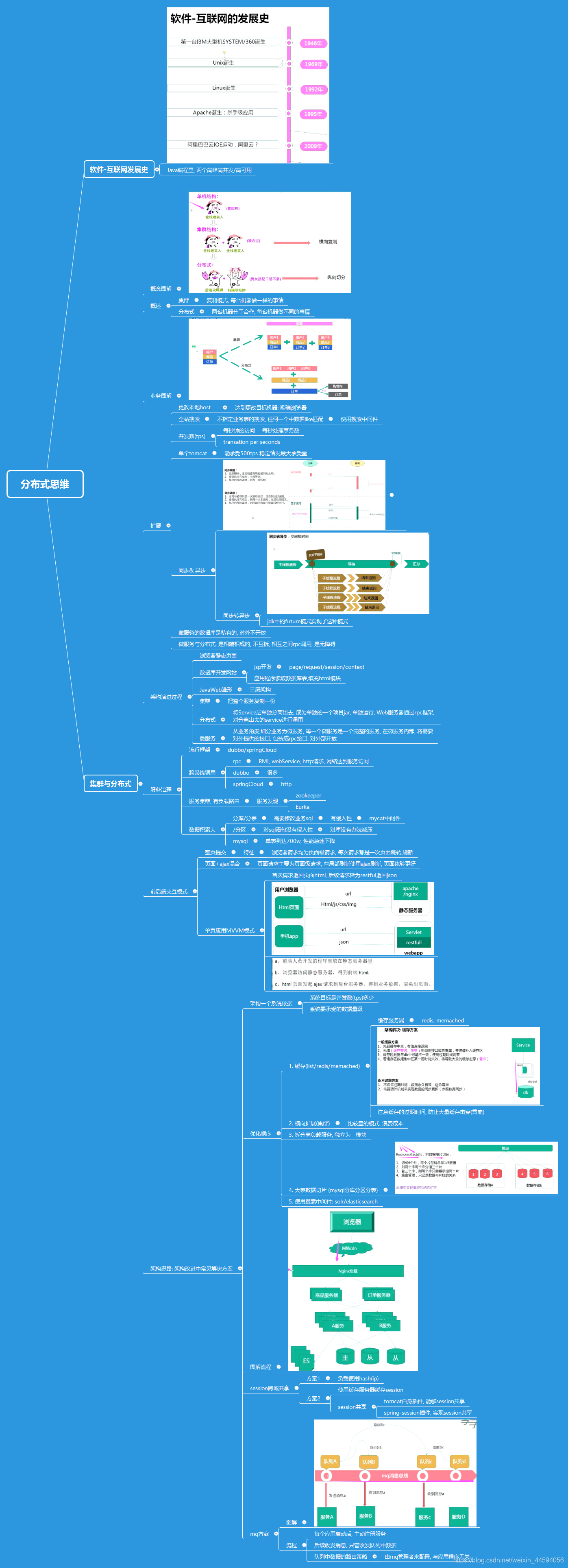
1. 软件-互联网发展史
1.1. 
