功能:
可以用来处理行和列组成的文本数据。可称之为一种编程语言,因为它支持正则表达式匹配,流程控制,变量,函数运算符等。
格式:
如果该条记录符合匹配模式便执行后续定义的动作命令
awk '匹配模式 {动作命令}' 文本文件#左大括号必须和匹配模式为同一行
工作流程:
首先从指定文本中读取文本,然后更新awk的内置系统变量的值(列数变量NF,行数变量NR,行变量$0,列变量$n等),接着一次执行定义的匹配模式和动作命令,最后读取后续文本反复执行。注意的一点是读取文本是一行一行读取的,但是处理是却是以一条记录为单位处理的,默认是一条记录为一行文本,也可以更改记录分隔符RS来更改。
执行方式:
方式1:通过命令行执行
awk '匹配模式 {动作命令}' 文本文件#左大括号必须和匹配模式为同一行
方式2:通过awk脚本执行
awk -f awk脚本 文本文件
awk脚本内容:注意不能含有出awk语句之外的其他语句
匹配模式 {动作命令}
匹配模式 {动作命令}
...
方式3:通过可执行文件执行
chmod +x 可执行文件
./可执行文件 文本文件
可执行文件内容:要定义执行的解释器;另外在解释器后加一个-f参数
#!/bin/awk -f
匹配模式 {动作命令}
匹配模式 {动作命令}
...
awk匹配模式:
scores.txt内容如下:
1、关系表达式:
通过大于>、小于<或等于==等关系运算符。当文本行满足关系表达式时,执行相应的动作命令
awk '$3>80 { print }' scores.txt
结果:第三列的值大于80时,执行打印操作。匹配模式是$3>80,即第三列的值大于80;动作命令是print,即打印。
2、正则表达式:
格式:/正则表达式/ 。要用双斜线包住
awk '/.*u\t/ {print}' scores.txt
结果:将含有字符u制表符的行打印
3、区间模式:
格式:匹配模式1,匹配模式2。通过区间模式可以匹配一段连续的文本行。
awk '/^l/,$2==81 {print}' scores.txt
结果:将以字符l开头的行,到第二列等于81的行之间的行,内容打印
4、混合模式:
格式:匹配模式1 逻辑运算符 匹配模式2。通过逻辑与&&、逻辑或||、逻辑非!将两个匹配模式组合起来
awk '/a/ && $4<80 {print}' scores.txt
结果:将含有字符a,并且第四列的值小于80的行打印![]()
BEGIN模式:
该模式指的是在awk程序方式开始执行时,在读取数据之前,所以该模式对应的动作命令只会被执行一次。一般用于自定义列分隔符、行分隔符、以及初始化变量。另外因为执行时间是读取数据之前,如果awk只有BEGIN模式,可以不指定文本文件
awk 'BEGIN {print "Hello World"}; {print}' scores.txt
结果:两个awk命令用分号隔开。第一个是在读取数据之前输出hello world ;另一个是输出,并没有指定匹配模式,即默认为所有行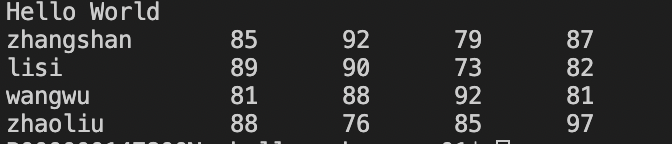
END模式:
该模式指的是在awk程序处理完所有数据后,即将退出程序时。该模式所对应的动作命令只会被执行一次。一般用于善后操作
awk '{print}; END {print "This is end"}' scores.txt
结果:打印所有行,并在最后输出This is end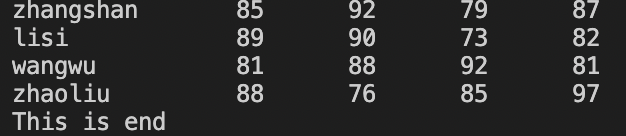
变量:
1、定义和引用:
格式:变量名=变量值。无需指定类型。变量名只能包括字母、数字和下划线,并且不能以数字开头。变量名区分大小写。
awk -f test.awk scores.txt
test.awk内容:
BEGIN {
x=3
string="Hello world"
print x
print string
}
结果:因为awk只有BEGIN模式,也可以不指定文本文件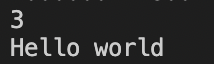
2、内置变量
