache_lowmem_prunes,值非常大,则表明经常出现缓冲不够的情况;
Qcache_inserts,多少次未命中然后插入。通过“Qcache_hits”和“Qcache_inserts”两个参数我们就可以算出Query Cache 的命中率了
Qcache_lowmem_prunes,多少条Query 因为内存不足而被清除出Query Cache。通过“Qcache_lowmem_prunes”和“Qcache_free_memory”相互结合,能够更清楚的了解到我们系统中Query Cache 的内存大小是否真的足够,是否非常频繁的出现因为内存不足而有Query 被换出
Qcache_not_cached,因为query_cache_type 的设置或者不能被cache 的Query 的数量;
Qcache_queries_in_cache,当前Query Cache 中cache 的Query 数量;
Qcache_total_blocks,当前Query Cache 中的block 数量;
Qcache_free_blocks | 缓存中相邻内存块的个数。数目大说明可能有碎片。FLUSH QUERY CACHE 会对缓存中的碎片进行整理,从而得到一个空闲块。 |
Qcache_free_memory | 缓存中的空闲内存。 |
Qcache_hits | 每次查询在缓存中命中时就增大。 |
Qcache_inserts | 每次插入一个查询时就增大。命中次数除以插入次数就是不中比率;用 1 减去这个值就是命中率。 |
Qcache_lowmem_prunes | 缓存出现内存不足并且必须要进行清理以便为更多查询提供空间的次数。这个数字最好长时间来看;如果这个数字在不断增长,就表示可能碎片非常严重,或者内存很少。(上面的 free_blocks 和 free_memory 可以告诉您属于哪种情况)。 |
Qcache_not_cached | 不适合进行缓存的查询的数量,通常是由于这些查询不是 SELECT 语句。 |
Qcache_queries_in_cache | 当前缓存的查询(和响应)的数量。 |
Qcache_total_blocks | 缓存中块的数量。 |
show variables like '%query_cache%';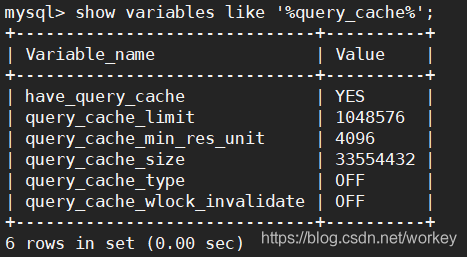
如果Qcache_free_blocks值过大,可能是query_cache_min_res_unit值过大,应该调小些
query_cache_min_res_unit的估计值:(query_cache_size - Qcache_free_memory) / Qcache_queries_in_cache
使用flush query cache,可以消除碎片
查询缓存命中率的计算公式是:Qcache_hits/(Qcache_hits + Com_select)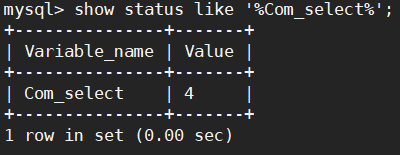
监控缓存命中率
通过Nagios+pnp4nagios来监控缓存命中率,并通过图表来展示。
监控脚本: check_mysql_qch.sh.sh
#!/bin/bash
#function:查询缓存命中率
#time:20121130
#author:system group
while getopts ":w:c:h" optname
do
case "$optname" in
"w")
WARN=$OPTARG
;;
"c")
CIRT=$OPTARG
;;
"h")
echo "Useage: check_mysql_qch.sh -w warn -c cirt"
exit
;;
"?")