1.2. Java编程里, 两个高峰->高并发/高可用
2. 集群与分布式
2.1. 概念图解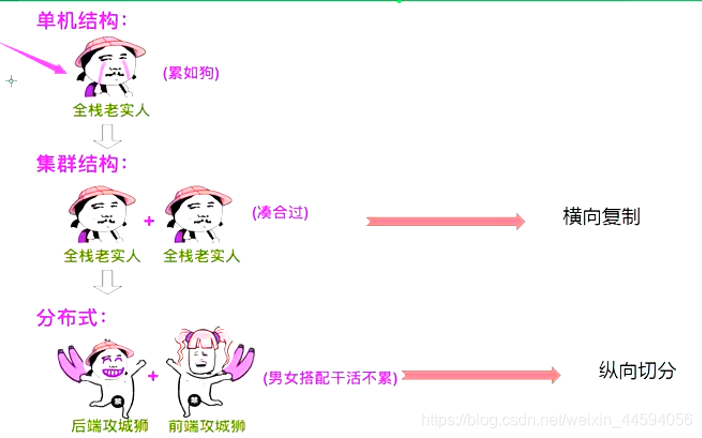
2.2. 概述
集群
复制模式, 每台机器做一样的事情
分布式
两台机器分工合作, 每台机器做不同的事情
2.3. 业务图解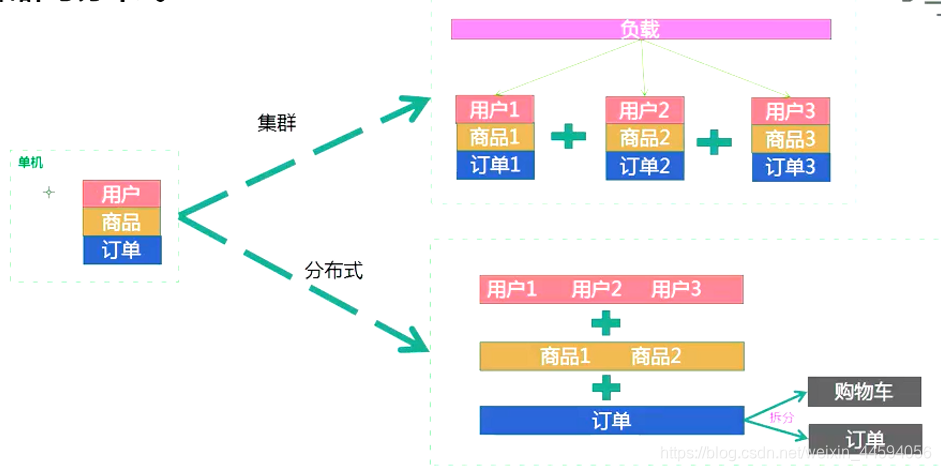
2.4. 扩展
1.更改本地host-> 达可到更改目标机器,欺骗浏览器
2.全站搜索 不指定业务表的搜索, 任何一个中数据like匹配 ->使用搜索中间件解决
3.并发数(tps /transation per seconds) -> 每秒钟的访问—每秒处理事务数
- 单个tomcat ,能承受500tps-> 在稳定情况最大承受量
2.5. 架构演进过程
浏览器静态页面
数据库开发网站->jsp开发 page/request/session/context, 应用程序读取数据库表,填充html模块
JavaWeb雏形 ->三层架构
集群->把整个服务复制一份
分布式
将Service层单独分离出去, 成为单独的一个项目jar, 单独运行, Web服务器通过rpc框架, 对分离出去的service进行调用
微服务
从业务角度,细分业务为微服务, 每一个微服务是一个完整的服务, 在微服务内部, 将需要对外提供的接口, 包装成rpc接口, 对外部开放
2.6. 服务治理
流行框架
- dubbo/springCloud
跨系统调用
- rpc,RMI, webService, http请求, 网络达到服务访问
服务集群
- 有负载路由
服务发现
- zookeeper
- Eurka
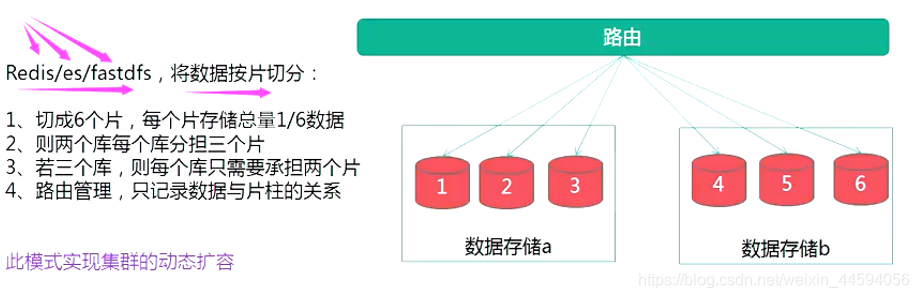
数据积累大
1.分库/分表
- 需要修改业务sql
- 有侵入性
- mycat中间件
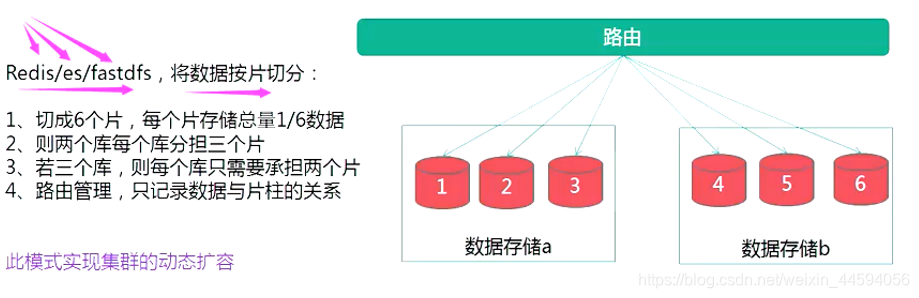