| 变量 | 含义 |
|---|---|
| $0 | 当前正在处理的记录 |
| $n | n为整数,代表当前记录第n列的值 |
| NF | 表示当前记录的列数 |
| NR | 表示已经读入的记录数 |
| FILENAME | 表示正在处理的文本文件名 |
| FS | 列分隔符,默认是空格或制表符 |
| RS | 记录分隔数,默认是换行书 |
awk -f test.awk scores.txt
test.awk内容:
{
print
print "$0:",$0
print "$1:",$1#第一列内容
print "NF:",NF
print "NR:",NR
print "FILENAME:",FILENAME
}
结果:依次打印每条记录内容以及系统变量值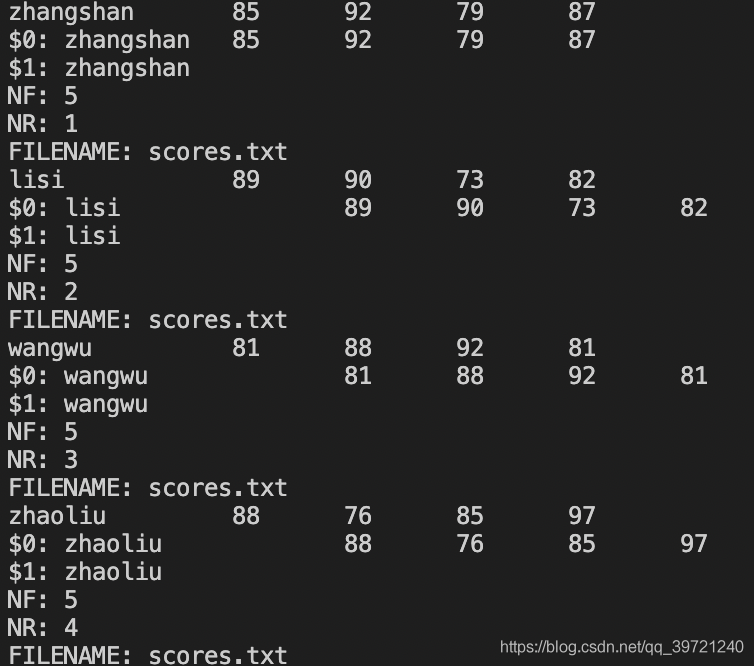
score.txt改成如下: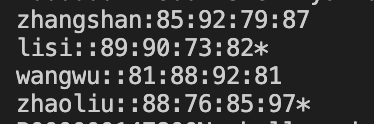
awk -f test.awk scores.txt
test.awk内容:
{
BEGIN{
RS="*"
FS=":"
}
$2>80 {
print
print "======"
}
结果:在BEGIN定义行分隔符为*,列分隔符为:。输出第二列大于80的记录。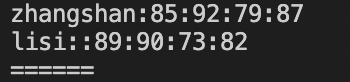
运算符:
1、算数运算符
| 运算符 | 含义 |
|---|---|
| + | 加法 |
| - | 减法 |
| * | 乘法 |
| / | 除法 |
| % | 取余 |
| ^ | 指数运算,几的几次方 |
2、赋值运算符
| 运算符 | 含义 |
|---|---|
| = | 赋值 |
| += | 前后两个数相加后,再赋值给前面的变量 |
| -= | 前后两个数相减后,再赋值给前面的变量 |
| *= | 前后两个数相乘后,再赋值给前面的变量 |
| /= | 前后两个数相除后,再赋值给前面的变量 |
| %= | 前后两个数取余后,再赋值给前面的变量 |
| ^= | 前后两个数指数运算后,再赋值给前面的变量 |
3、三目运算符
| 运算符 | 含义 |
|---|---|
| 表达式?值1:值2 | 当前面表达式成立时,取值1;否则取值2 |
4、逻辑运算符
| 运算符 | 含义 |
|---|---|
| && | 逻辑与 |
| || | 逻辑或 |
| ! | 逻辑非 |
5、关系运算符
| 运算符 | 含义 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| == | 等于 |
| != | 不等于 |
| ~ | 匹配运算符。$1~/^T/表示匹配第一个字段以T开头的记录 |
| !~ | 不匹配运算符 。$1!~/^T/表示匹配第一个字段不是以T开头的记录 |
函数:
1、index(string1,string2):返回字符串2在字符串1中出现的位置。
chmod +x test_awk.sh
./test_awk.sh
test_awk.sh内容:
#! /usr/bin/awk -f
#mac 解释器的位置如此,linux为/bin/awk
BEGIN {
i=index("Hello world","world")
print i
}
结果:![]()
2、length(string):返回字符串长度
3、match(string,regexp):在string中匹配符合正则表达式regexp的子串。返回值存在系统变量RSTART和RLENGTH中,前者代表子串在string中出现的位置,匹配不到则为0;后者代表匹配到的子串的长度,匹配不到则为-1。
chmod +x test_awk.sh
./test_awk.sh
test_awk.sh内容:
#! /usr/bin/awk -f
#mac 解释器的位置如此,linux为/bin/awk
BEGIN {
match("Hello world",/or/)
print RSTART, RLENGTH
}