echo "Unknown option $OPTARG"
exit
;;
":")
echo "No argument value for option $OPTARG"
exit
;;
*)
# Should not occur
echo "Unknown error while processing options"
exit
;;
esac
done
[ $? -ne 0 ] && echo "error: Unknown option " && exit
[ -z $WARN ] && WARN=60
[ -z $CIRT ] && CIRT=50
export selete=`/usr/local/mysql/bin/mysql -h 127.0.0.1 -uroot -Bse "SHOW GLOBAL STATUS LIKE 'Com_select';" |awk '{print $2}'`
export hits=`/usr/local/mysql/bin/mysql -h 127.0.0.1 -uroot -Bse "SHOW GLOBAL STATUS LIKE 'Qcache_hits';" |awk '{print $2}'`
a=$(($selete+$hits))
#rw_ratio=$(($a/$b))
#echo "rw_ratio=$rw_ratio"
#ratio=$(($rw_ratio*100))
#echo "ratio=$ratio"
if [ $a -ne "0" ];then
percent=`awk 'BEGIN{printf "%.2f%\n",('$hits'/'$a')*100}'`
Qch=`awk 'BEGIN{printf ('$hits'/'$a')*100}'`
fi
C=`echo "$Qch < $CIRT" | bc`
W=`echo "$Qch < $WARN" | bc`
O=`echo "$Qch > $WARN" | bc`
if [ $C == 1 ];then
echo -e "CIRT - Mysql Qcache Hits is $percent,Com_select is $selete,Qcache_hits is $hits|Qcache_hits=${Qch}%;${selete};${hits};0"
exit 2
fi
if [ $W == 1 ];then
echo -e "WARN - Mysql Qcache Hits is $percent,Com_select is $selete,Qcache_hits is $hits|Qcache_hits=${Qch}%;${selete};${hits};0"
exit 1
fi
if [ $O == 1 ];then
echo -e "OK - Mysql Qcache Hits is $percent,Com_select is $selete,Qcache_hits is $hits|Qcache_hits=${Qch}%;${selete};${hits};0"
exit 0
fi
生成报表
Pnp4nagios templates:check_mysql_qch.php
<?php
#
# Copyright (c) 2006-2010 system (http://www.cnfol.com)
# Plugin: check_mysql_qch
#
$opt[1] = "--vertical-label hits/s -l0 --title \"Mysql Qcache Hits for $hostname / $servicedesc\" ";
#
#
#
$def[1] = rrd::def("var1", $RRDFILE[1], $DS[1], "AVERAGE");
if ($WARN[1] != "") {
$def[1] .= "HRULE:$WARN[1]#FFFF00 ";
}
if ($CRIT[1] != "") {
$def[1] .= "HRULE:$CRIT[1]#FF0000 ";
}
$def[1] .= rrd::area("var1", "#0000FF", "Mysql Qcache Hits percent") ;
$def[1] .= rrd::gprint("var1", array("LAST", "AVERAGE", "MAX"), "%6.2lf");
?>强制限制 mysql 资源设置
mysqld中强制一些限制来确保系统负载不会导致资源耗尽的情况出现
vim /etc/my.cnf
[mysqld]
query_cache_size = 32M
max_connections = 500 #整个服务器最大连接数,上限是看硬件配置,该参数设置过小的最明显特征是出现“Too many connections”错误;MySQL的最大连接数是2000,比较理想的设置是max_used_connections/max_connections*100%≈85%
最大连接数占上限连接数的85%左右,如果发现比例在10%以下,MySQL服务器连接数上限设置的过高了。
max_user_connections = 0 # 0代表不限制,这个选项是一个用户最大链接数。
wait_timeout = 10 #mysqld将终止等待时间(空闲时间)超过10秒的连接,在LAMP应用程序中,连接数据库的时间通常就是Web
服务器处理请求所花费的时间。有时候如果负载过重,连接会挂起,并且会占用连接表空间。如果有多个交互用户使用了到
数据库的持久连接,那么应该将这个值设低一点。
max_connect_errors = 100 #如果一个主机在连接到服务器时有问题,并重试很多次后放弃,那么这个主机就会被锁定,直到执行:mysql> FLUSH HOSTS;之后才能运行。默认情况下,10 次失败就足以导致锁定了。将这个值修改为 100 会给服务器足够的时间来从问题中恢复。如果重试 100 次都无法建立连接,那么使用再高的值也不会有太多帮助,可能它根本就无法连接。
show status like 'max_used_connections';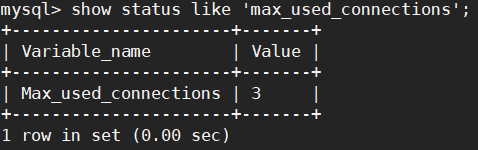
表高速缓存
数据库中的每个表存储在一个文件中,要读取文件的内容,你必须先打开文件,然后再读取。为了加快从文件中读取数
据的过程,mysqld 对这些打开文件进行了缓存,其最大数目由 /etc/my.cnf 中的 table_cache 指定
vim /etc/my.cnf
table_open_cache=2048
systemctl restart mysqld
mysql -u root -p123456
mysql> show global status like 'open%_tables';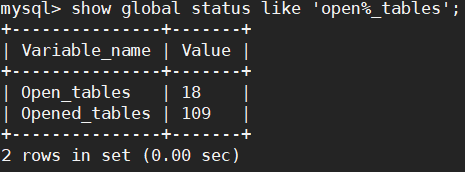
Open_tables 打开后在缓存中的表数量
Opened_tables 表示打开过的表数量,如果 Opened_tables 数量过大,说明配置中 table_open_cache值可能太小.