2.分区 - 对sql语句没有侵入性
- 对库没有办法减压(mysql单表到达700w, 性能急速下降)
2.7. 前后端交互模式
- 整页提交
特征
浏览器请求均为页面级请求, 每次请求都是一次页面跳转,刷新 - 页面+ajax混合
页面请求主要为页面级请求, 有局部刷新使用ajax刷新, 页面体验更好 - 单页应用MVVM模式
首次请求返回页面html, 后续请求皆为restful返回json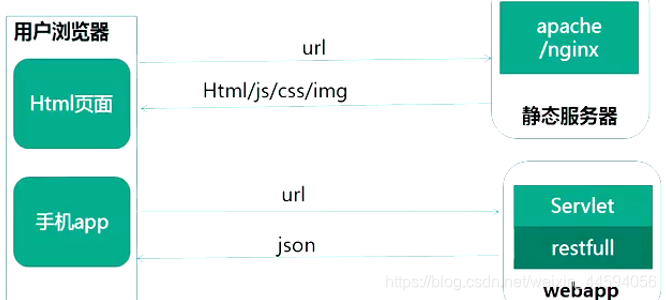
2.8. 架构思路: 架构改进中常见解决方案(重点)
架构一个系统依据
系统目标是并发数(tps)多少
系统要承受的数据量级
优化顺序
- 缓存(list/redis/memached)
缓存服务器
redis, memached
注意缓存的过期时间, 防止大量缓存击穿(雪崩)
- 横向扩展(集群)
比较重的模式, 浪费成本 - 拆分高负载服务, 独立为一模块
- 大表数据切片 (mysql分库分区分表)
- 使用搜索中间件: solr/elasticsearch
图解流程
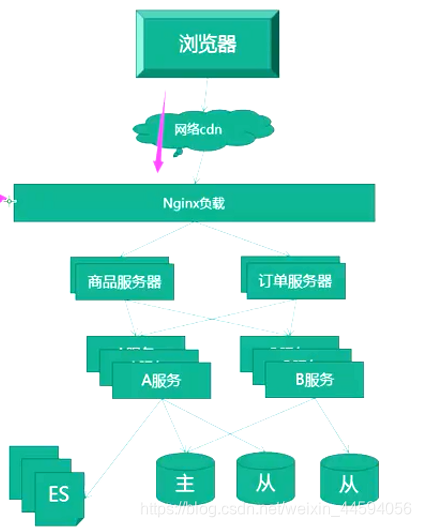
session跨域共享
方案1
负载使用hash(ip)
方案2
- 使用缓存服务器缓存session
session共享
tomcat自身插件, 能够session共享
spring-session插件, 实现session共享 - mq方案
图解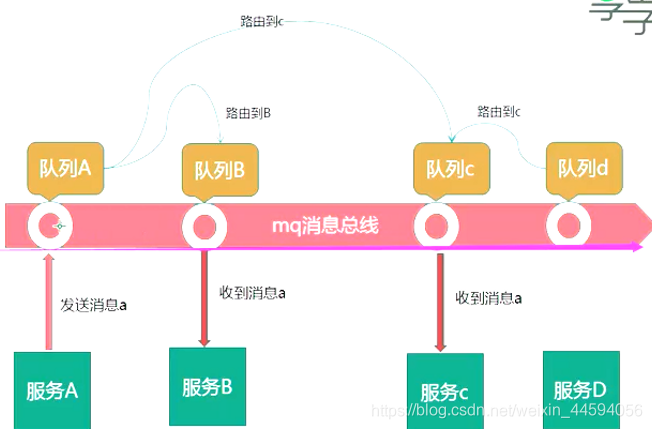
流程
1.每个应用启动后, 主动注册服务
2.后续收发消息, 只管收发队列中数据
3.队列中数据的路由策略(由mq管理者来配置, 与应用程序无关)
版权声明:本文为weixin_44594056原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。