结果:注意正则表达式的写法,用双斜线![]()
4、split(string,array,seperator):将string按照分隔符seperator切分,放在数组array中
chmod +x test_awk.sh
./test_awk.sh
test_awk.sh内容:
#! /usr/bin/awk -f
#mac 解释器的位置如此,linux为/bin/awk
BEGIN {
split("Hello world",result,/ /)
print result[1]
print result[2]
}
结果:将Hello world 按空格拆分。注意分隔符写法,用双斜线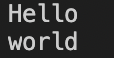
5、sub(regexp,replacement,string)和gsub(regexp,replacement,string):将string中符合正则表达式regexp的子串替换成目的内容replacement。区别是前者只替换第一次出现的子串,后者将所有子串均替换
chmod +x test_awk.sh
./test_awk.sh
test_awk.sh内容:
#! /usr/bin/awk -f
#mac 解释器的位置如此,linux为/bin/awk
BEGIN {
s="Hello world"
sub(/ /,",",s)
print s
}
结果:将空格替换成逗号。注意正则表达式写法,用双斜线
6、substr(string,start,length):从start位置开始截取string长度为length的子串。length可省略,表示截取到结尾
chmod +x test_awk.sh
./test_awk.sh
test_awk.sh内容:
#! /usr/bin/awk -f
#mac 解释器的位置如此,linux为/bin/awk
BEGIN {
s="Hello world"
res=substr(s,3,5)
print res
}
结果:![]()
7、算数函数:
| 函数 | 含义 |
|---|---|
| int(x) | 返回x的整数部分 |
| sqrt(x) | 求x的平方根 |
| exp(x) | 求e的x次方 |
| log(x) | 求以e为底x的对数 |
| sin(x) | x的正弦值 |
| cos(x) | x的余弦值 |
| rand() | 介于0和1之间的随机数 |
| srand(x) | 以x为种子的随机数 |
数组:
1、定义赋值以及取值:无需指定类型,在对数组第一个元素赋值时便会自动创建数组。同一个数组中可以存储不同类型的元素。支持关联数组,即索引为字符串的数组。
chmod +x test_awk.sh
./test_awk.sh
test_awk.sh内容:
#! /usr/bin/awk -f
#mac 解释器的位置如此,linux为/bin/awk
BEGIN {
arr[1]="one"
arr[2]=2
arr[4]=4.12
arr["five"]=5
print arr[1]
print arr[2]
print arr[3]
print arr[4]
print arr["five"]
}
结果:因为未定义索引3的值,所以输出空字符串。其中arr[“five”]即为关联数组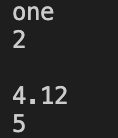
2、数组遍历
方式1:知道数组长度,且只能遍历到索引为整数的值
chmod +x test_awk.sh
./test_awk.sh
test_awk.sh内容:
#! /usr/bin/awk -f
#mac 解释器的位置如此,linux为/bin/awk
BEGIN {
arr[1]="one"
arr[2]=2
arr[4]=4.12
arr["five"]=5
len=length(arr)
for(i=1;i<=len;i++){
print arr[i]
}
}