table_open_cache的值在 2G 内存以下的机器中的值默认从 256 到 512 个。对于有 1G 内存的机器,推荐值是 128-256。set global table_open_cache = 2048; (立即生效重启后失效)
通过以上两个值来判断 table_open_cache 是否到达瓶颈
当缓存中的值open_tables 临近到了 table_open_cache 值的时候
说明表缓存池快要满了 但 Opened_tables 还在一直有新的增长 这说明你还有很多未被缓存的表
这时可以适当增加 table_open_cache 的大小
关键字缓冲区
key_buffer_size 指定索引缓冲区的大小,它决定索引处理的速度,尤其是索引读的速度。
vim /etc/my.cnf
key_buffer_size = 512M
只跑一个MySQL服务。结合所有缓存,MySQL整体使用的缓存可以使用物理内存的80%
systemctl restart mysqld
show status like '%key_read%';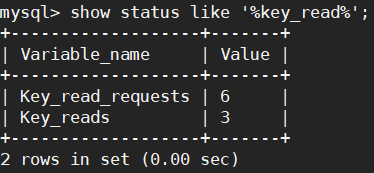
Key_reads 代表命中磁盘的请求个数
Key_read_requests 是总数
Key_reads 除以Key_read_requests等于不中比率,Key_reads/Key_read_requests ≈ 0.1%以下比较好
命中率:(1-(Key_reads / Key_read_requests ) )*100
key_reads :key_read_requests应该尽可能的比例为1:1000更好
如果每 1,000 个请求中命中磁盘的数目超过 1 个,就应该考虑增大关键字缓冲区了。
对于1G内存的机器,如果不使用MyISAM表,推荐值是16M(8-64M)
建议key_buffer设置为物理内存的1/4(针对MyISAM引擎),甚至是物理内存的30%~40%,如果key_buffer_size设置太大,系统就会频繁的换页,降低系统性能。因为MySQL使用操作系统的缓存来缓存数据,所以我们得为系统留够足够的内存;在很多情况下数据要比索引大得多。如果机器性能优越,可以设置多个key_buffer,分别让不同的key_buffer来缓存专门的索引
总结:
1、看机器配置,指三大件:cpu、内存、硬盘
2、看MySQL配置参数
3、查看MySQL行状态
4、查看MySQL的慢查询
依次解决了以上问题之后,再来查找程序方面的问题
vim /etc/my.cnf #加入skip-name-resolve
该选项就能禁用 DNS 解析,连接速度会快很多。不过,这样的话就不能在 MySQL 的授权表中使用主机名了而只能用
IP 格式。
#索引缓存,根据内存大小而定,如果是独立的 DB 服务器,可以设置高达 80%的内存总量
key_buffer_size = 512M
#打开表缓存总个数,可以避免频繁的打开数据表产生的开销
table_open_cache = 20
query_cache_size = 128M
max_connections =10000 #最大连接数 内存
#设置超时时间,能避免长连接
wait_timeout = 60
#记录慢查询,然后对慢查询一一优化单位:秒
slow-queries- log-file = /var/lib/mysql/slow.log
long_query_time = 5
提升性能的建议:
https://dev.mysql.com/doc/refman/5.7/en/server-system-variables.html 变量官方查询地址
1.如果opened_tables太大,应该把my.cnf中的table_cache变大
2.如果Key_reads太大,则应该把my.cnf中key_buffer_size变大.可以用Key_reads/Key_read_requests计算出cache失败率
3.如果Handler_read_rnd太大,则你写的SQL语句里很多查询都是要扫描整个表,而没有发挥键的作用
4.如果Threads_created太大,就要增加my.cnf中thread_cache_size的值.可以用Threads_created/Connections计算cache命中率
5.如果Created_tmp_disk_tables太大,就要增加my.cnf中tmp_table_size的值,用基于内存的临时表代替基于磁盘的