
机器学习算法与自然语言处理推荐
来源:网络整理
编辑:忆臻
【机器学习算法与自然语言处理导读】逻辑回归算法是最经典的几个机器学习算法之一,本文对它的优点,缺点进行总结。
1. 逻辑回归算法
逻辑回归属于判别式模型,同时伴有很多模型正则化的方法(L0, L1,L2,etc),而且你不必像在用朴素贝叶斯那样担心你的特征是否相关。与决策树、SVM相比,你还会得到一个不错的概率解释,你甚至可以轻松地利用新数据来更新模型(使用在线梯度下降算法-online gradient descent)。如果你需要一个概率架构(比如,简单地调节分类阈值,指明不确定性,或者是要获得置信区间),或者你希望以后将更多的训练数据快速整合到模型中去,那么使用它吧。
Sigmoid函数:表达式如下:
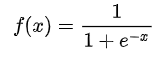
2. 优点
1. 实现简单,广泛的应用于工业问题上;
2. 分类时计算量非常小,速度很快,存储资源低;
3. 便利的观测样本概率分数;
4. 对逻辑回归而言,多重共线性并不是问题,它可以结合L2正则化来解决该问题;
5. 计算代价不高,易于理解和实现。
3. 缺点
1. 当特征空间很大时,逻辑回归的性能不是很好;
2. 容易欠拟合,一般准确度不太高;
3. 不能很好地处理大量多类特征或变量;
4. 只能处理两分类问题(在此基础上衍生出来的softmax可以用于多分类),且必须线性可分;
5. 对于非线性特征,需要进行转换。
4. logistic回归应用领域:
1. 用于二分类领域,可以得出概率值,适用于根据分类概率排名的领域,如搜索排名等;
2. Logistic回归的扩展softmax可以应用于多分类领域,如手写字识别等;
3. 信用评估;
4. 测量市场营销的成功度;
5. 预测某个产品的收益;
6. 特定的某天是否会发生地震。
5. logistic算法与其它算法比较
线性回归做分类因为考虑了所有样本点到分类决策面的距离,所以在两类数据分布不均匀的时候将导致误差非常大;LR和SVM克服了这个缺点,其中LR将所有数据采用sigmod函数进行了非线性映射,使得远离分类决策面的数据作用减弱;SVM直接去掉了远离分类决策面的数据,只考虑支持向量的影响。
但是对于这两种算法来说,在线性分类情况下,如果异常点较多无法剔除的话,LR中每个样本都是有贡献的,最大似然后会自动压制异常的贡献;SVM+软间隔对异常比较敏感,因为其训练只需要支持向量,有效样本本来就不高,一旦被干扰,预测结果难以预料。
推荐阅读:
推荐几个我关注的技术牛逼号
漫话:如何给女朋友解释为什么双11无法修改收货地址
2019 AI 国际顶级学术会议全在这里,请查收!