结果:因为没有索引3的值,所以输出空字符串。且未遍历到索引为five的值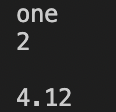
方式2:
chmod +x test_awk.sh
./test_awk.sh
test_awk.sh内容:
#! /usr/bin/awk -f
#mac 解释器的位置如此,linux为/bin/awk
BEGIN {
arr[1]="one"
arr[2]=2
arr[4]=4.12
arr["five"]=5
for(i in arr){
print arr[i]
}
}
结果:未赋值的索引不会遍历到,且可以遍历到索引为非整数的值。但是是无序的。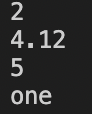
3、delete语句删除数组元素和in判断数组元素是否包含某个元素
chmod +x test_awk.sh
./test_awk.sh
test_awk.sh内容:
#! /usr/bin/awk -f
#mac 解释器的位置如此,linux为/bin/awk
BEGIN {
arr[1]="one"
arr[2]=2
arr[4]=4.12
arr["five"]=5
for(i in arr){
print arr[i]
}
print "------------"
delete arr[2]
for(i in arr){
print arr[i]
}
}
结果:
流程控制:
1、if语句:
chmod +x test_awk.sh
./test_awk.sh score.txt
test_awk.sh内容:
#! /usr/bin/awk -f
#mac 解释器的位置如此,linux为/bin/awk
{
if($3>=90){
print $1,"A"
}else{
if($3<90 && $3>=80){
print $1,"B"
}else{
print $1,"C"
}
}
}
结果: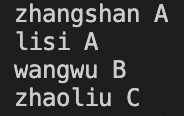
2、for语句:
chmod +x test_awk.sh
./test_awk.sh
test_awk.sh内容:
#! /usr/bin/awk -f
#mac 解释器的位置如此,linux为/bin/awk
BEGIN {
for(i=1;i<=9;i++){
for(j=1;j<=i;j++){
printf "%d*%d=%d\t",i,j,i*j
}
printf "\n"
}
}
结果: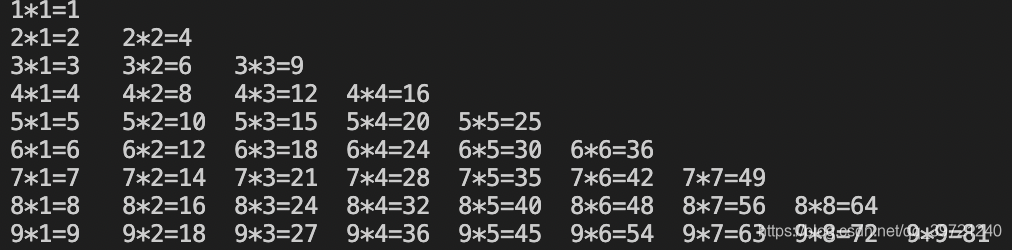
3、while语句:
chmod +x test_awk.sh
./test_awk.sh
test_awk.sh内容:
#! /usr/bin/awk -f
#mac 解释器的位置如此,linux为/bin/awk
BEGIN {
i=1
while(i<10){
print i^2
i++
}
}
结果: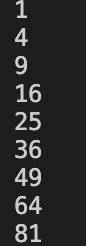
4、do while 语句:
chmod +x test_awk.sh
./test_awk.sh
test_awk.sh内容:
#! /usr/bin/awk -f
#mac 解释器的位置如此,linux为/bin/awk
BEGIN {
i=1
do{
print i^2
i++
}while(i<10)
}
结果同上面while语句
5、break 和 continue 语句:
chmod +x test_awk.sh
./test_awk.sh
test_awk.sh内容:
#! /usr/bin/awk -f
#mac 解释器的位置如此,linux为/bin/awk
BEGIN {
while(getline < "scores.txt" > 0){
if($1=="wangwu"){
break
}
print $1,$2+$3+$4+$5
}
}
结果:这里要说明的是getline函数,意思是在awk中从标准输入、管道或者文件中读取数据。按行读取,每读取一行NR,NF等系统变量都会更新。如果成功读到一条记录返回值为1,否则返回0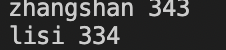
continue使用方法和break一致,区别是continue结束当前循环继续执行下一次循环;而break则是结束整个循环。
6、next语句
当awk程序遇到next语句时,则语句后面的所有动作命令以及其他匹配模式对应的动作命令都不会执行,接着读取下一条记录从头开始执行。相当于跳过当前记录剩下的所有操作。
chmod +x test_awk.sh
./test_awk.sh
test_awk.sh内容:
#! /usr/bin/awk -f
#mac 解释器的位置如此,linux为/bin/awk
/si/ {
next
}
{
print $1,$2+$3+$4+$5
}
结果:当匹配到si字符串时,便跳过该记录的后续所有操作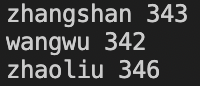
7、exit
退出整个awk程序,不多赘述
输出:
1、print string1,string2,… :输出string1,string2等字符串,多个字符串用逗号隔开。输出时各字符串自动会被空格隔开。每个print并且会自动追加换行符
2、printf(format,string1,string1,…):按照指定格式format输出string字符串。
| 描述符 | 含义 |
|---|---|
| %c | 表示ASCII字符 |
| %s | 表示字符串 |
| %d | 表示整数 |
| %% | 表示%本身 |
| %e | 表示浮点数 |
chmod +x test_awk.sh
./test_awk.sh scores.txt
test_awk.sh内容:
#! /usr/bin/awk -f
#mac 解释器的位置如此,linux为/bin/awk
{
printf("%s\t%d\t%d\t%d\t%d\t%d\n",$1,$2,$3,$4,$5,($2+$3+$4+$5))
}
结果:
3、sprintf(format,string1,string1,…):使用方式和printf差不多。但是该函数不会输出到屏幕,只是以字符串的形式返回
与shell交互:
1、通过管道:
chmod +x test_awk.sh
./test_awk.sh
test_awk.sh内容:
#! /usr/bin/awk -f
#mac 解释器的位置如此,linux为/bin/awk
BEGIN {
while("ls"|getline){
print $1
}
}
结果:返回目录下所有文件。通过管道|将命令ls所得到的结果传递给 getline函数(固定的)。再通过$1依次获取getline中的值并打印($1是因为ls所获取的每条记录都只有一列,要是返回值有多列并且想获取可以用$n)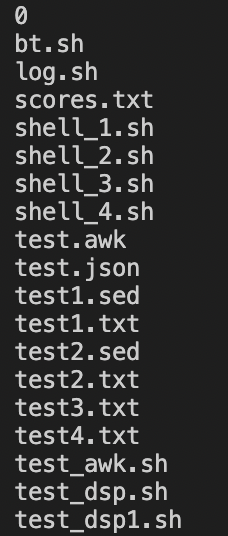
2、通过system函数:与管道相比,system函数不能直接从shell命令中获取数据,需要中介传递
chmod +x test_awk.sh
./test_awk.sh
test_awk.sh内容:
#! /usr/bin/awk -f
#mac 解释器的位置如此,linux为/bin/awk
BEGIN {
system("ls > files")
while(getline < "files" > 0){
print $1
}
}
结果:先通过system函数运行ls命令。因为无法直接传递数据,所以先将ls命令的结果重定向到文件files文件中;然后通过getline函数从files文件中读取内容(即getline < "files"部分),如果读到内容(即> 0部分),便通过$1获取该内容并打印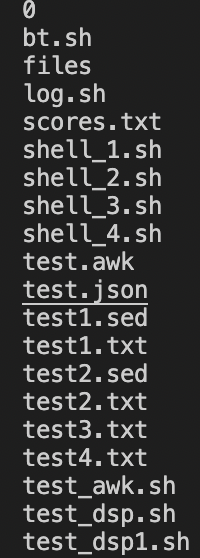
-------------------------------学习自“shell从入门到精通”--------------------------------------------